

出品:具身释界
最近,自变量机器人发布了一篇新的技术报告:Wall-OSS-0.5 Technical Report: Pretrain Once, Act Anywhere。
这篇工作很有意思,因为它没有只把重点放在“微调之后模型有多强”,而是直接提出了一个更基础的问题:
一个 VLA 模型在大规模预训练之后,到底有没有真正学会机器人操作?还是说,它只是给下游 fine-tuning 提供了一个更好的初始化?
这其实是当前 VLA 领域一个很关键的问题。
过去我们看到很多 Vision-Language-Action 模型,都会先经过大规模机器人数据预训练,再在具体任务上 fine-tune,然后展示机器人成功完成任务的效果。但这样一来,就很难判断:模型的能力究竟来自预训练,还是来自下游任务数据?
自变量的 Wall-OSS-0.5 想把这个问题讲清楚。
它的核心观点可以概括成一句话:
VLA 预训练不应该只是一个初始化策略,而应该本身就能产生可测试、可执行的机器人能力。
换句话说,一个真正有意义的机器人 foundation model,不应该只有 fine-tuning 后才会动。它在预训练完成后,就应该已经具备一定的“直接上机器人执行任务”的能力。
Wall-OSS-0.5 是什么?
Wall-OSS-0.5 是自变量机器人团队发布的一个开源 4B VLA 模型。
它基于 Qwen2.5-VL-3B-Instruct 扩展而来,在原本的视觉语言模型基础上,加入了动作生成相关模块,使模型能够从图像、语言指令和机器人状态中输出动作。
论文标题里的 Pretrain Once, Act Anywhere 很直接:预训练一次,到处执行。
当然,这里的 “Act Anywhere” 并不是说模型已经可以无条件泛化到所有机器人和所有场景,而是强调一种新的目标:
VLA 预训练本身应该被当成一种可以直接产生机器人行为能力的训练过程,而不是只服务于下游微调。

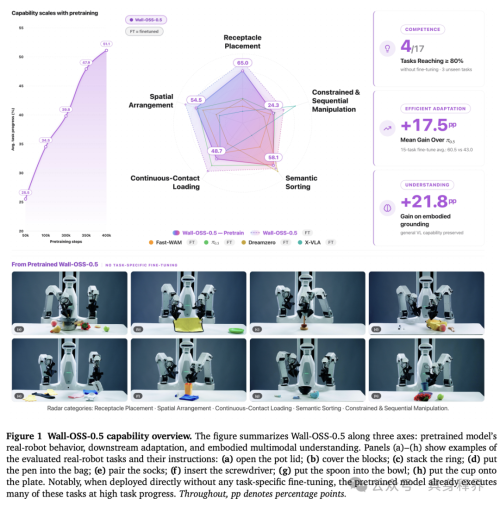
Figure 1 是这篇论文最适合放在开头的图。它从三个角度展示了 Wall-OSS-0.5 的能力:
第一,预训练模型本身已经可以在真实机器人上完成一些任务。
第二,经过 fine-tuning 后,它可以成为更强的下游适配基础。
第三,动作训练并没有明显破坏原来的视觉语言理解能力,反而增强了 embodied grounding,也就是更贴近具身场景的理解能力。
图下面还展示了多个真实机器人任务,比如打开锅盖、盖住积木、叠环、把笔放进袋子、配对袜子、插入螺丝刀、把勺子放进碗里、把杯子放到盘子上。
最值得注意的是:论文强调这些任务中,有一部分是在 没有任务特定 fine-tuning 的情况下,由预训练 checkpoint 直接完成的。
这就是这篇工作的重点。
为什么这篇论文要强调“预训练后直接测试”?
在语言模型和视觉语言模型里,我们通常会默认:一个 foundation model 预训练完成后,本身就应该能展示一些能力。
比如一个大语言模型预训练后,就应该能回答问题、理解指令、做一些推理。一个视觉语言模型预训练后,也应该能描述图片、回答视觉问题、做图文理解。
但是在机器人领域,情况没有那么清楚。
很多 VLA 模型虽然使用了大规模机器人数据预训练,但最终展示效果时,通常是在某个任务或某个 benchmark 上 fine-tune 之后再评估。
这就导致一个问题:
如果一个模型必须经过下游任务微调才能动起来,那它的预训练到底学到了什么?
Wall-OSS-0.5 的做法是:直接把预训练 checkpoint 放到真实机器人上测试。这样才能回答一个更本质的问题:
VLA 预训练本身,能不能产生可执行的机器人策略?
论文把这个目标称为 deployment-oriented VLA pretraining,也就是面向真实部署的 VLA 预训练。
这和过去很多只把预训练当成“初始化”的思路不太一样。它更接近大模型领域对 foundation model 的期待:预训练之后,模型应该已经具备一些可观察的基础能力。
方法核心:用离散动作当“梯度桥梁”,用连续动作真正执行
这篇论文最核心的方法叫:
Gradient-Bridged Co-Training
可以简单理解为:用一个“梯度桥梁”把 VLM 的理解能力和机器人动作能力连接起来。
为什么需要这个桥梁?
因为 VLA 训练里存在一个矛盾。
一方面,真实机器人执行动作时,最好输出连续动作。比如机械臂末端移动多少、旋转多少、夹爪开合多少,这些都是连续值。所以,像 flow matching 这样的连续动作生成方式,很适合作为最终部署时的动作接口。
但问题是:连续 flow matching 对 VLM backbone 的训练信号不够强。
另一方面,VLM 本来最熟悉的是 next-token prediction,也就是预测下一个 token。如果把机器人动作离散化成 action tokens,再用 cross-entropy 去训练,它就很符合 VLM 原来的训练方式,能把强梯度传回 backbone。
但问题是:离散动作 token 太粗,直接拿来控制机器人不够精细。
所以 Wall-OSS-0.5 的思路是:两个都要,但分工不同。
它同时训练三个目标:
1. Action-token Cross-Entropy 预测离散动作 token,用来强力更新 VLM backbone。它不是最终执行动作的接口,而是训练时的“梯度桥梁”。2. Multimodal Cross-Entropy 继续训练视觉语言任务,保持模型原本的图文理解、指令跟随和视觉 grounding 能力。3. Flow Matching 训练连续动作生成器,作为真实机器人部署时最终使用的动作输出方式。
可以这样理解:
离散动作 token 负责教“大脑”理解动作,连续 flow matching 负责让“身体”真正执行动作,多模态数据负责提醒模型不要忘记怎么看图、听指令和理解场景。

Figure 2 展示了 Wall-OSS-0.5 的整体训练结构。
图里有三条训练信号:
左边是 multimodal CE loss,用来保留视觉语言能力;
中间是 discrete action CE loss,也就是论文说的 gradient bridge;
右边是 continuous action FM loss,用来训练最终执行动作的连续动作头。
这张图最重要的地方在于:它不是简单把三个 loss 加在一起,而是让它们各司其职。
动作 token CE 负责把动作监督以 VLM 熟悉的形式传回 backbone;multimodal CE 负责稳定模型原本的视觉语言知识;flow matching 负责最终输出真实可执行的连续动作。
模型结构:VL Expert 和 Action Expert 分工合作
Wall-OSS-0.5 采用了 Mixture-of-Transformers, MoT 结构。
它把模型内部拆成两个 expert:
VL Expert:负责视觉、语言、proprioception,以及离散动作 token;
Action Expert:负责连续动作 token,用于 flow matching 动作生成。
这里容易误解的一点是:这不是把视觉语言和动作完全隔离开。
论文特别强调,这种设计是 routing decomposition,不是 gradient isolation。也就是说,两个 expert 虽然处理不同类型的信息,但是它们仍然共享 attention 上下文,梯度也可以端到端流动。
这样做的好处是:
Action Expert 在生成连续动作时,可以看到视觉和语言信息;而动作训练的信号,也可以反过来影响 VLM backbone,让原本的视觉语言模型逐渐变得 action-aware。
简单说就是:
VL Expert 更像理解世界的大脑,Action Expert 更像输出动作的执行系统,但两者之间不是断开的,而是可以互相影响。
Vision-Aligned RVQ Action Tokenizer:让动作 token 更有“语义”
为了训练离散动作 token,模型需要一个 action tokenizer,把连续动作转换成离散 token。
很多方法会使用比较规则化的 action tokenization,比如 FAST tokenizer。但 Wall-OSS-0.5 使用的是 Vision-Aligned RVQ Action Tokenizer。
这个 tokenizer 的重点不只是压缩动作,而是让动作 token 对 VLM 更友好、更有语义。

Figure 3 展示了这个 tokenizer 的结构。
它大致包含几个部分:
首先,模型输入 sparse multi-view video 和 action chunk。也就是说,它不是只看动作本身,而是结合了视觉上下文。
然后,action encoder 会把动作序列编码成 latent 表示,再通过 residual vector quantization,也就是 RVQ,把连续动作压缩成多层离散 token。
RVQ 的好处是可以分层表达动作:
前面的 codebook 可以表示比较粗的动作结构;
后面的 codebook 可以补充更细的残差信息。
最后,action decoder 再从这些 token 中重建 action chunk。
但这还不是全部。论文还加入了几个额外目标:
视觉-动作对齐,让动作 latent 更接近 VLM 的视觉特征;
未来上下文预测,让动作 token 不只是记录动作本身,还编码“这个动作会导致什么后果”;
DCT-domain reconstruction,用来抑制高频抖动,让动作更平滑。
所以这个 tokenizer 不是一个简单的动作压缩器,而是一个面向 VLM backbone 的“动作语义接口”。
换句话说,它要让模型不只是知道“动作数值是多少”,还要更容易理解“这个动作在当前视觉场景里意味着什么”。
Action-Space Supervision:为什么不直接监督 velocity?
Wall-OSS-0.5 的连续动作生成使用 flow matching。
普通 flow matching 通常学习一个 velocity field,也就是从噪声动作逐步变成干净动作的速度方向。但论文认为,机器人动作和图像不太一样。
图像里有丰富的高频细节,比如纹理、边缘、颜色变化;但机器人动作通常是低维、平滑的。真正重要的,不是高频抖动,而是整体轨迹形状。
比如机械臂要把杯子放到盘子上,关键不是每一帧动作都有复杂细节,而是整体轨迹要朝正确方向移动,接近目标,最后稳定放置。
所以论文提出 Action-Space Supervision:虽然网络仍然输出 velocity,但 loss 是定义在恢复出来的 action 上。
这样一来,模型会更重视 high-noise 阶段的全局轨迹恢复。因为在 high-noise 阶段,模型需要先把动作的大方向和整体形状恢复出来;而 low-noise 阶段更多是在做细节修正。
简单说就是:
机器人动作生成最重要的是先把轨迹“大形状”搞对,而不是一开始就纠结细小抖动。
这个设计也帮助模型提升了收敛速度和训练稳定性。
数据:不只是机器人轨迹,还有 embodied bridge data
Wall-OSS-0.5 的训练数据由三部分组成:
第一部分是自变量自己采集的机器人操作数据。
这些数据覆盖双臂桌面机器人、移动操作机器人,以及一些不绑定具体机器人形态的数据采集设备。
第二部分是开源多 embodiment 数据。
包括 RoboMIND、AgiBotWorld、DROID、Bridge v2、Fractal/Google Robot 等数据集,用来扩展机器人形态、场景和任务多样性。
第三部分是大规模多模态数据。
论文使用了约 90M 多模态样本,其中既有通用视觉语言数据,也有和具身任务相关的数据。

Figure 4 很适合用来解释 Wall-OSS-0.5 的数据规模和数据组成。
左边展示了动作轨迹数据的组成。整体上,自采集数据占比较大,开源数据也占了相当一部分。右边则展示了 embodiment composition,也就是不同机器人形态的覆盖情况。
这对 VLA 预训练很重要。因为如果训练数据只来自一种机械臂、一个相机视角、几个固定任务,模型很容易只学到某个具体 embodiment 的操作模式。
而 Wall-OSS-0.5 想要的是跨机器人、跨场景、跨任务的基础能力,所以需要多 embodiment 数据来支撑。
不过这篇论文里更值得关注的,其实是 embodied bridge data。

Figure 5 展示了 embodied bridge data 的构造方式。
所谓 embodied bridge data,就是从机器人动作轨迹中自动构造出来的多模态理解任务。它的作用是把“看图说话”和“机器人执行动作”连接起来。
比如同一段机器人轨迹,可以被转成不同类型的问题:
场景层面:描述当前桌面环境里有什么;
物体层面:定位某个物体的位置;
空间关系层面:判断两个物体是否在同一个盘子上;
任务层面:判断机器人当前在做什么,下一步应该做什么。
这类数据的意义在于,它不是普通互联网图文数据,而是直接来自机器人交互轨迹。因此,它天然和动作执行场景对齐。
简单理解:
机器人轨迹教模型怎么动,多模态数据教模型怎么看和理解,而 embodied bridge data 负责把“理解”和“动作”中间的桥补起来。
最关键实验:预训练模型不 fine-tune,真的能动吗?
这篇论文最重要的实验,是 zero-shot real-robot evaluation。
作者直接把预训练 checkpoint 放到真实机器人上,在 17 个任务上测试,不进行任务特定 fine-tuning。
这些任务包括:
语义理解任务;
刚体操作任务;
deformable object 操作任务;
精细操作任务;
长程多步操作任务。
评价指标不是简单的 success rate,而是 task progress。也就是说,即使机器人没有完全成功,也会根据它完成了多少中间步骤给分。
这个指标对评估 VLA 预训练很有意义。因为 foundation model 的早期能力可能不是“全成功或全失败”,而是会先表现出一些局部能力,比如能抓到物体、能移动到大概位置,但最后一步还不够精准。

Figure 6 展示了随着预训练步数增加,模型在 seen tasks 和 unseen tasks 上的表现变化。
可以看到,整体 task progress 从 50k checkpoint 的 25.5 提升到 400k checkpoint 的 51.1。
更有意思的是,unseen tasks 也从 24.2 提升到 53.6,甚至在 400k 时略高于 seen tasks 的 50.0。
当然,论文也强调,seen 和 unseen 任务本身不一定难度完全一致,所以不能简单理解成 unseen 就一定更强。但这个趋势说明:模型不是只记住训练任务模板,而是确实学到了一些可以迁移的操作能力。
在 400k checkpoint 上,Wall-OSS-0.5 的一些 zero-shot 任务表现非常突出:

几个代表性结果包括:
Block Sorting:100%
Fruit Sorting:96%
Ring Stacking:86%
Rope Tightening:82%
Cup Grasping:64%
Bean Pouring:60%
其中最值得关注的是 Rope Tightening。
这是一个 held-out deformable manipulation task,也就是没有在当前 embodiment 上以完全相同任务形式采集过的数据。它还能达到 82% task progress,说明模型不仅仅是在记忆某个具体任务,而是可能学到了一些更通用的操作模式。
不过,zero-shot 能力也有明显边界。
像 Towel Folding、Table Setting、Charger Plugging 这些任务表现就很低。原因也很直观:它们需要更精细的状态感知、更复杂的双手协作,或者更高精度的插入与对齐。仅靠预训练,还很难稳定完成。
所以这部分实验传达的信息不是“预训练已经解决了所有机器人任务”,而是:
VLA 预训练已经开始表现出真实可执行的机器人能力,但复杂精细任务仍然需要下游 fine-tuning。
Fine-tuning 后:Wall-OSS-0.5 比 π0.5 和 DreamZero 更强
接下来,论文比较了 fine-tuning 后的真实机器人表现。
作者选择了两个代表性 baseline:
π0.5:VLA 路线的机器人基础模型;
DreamZero:WAM,也就是 world-action model 路线的模型。
三个模型都使用各自官方预训练权重,然后在相同数据和相同协议下 fine-tune,并在 15 个真实机器人任务上评估。

结果很直接:
Wall-OSS-0.5 平均 task progress 达到 60.5%。 π0.5 是 43.0%。 DreamZero 是 33.4%。
在 manipulation 子集上,Wall-OSS-0.5 是 61.1%,π0.5 是 35.0%,DreamZero 是 33.7%。
在 reasoning 子集上,Wall-OSS-0.5 是 59.3%,π0.5 是 58.9%,二者接近,但 Wall-OSS-0.5 仍略高。
这说明 Wall-OSS-0.5 的优势主要体现在真实操作能力上,尤其是 manipulation tasks。
比如:
Color Block Sorting:Wall-OSS-0.5 96%,π0.5 42%;
Ring Stacking:Wall-OSS-0.5 91%,π0.5 60%;
Drawer Organization:Wall-OSS-0.5 52%,π0.5 7%;
Spoon-in-Bowl:Wall-OSS-0.5 80%,π0.5 43%。
这些任务覆盖了语义理解、中等精度放置、多步操作等不同能力。Wall-OSS-0.5 的提升说明,它的预训练不仅让模型 zero-shot 有了一定操作能力,也确实给下游 fine-tuning 提供了更好的基础。
任务越多,fine-tuning 反而越好?
论文还做了一个 multi-task fine-tuning scaling 实验。
它逐步增加 fine-tuning 的任务数量:
5 个任务;
10 个任务;
19 个任务。
直觉上,很多人可能会担心:任务变多以后,模型会不会互相干扰?比如原本某几个任务学得挺好,加入更多任务后反而被稀释。
但实验结果显示,在 Wall-OSS-0.5 里,任务扩展反而带来了更好的共享任务表现。

Figure 7 的结果可以这样理解:
在 5 个简单共享任务上,随着 fine-tuning 任务数从 5 增加到 10 再增加到 19,平均 task progress 从 73.96 提升到 83.75。
在 10 个共享任务上,从 10-task 到 19-task,平均 task progress 从 59.98 提升到 64.78。
新增的 9 个 OOD simple tasks,也达到了 65.59 的平均 task progress。
这说明,在当前模型容量和训练设置下,更多任务并没有明显造成负迁移,反而可能补充了更多可复用的细粒度能力。
比如一个任务里学到“抓取软物体边缘”,另一个任务里学到“把物体放入容器”,这些能力可能会在其他任务里被重新组合使用。
这也符合机器人 foundation model 的一个重要方向:
不是为每个任务单独训练一个 specialist,而是让模型在多任务、多场景中学习可复用的操作技能。
这篇论文真正想推动什么?
如果只看结果,Wall-OSS-0.5 是一个效果不错的开源 VLA 模型。
但如果从研究趋势上看,这篇论文更重要的地方在于:它重新定义了 VLA 预训练应该如何被评估。
过去我们常常问:
这个模型 fine-tune 之后成功率高不高?
而 Wall-OSS-0.5 更想问:
这个模型在预训练完成时,是否已经具备可执行的机器人能力?
这其实是一个很关键的转变。
因为如果 VLA 预训练只是一个初始化,那它和普通 supervised policy learning 的差别并没有那么本质。真正的 foundation model 应该像 LLM 和 VLM 一样,在预训练阶段就积累起某种通用能力。
对机器人来说,这种能力不是回答问题,而是:
能看懂场景;
能理解任务;
能把语言目标转成动作意图;
能在真实机器人上完成一定程度的操作;
能在下游任务中通过少量数据快速适配。
Wall-OSS-0.5 的实验说明,这条路已经开始出现一些可观察的结果。
当然,它还没有解决所有问题
不过,这篇论文也不是说 VLA 已经可以真正“预训练一次,到处通用”。
它仍然有一些明显限制。
首先,zero-shot 能力在简单语义任务和中等精度操作上比较明显,但在精细操作、复杂 deformable object 操作和长程任务上仍然不足。
比如折毛巾、插充电器、复杂桌面整理这类任务,仍然对状态感知、接触控制和动作精度要求很高。
其次,模型主要还是依赖当前输入观测,对长程记忆和持续状态追踪的支持还不够。如果任务需要机器人记住很久之前发生的事情,或者持续规划多个阶段,当前架构可能还不够。
第三,模型动作空间是固定设计的 26 维动作表示。对于灵巧手、多指操作、高自由度机器人等更复杂 embodiment,未来还需要进一步适配。
所以这篇论文的意义不是宣称“机器人通用智能已经完成”,而是给出了一个清晰信号:
VLA 预训练正在从“更好的初始化”走向“直接可测试的机器人基础能力”。
总结:从“预训练后再学”到“预训练后就能动”
Wall-OSS-0.5 这篇工作可以概括成三个关键词:
第一,直接测试预训练能力。 它把预训练 checkpoint 直接放到真实机器人上评估,而不是只看 fine-tuning 后的结果。
第二,用 gradient bridge 连接 VLM 和动作控制。 离散动作 token 负责把强训练信号传回 backbone,连续 flow matching 负责最终执行动作,多模态数据负责保留视觉语言理解能力。
第三,用大规模多 embodiment 数据和 embodied bridge data 打通理解与执行。 机器人轨迹教模型怎么动,多模态数据教模型怎么看,bridge data 则让“看懂”和“会动”之间有了更紧密的连接。
从这个角度看,Wall-OSS-0.5 不只是一个新的 VLA 模型,更像是在强调一种新的评估标准:
不要只问模型 fine-tune 之后能不能完成任务,也要问它在预训练之后到底学到了多少真实可执行的机器人能力。
这可能也是具身智能基础模型接下来很重要的方向。
如果说过去的 VLA 更像是在学习“看到图像和指令之后,该输出什么动作”,那么 Wall-OSS-0.5 想进一步证明:
当预训练规模足够大、训练目标设计得足够合理时,机器人操作能力本身也可以在预训练中逐渐涌现出来。
这也是标题里 “Pretrain Once, Act Anywhere” 最想表达的东西。
不是说机器人已经能去任何地方做任何事,而是说:
VLA 预训练,正在从一个初始化步骤,变成机器人真正获得基础操作能力的关键阶段。










