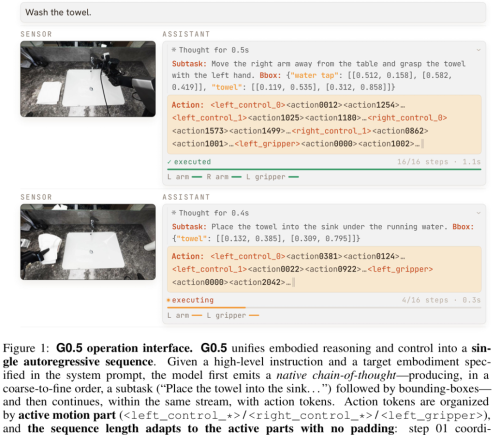
LabVLA:浙大与上海AI Lab联合探索科学具身智能,推动AI进入实验室
随着人工智能在科学领域的快速发展,大模型在认知层面上已经展现出强大能力,能够处理文献理解、进行科学推理并规划实验方案。然而,当研究工作实际进入科学实验室,面对烧杯、移液器、加热板与离心机等真实设备时,现有系统仍然难以把抽象的实验步骤转化为稳定且可泛化的具体操作行为。
这一鸿沟的出现,主要原因并非AI机器人能力不足,而是科学实验本身蕴含了大量隐性的操作知识以及流程结构,这些知识使得现有数据驱动方法难以对其进行有效的表达与学习。因此,现有实验室自动化系统往往仅停留在“流程执行器”的层面,而未能成为能够从实验知识中学习操作策略的智能系统。
浙江大学与上海人工智能实验室联合推出了LabVLA项目。该项目所提出的是一种旨在探索更具泛化能力的科学具身智能范式。它通过将视觉-语言-动作(Vision-Language-Action, VLA)预训练引入科学实验场景,从而使模型能够以自然语言的实验描述为起点,学习跨任务、不止于执行单一固定流程的实验操作规律。
为支撑这一目标,团队搭建了知识增强的仿真数据引擎RoboGenesis以及科学具身语料LabEmbodied-Data,帮助模型得以在大规模、多样化的实验模拟环境当中习得操作先验知识。在科学实验具身操作基准LabUtopia上,LabVLA在ID与OOD两种设置下分别获得了71.1%与70.0%的平均成功率,同时也在Franka真实机器人平台上开展了真机验证实验。
论文地址:https://arxiv.org/pdf/2606.13578
项目地址:https://zjunlp.github.io/LabVLA/

模型地址:https://huggingface.co/zjunlp/LabVLA
代码地址:https://github.com/zjunlp/LabVLA
AI走进科学实验室:从思考能力到动手能力之间还存在哪些缺失环节?
过去几年,人工智能在科学领域主要取得了进展,其范围主要集中在认知层面。无论是蛋白质结构预测、科学文献理解,还是材料发现,模型所处理的对象大体上为文本、序列、图结构或数值信息。因此,它们所擅长的任务是「理解知识」,但并不直接地面对实验室里的物理世界。
为了让人工智能真正跻身于科学研究的得力助手之列,仅仅具备深度的认知与推理能力是远远不够的,它还需要拥有稳健且灵活的物理交互能力。在近年来,自动化实验平台,或者常被称为自主实验室,在材料科学、化学合成以及生物实验等诸多领域取得了若干显著的进展。这些平台借助机械臂、高通量自动化仪器与智能优化算法,实现了对复杂实验流程的自动执行与迭代优化。然而,现有的这类系统大多仍是面向特定实验任务进行专门设计的,它们往往依赖于固定的硬件设备配置和预先定义好的刚性工作流。因此,尽管它们在处理特定类型的大规模实验时表现得相当高效,但在面对不同任务、不同设备以及不同实验环境时,却普遍缺乏进行泛化的鲁棒能力。
与此同时,通用机器人领域中的VLA模型在诸如家庭与工业等场景中,已经展现出了相当不错的操作能力。然而,科学实验室场景却呈现出明显不同的特点,其中包括透明液体处理、精密仪器操作、严格流程执行、复杂安全约束以及大量专业动作,例如倒液、加热、按压、转运和器皿摆放。因此,通用机器人模型如果未经针对性训练,往往难以直接适配这样的环境。
科学实验的本质远不止于对既定动作的机械执行,它实质上是一种受到深厚科学理论知识约束的具身策略学习过程。LabVLA项目致力于构建连接人工智能在科学领域的推理能力与具身智能体实际操作能力之间的桥梁,从而让实验操作本身能够获得超越特定任务与环境的广泛泛化能力。
RoboGenesis:把实验流程变成可规模化的数据
在当前阶段,现有的仿真数据由于普遍缺乏对科学过程的内在约束,因而难以有效表达实验操作中所蕴含的隐式操作逻辑。而为了获取真实数据,科学实验室机器人面临着数据采集成本高昂、数据集覆盖范围有限以及对采集环境高度依赖等一系列挑战:这不仅需要配置专业的实验设备与高精度的传感器,并依赖领域专家的深度参与及建立严格的安全保障机制,而且也很难对开放且复杂的实验场景实现有效的覆盖。
针对这一问题,团队所提出的知识增强仿真数据引擎RoboGenesis,通过对科学原理、实验规范与操作逻辑进行编码并将其嵌入可编程仿真环境当中,成功实现了从「依赖人工示教的数据采集」向「依托科学知识的自动化经验生成」这一关键转变。RoboGenesis致力于构建起科学知识与机器人行为之间的桥梁,使得实验知识得以沉淀为可执行、可复用且可迁移的具身经验,进而为科学具身智能的发展提供了一种新的数据范式。
知识增强科学具身数据合成
RoboGenesis 的思路可以概括为三步。

第一步工作是完成实验空间的构建。系统会先依据文本描述生成参考图像,再借助三维重建技术与物理标注手段,自动地生成可用于训练的实验室场景资产,进而把不同场景批量组合成多样的实验环境。
第二步主要涉及实验工作流的生成。当接收到一条自然语言指令时——例如「将液体从烧杯 A 转移到烧杯 B 并加热」——系统首先会对该指令进行分析,并将其拆解为多个原子技能,随后在不同的机器人平台上实例化执行。与此同时,系统会对场景、相机、光照、杂物、物体以及空间关系等多个方面进行随机化处理,以此来提升模型的泛化能力。
第三步是结构化经验沉淀。团队会对这一阶段生成的轨迹数据开展一致性验证与执行筛选工作,从而保证所获数据的质量,并为其附带任务步骤、物体状态、相机参数、空间关系等多类标注,最终形成LabEmbodied-Data数据集。这意味着,实验流程不再仅仅是一系列的「演示视频」,而是转变成了可直接用于模型训练的高质量监督信号。
从方法层面看,RoboGenesis的意义并不局限于数据的生成,而是尝试将实验室当中原本以隐性形式存在的操作经验,成功转化为具备可复用、可扩展以及可迁移特性的结构化训练资源。
LabVLA:构建起从视觉理解到动作生成的统一科学实验操作模型
在模型架构设计上,LabVLA 选用了开源的大规模模型作为视觉语言理解的骨干网络,并配备了专门的动作专家模块来负责输出连续的控制信号。其训练过程被明确地规划为两个阶段。
于预训练阶段,模型将率先于多个公开机器人数据源上,对离散动作 token 预测任务展开学习,从而使视觉与语言前缀部分形成对「动作语义」的初步认知。
在后训练阶段,模型接入了动作专家模块,并基于更贴近实验室场景的数据开展了连续动作学习,同时引入了「知识隔离」这一机制,以尽可能地避免动作学习过程对原有视觉语言能力产生干扰。换句话说,模型既要掌握「如何行动」,也要尽可能地保持「如何观察与理解」的能力。
在 LabUtopia 上表现如何?
LabVLA 在 LabUtopia 仿真环境进行实验验证

在六类典型实验室任务场景中,LabVLA涵盖了拾取、按钮操作、开门、倒液、加热以及运输等多种常见的操作动作。实验评测结果表明,LabVLA在ID与OOD两种设置下均获得了最优的性能表现,平均成功率分别能够达到71.1%与70.0%。
更重要的是,此结论并非仅适用于单一的实验配置。团队进一步使用LabEmbodied-Data数据集对其他具身模型进行微调,所得结果显示该数据集对外部模型同样能够带来显著的性能提升。这表明,该数据资产本身具备较强的通用性与可迁移性,其有效性并不完全依赖于某一特定的模型架构。
真机实验
为了验证模型在真实世界中的实际表现能力,团队将LabVLA部署到了真实的Franka机械臂平台上,并同时与DreamZero以及π0.5等具有代表性的机器人模型展开了性能对比。该实验涵盖了四类典型的实验室操作任务,具体包括了液体摇晃、液体倾倒、磁力搅拌以及漏斗插拔操作,从而全面覆盖了诸如抓取、放置、倾倒、按压与器皿操作等多项基础性的实验技能。对于每一项任务,研究团队都收集了五十条数据,并且对目标物体的位置以及最终的放置区域实施了随机扰动处理,以此来评估该模型在真实环境条件下的泛化能力。
实验从两个方面设置了测试场景,具体包括:目标位置是否超出训练分布的范围,以及工作空间是否存在杂乱物体。在大多数实验条件下,LabVLA取得了超过70%的任务成功率,这一结果表明,基于仿真的预训练所习得的能力,能够有效地迁移并应用到真实的物理实验环境之中。

从整体性能表现的角度进行考量,LabVLA与DreamZero两者基本处于持平状态,并未展现出显著的差异性;然而,在一些设定条件更为严苛、更考验模型泛化能力的场景中,LabVLA则展现出一定的优势。例如,在物体位置分布位于训练数据范围之外的洁净环境设置里,LabVLA所达到的平均成功率为80%,这一数值要高于DreamZero。另外,在涉及最长操作时序的漏斗插拔任务中,LabVLA同样取得了最佳的表现结果。实验数据还进一步揭示出,液体倾倒任务对于操作位置的偏移以及外部环境的干扰表现出最高的敏感度,而涉及多个步骤的复杂器皿操作任务,则对模型所具备的长程规划能力提出了更为严格的要求。综合以上分析可以得出,这些实验结果为LabVLA能够较好地完成从仿真环境到真实实验室场景的迁移提供了有力的实验验证,同时也初步展示了其作为一种面向科学领域的具身智能体所蕴含的发展潜力。
基于上述工作思路,团队当前正在积极探索将LabVLA所具备的科学具身能力应用于浙江大学、复旦大学以及晶泰科技等真实科学场景,着重探索其在合成生物、药物发现以及分子材料等多个实际应用场景中的应用。其更为重要的意义在于,可以在一定程度上替代研究人员直接进入那些具有较高危险性或重复性极强的实验操作环节,从而有效减少研究人员暴露在有毒、易燃或高温高压等不利实验条件下的风险,同时也能够显著提升实验操作过程的一致性与最终结果的可重复性。
面向科学具身的一点思考
如果仅仅着眼于实验所呈现的量化指标,LabVLA 仅仅展示了一个具身模型的性能结果;然而,如果将其置于 AI for Science 的整体框架之下进行审视,它更实质上是一次面向科学实验操作的基础设施探索。
首先,它将长期缺乏形式化表达的「实验室操作」过程,从经验性流程成功地转化为一个可建模、可学习且可评估的具身学习问题,从而使得科学实验操作获得了能够被算法系统化处理的能力。
其次,该项目成功构建了一条从仿真数据生成、任务结构分解、动作策略学习直至真实机器人验证的完整技术路径,从而实现了将科学具身智能从单点任务优化模式推进到端到端闭环建模的跃升。这种闭环建模的模式对于科学应用场景而言显得尤为关键,这是因为真实世界的科研应用往往更加依赖于跨环境、跨设备的连续泛化能力,而并非仅仅依赖于孤立且静态的任务表现。
在此基础上,这项工作也对当前 AI 在实验室环境中所扮演角色的能力边界进行了探讨。LabVLA 目前更接近于一个能够初步执行既定科学流程的技术员,而并非能够自主设计实验方案并依据实时结果动态调整策略的研究者。对这一能力边界的清晰界定,能够为后续发展出真正意义上的 AI 科学助手,提供更为明确的演进方向。
真实实验数据的稀缺状况,依然构成了制约科学具身智能发展的关键性制约因素之一。团队期望借助公开模型、代码以及数据资源的开放共享,能够有效降低相关领域的研究门槛,进而推动科学具身智能从当前的概念验证阶段,稳步迈向更广泛的真实世界科研应用场景。
结语:从技术员的身份转变为科学家的角色,依旧需要经历一个漫长的发展过程。
长期以来,人工智能在科学领域的应用,其精力主要倾注于认知层面的突破与进展,而实验环节——这个连接科学假设与经验证据的关键过程——依然在很大程度上依赖于人工操作。LabVLA项目所致力于探索的方向,并非旨在让人工智能直接取代人类科学家的角色,而是旨在为其赋予理解实验流程并执行实验操作的能力,从而使其得以作为科研人员的协作伙伴,深度参与到科学发现的整体进程之中。
然而,在追求构建真正通用的科学具身智能这一目标的道路上,研究者们依然面临着诸多亟待解决的挑战。例如,实验室所使用的设备种类本身就极为繁多,相关的操作规范与标准也存在着显著的差异。与此同时,真实实验环境中可能出现的误差累积效应、严格的安全约束条件以及各种环境扰动因素,其复杂程度也远远超出了仿真的范畴。此外,获取高质量的实验数据通常伴随着高昂的成本,而实现不同实验场景之间知识与技能的有效迁移,目前其能力仍然十分有限。因此,就目前的发展阶段而言,LabVLA项目更多地是在特定类型的实验任务上开展了一次初步的探索与尝试。它距离成为一个能够自主适应开放且复杂的实验环境,并有能力完成跨学科科学研究的通用实验智能体,目前看来仍有相当长的一段发展道路要走。
从抽象的知识理解迈向具体的物理交互,从虚拟的仿真学习走进真实的实验验证,科学具身智能正沿着这条清晰的路径,为AI for Science开启了一扇崭新的大门。
来源:LabVLA:当AI走进科学实验室,浙大x上海 AI Lab联合探索科学具身智能 | 具身研习社