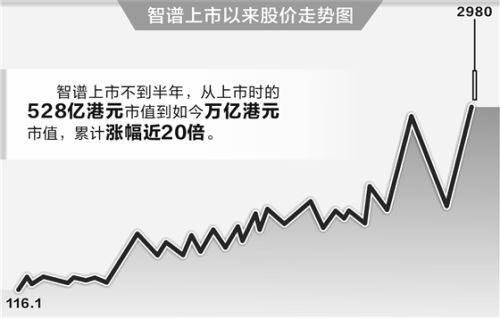
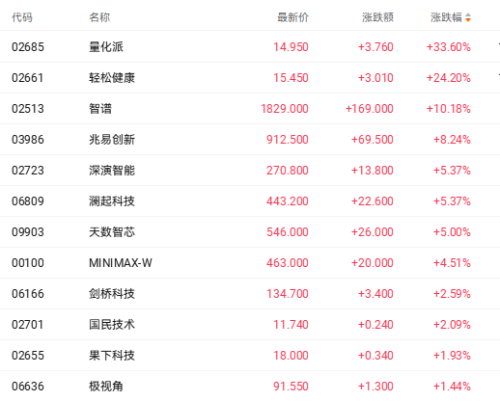
智谱凭GLM-5.2押注长上下文与国产算力生态跻身全球大模型头部阵营
《科创板日报》在6月17日,由记者李明明进行报道,智谱于同日发布并开源了新一代的旗舰大模型GLM-5.2。
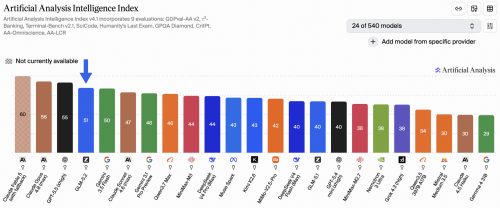
在Artificial Analysis综合榜单上,GLM-5.2模型获得了51分的综合评分,这一成绩使其在开源模型类别中位列当前最佳水平。
智谱方面向《科创板日报》记者进行了说明,这是他们迄今为止所发布的功能最为强大的开源模型。其核心开发工作主要围绕两个关键目标展开:具体而言,第一,是将1M token的上下文窗口从理论上的“纸面参数”成功转化为了具备“生产可用”状态的能力;第二,则是将模型的长程代码生成与理解能力向前推进了一个层级。
《科创板日报》记者随即对GLM-5.2 Max开展了持续数小时的连续实测。该测试覆盖了长上下文检索与生成、基于Long Horizon长程Agent进行编码,以及一次性完成近百万token复合型行业调研全链路交付等关键场景。
智谱方面阐述了,GLM-5.2的核心突破主要体现在,成功地将百万级Token的上下文窗口从理论规格转化为了实际可用的工程能力。
例如,该模型能够在单次连续的任务执行过程中,对超过88万token的数据量进行处理,并且能够独立自主地完成从软件开发、接口联调、功能测试直至打包部署上线的全链条软件交付流程,从而在数小时之内便能生成一个同时覆盖网页端、移动端与小程序的完整应用程序。而这一工作量在传统模式下,通常需要由一个开发团队协作数周才能完成。
当前,具备百万级上下文窗口能力的模型已不罕见,但一个业内公认的现象是,许多模型在处理超过30万token后,就会开始丢失关键信息,其在长文本场景下的推理质量会出现显著下滑。智谱提出的技术方案,主要涉及的是在注意力结构层面的一系列创新,具体而言,该方案结合了KV8量化、LayerSplit、IndexShare 4以及HiSparse稀疏注意力机制。
从工程实现的角度审视,这组技术改动的目标十分明确:在1M token的上下文长度条件下,同步实现对效果衰减程度以及推理成本的双重压降。根据智谱官方所披露的数据显示,在1M上下文长度的配置下,单位token所消耗的FLOPs被降低至2.9倍,这意味着与传统处理方案相比,计算量实现了约66%的削减幅度。
智谱在技术博客中分享了这款模型的一项惊人表现:它一次性交付了覆盖网页端、移动端与小程序的完整应用程序,整个开发过程处理了多达88万tokens的上下文,几乎耗尽了其百万级的窗口容量。这标志着在面对真实世界的超长周期复杂工程任务时,该模型能够全程稳定地维持项目记忆与逻辑连贯——它不会像许多模型那样,在经过数轮交互后,便开始遗忘早期对话中确立的核心约束与需求。
《科创板日报》的记者也对GLM-5.2进行了实际测试。该测试任务要求模型依靠大量公开素材来完成一项关于K12在线编程教育领域的竞品深度调研工作。在横向维度上,需要对赛道内15家主流品牌实现全面覆盖,并对课程、师资、定价以及家长评价这四大核心维度进行逐一拆解分析。最终需要一次性交付带有溯源索引的XLSX数据库、共计20页的PDF完整分析报告、6张可视化对比图表以及可复用的数据处理脚本等全套成果。
经过约半小时的持续处理,模型最终成功保留了全部804条家长评价数据,输出了包含12个数据分表的标准化Excel文件、完整的行业分析报告以及可执行的脚本代码,整个测试过程中未出现品牌混淆、数据维度丢失或统计口径错乱等长文本模型普遍存在的问题。不过在1M上下文这一极端应用场景下,该模型仍存在进一步优化的空间。
为进一步验证模型在深度分析与研究层面的综合能力,《科创板日报》记者又下达了一项实测指令:以国家统计局及可公开核验的宏观数据为基础,对2018年至2024年期间中国县域消费升级的趋势进行系统化研究,要求构建一个覆盖200余个县域的可溯源数据库,并最终交付完整的数据底表、研究报告、汇报演示文稿以及配套的可视化图表。
实际测试的结果显示,GLM-5.2 Max模型在实际测试中展示出,其具备在单轮交互中处理近百万条宏观统计素材的能力,并能一次性完成涵盖全国四百余县域的量化数据库构建、深度分析报告撰写,以及成套可视化图表制作的全链路交付工作。该能力使其能够很好地适配金融咨询级别的长周期大数据研究任务。


那么,应当怎样在全球顶尖模型的范畴内对GLM-5.2的编程能力进行定位?
北京计算机学会人工智能专业委员会秘书长、北京大学特聘研究员张有鱼在接受《科创板日报》记者采访时阐述了这样的观点:智谱GLM-5.2模型的发布,标志着国产大语言模型在编程这一特定细分场景上取得了关键性的突破。
在行业格局方面,GLM-5.2凭借在全球编程基准测试中取得的实测成绩以及性价比优势,在长上下文编程这一特定场景下展现出了显著的竞争力,从而对原有的双寡头垄断态势形成了有效冲击,推动市场朝着智谱、OpenAI以及Anthropic三方并立的全新竞争格局演进。
其次,虽然该模型未能在全维度上实现超越,但在目前多数中高频的实际开发场景方面,该模型已经完全能够作为海外头部模型的替代方案。 “但是,核心短板仍然存在,在深度的数理逻辑推理以及跨领域知识的复杂融合方面,GLM-5.2与海外最顶尖水平相比较仍然存在一定的技术代差,这是下一步需要重点攻坚的方向。”
国产算力Day 0适配
在纯粹的性能优势之外,GLM-5.2选择以极为宽松的MIT开源协议将其开源发布,这使得该模型可以被完全免费地用于各类商业应用场景。并且,在其模型训练与线上的推理服务部署这两个关键环节,都成功地避免了对海外算力资源的依赖。
在产品上线的首日,GLM-5.2的线上推理服务便迅速完成了与八大国产算力平台的推理适配工作。这一“开源国产模型与国产算力相结合”的模式,因其重要的协同意义而受到了业界的广泛关注。
智谱方面向《科创板日报》记者进行了说明,预计在下半年昇腾950超节点上市之后,将会成为GLM-5.2的重要算力底座。
“Day 0适配”并非仅指模型“能够在国产芯片上运行”,而是意味着在模型发布的当天,便已针对国产算力平台完成了深度推理适配以及算子级别的优化工作。这一实践表明,国产芯片在生态中并非作为“备选项”存在,而是被确立为与海外算力平台具备同等重要地位的第一梯队基础底座。
智谱的适配名单覆盖了国产算力领域的头部企业:华为昇腾、寒武纪、摩尔线程、海光、壁仞、沐曦、昆仑芯以及平头哥。这样做的目的既是为了分散供应链风险,也是为了能够最大化触达不同行业在国产化替代方面的需求。
从商业运营的逻辑进行审视,目前,国内专注于大模型开发的科技公司在其算力成本的构成当中,GPU的采购与租赁费用在其中占据了相当大的比重,并且这一部分需求高度依赖于英伟达H100及H200等海外厂商所生产的高端芯片。然而,随着中美两国在科技领域的博弈态势呈现出持续升级的局面,确保算力供应链的自主与可控,其性质已经从原先属于企业层面的“战略储备”选项,切实转变为了关乎生存与发展的“必需条件”。
从开发者视角审视,国产算力适配所代表的意义主要涵盖两个方面:其一,企业用户能够在纯国产计算环境中实现GLM-5.2模型的私有化部署,从而满足数据安全与合规性的要求;其二,当海外算力供应出现不稳定波动时,国产替代方案已经完成了充分准备,无需再从零开始进行适配。
从技术角度看,在多个架构差异显著的国产芯片上完成推理适配,这要求模型在算子兼容性、内存管理及推理效率方面开展大量工程调优。智谱能够实现Day 0同步适配,表明其底层工程团队在异构计算方面已有深厚积累。
来源:押注长上下文与国产算力生态 智谱凭GLM-5.2跻身全球大模型头部阵营? | 财联社