中国大模型何时能达到Fable级别?马斯克预计明年Q1,唐杰称不用那么久
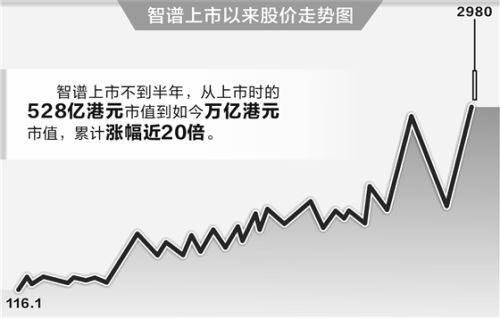
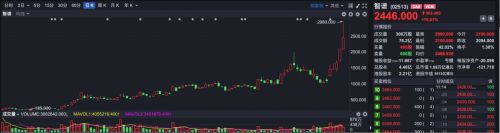
财联社6月19日讯(编辑 潇湘) 本周,全球人工智能领域最引人关注的事件,无疑是智谱于周三正式发布并开源了其新一代旗舰大模型GLM-5.2。该模型运用了MoE稀疏混合专家架构,其模型总参数量达到了744B,而在推理过程中实际激活的参数量约为40B,并具备处理长度达1M tokens的超长上下文的能力。
在Artificial Analysis综合榜单上,GLM-5.2获得了51分的成绩,这一分数使其在所有可用模型中排名靠前,其表现与Claude Opus 4.8相当,并且在全球开源模型中位居首位。
伴随着GLM-5.2的正式发布,与此同时,此前Anthropic的前沿模型意外遭遇美国出口管制禁令,一场围绕中美大模型“追赶时间表”的公开辩论,因此在海外社交媒体平台上引发了激烈的讨论,甚至引起了全球首富马斯克以及智谱创始人唐杰的参与。
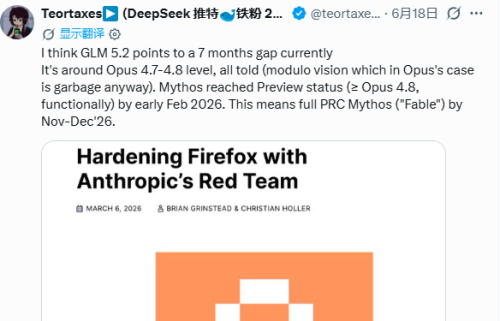
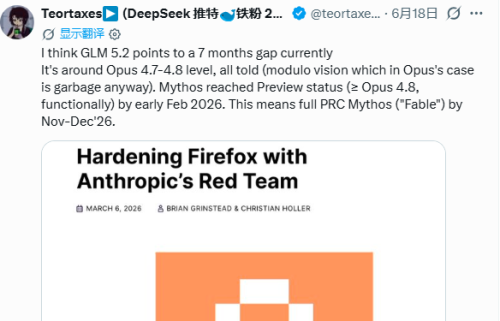
6月18日,一名X平台用户向独立AI研究员Teortaxes提出了一个核心疑问:"中国的大模型何时能够达到Anthropic'Fable'级别的能力水平?"
Fable 5 represents the most powerful model that Anthropic has made publicly available to date, having attracted widespread attention for its strong capabilities in long-duration task processing and code engineering. It belongs to the Mythos family of models, which was previously only open to a select few safety agencies, critical infrastructure companies, and trusted researchers. This model exhibits exceptional ability in the domain of cybersecurity; it can help defenders locate software vulnerabilities, but it may also be used to lower the cost of attacks for adversaries. Earlier this month, the US government, out of national security concerns, requested to suspend foreign entities' access to Fable 5 and Mythos 5.
Teortaxes在其分析中指出,如果暂时将视觉功能排除在考量范围之外,GLM-5.2当前的整体能力已达到并稳定于Opus 4.7至4.8的水平区间。考虑到Mythos在2026年2月初达到并稳定于功能上至少达到Opus 4.8水平的预览版本状态,基于此推算,中国模型达到完整Fable级别能力的时间窗口,可能在今年的11月至12月期间出现。
相比之下,马斯克做出的预判则显得相对保守。他给出的预判是,时间点可能要到明年第一季度(Probably Q1)。
马斯克在一则回复中指出,如果在基准测试的层面上进行追赶,中国大模型的进展或许相对容易;但如果以“真实实用性”作为标准来衡量时,那么明年第一季度能够追上,便已经是一项相当令人瞩目的成就了。
值得关注的是,作为这场讨论的核心人物,智谱创始人唐杰本人的回应则更为直接,他表示这一过程“不会需要那么久”。
这一表态实际上表明,中国的头部AI团队对于自身技术迭代的速度,拥有着强烈的信心。

在智谱方面于本周早些时候向《科创板日报》记者所做的介绍中提及,GLM-5.2是该公司迄今为止所推出的、具备最强能力的开源模型。其核心研发工作主要围绕两个方面展开:一方面,成功地将1M token的超长上下文能力,从仅存在于理论层面的“纸面参数”,真正落地成为可以在实际生产环境中稳定运行的功能;另一方面,则是对其长程代码(Coding)能力进行了进一步的优化与增强。
北京计算机学会AI专委会秘书长、北京大学特聘研究员张有鱼向《科创板日报》记者表示,智谱GLM-5.2的推出标志着国产大模型在编程这一垂直应用场景中取得了实质性的关键突破。
首先,为了打破双寡头垄断的局面,GLM-5.2依赖于其在全球编程基准测试中取得的登顶实测表现以及卓越的性价比,成功在长上下文编程场景下展现出显著的优势。这一优势正在对行业格局进行重塑,并促使智谱、OpenAI与Anthropic形成三方鼎立的“新御三家”格局。
其次,虽然未能成功实现全维度的超越,但在当前多数中高频的实际开发场景当中,该模型已经具备了作为海外头部模型替代方案的能力。然而,核心短板依然存在。在深度的数理逻辑推理以及跨领域知识的复杂融合方面,GLM-5.2与海外最顶尖水平相比仍然存在一定的技术代差,这构成了下一步需要重点攻坚的方向。
惊人的低成本
即便在部分性能维度上依然存在一些短板,但中国AI大模型在另外一方面所展现出的优势,已经日益受到全球AI行业的广泛关注,即成本层面。
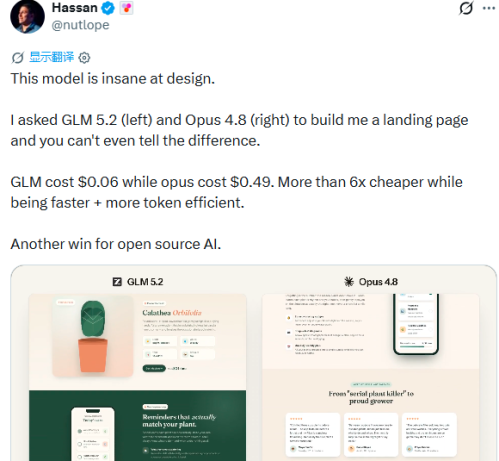
X平台用户Hassan于周四指出,GLM-5.2在架构设计上展现出了极高的复杂性。该模型运用了MoE稀疏混合专家架构,其总参数规模达到了744B,而在执行推理任务时,实际激活的参数量约为40B。同时,它还具备处理长度达1M tokens的超长上下文的能力。
在登陆页面生成测试中,左图所示的GLM 5.2与右图所示的Opus 4.8均被用于创建相同页面,其输出结果几乎无法区分。GLM模型的成本仅为0.06美元,而Opus模型的成本则高达0.49美元,成本差异超过6倍。此外,GLM在响应速度和token消耗方面也表现出优势。这一结果表明,开源人工智能模型再次取得了显著进展。
正如财联社此前在上周的报道中所介绍的那样,为了应对人工智能成本正以惊人的速度急剧攀升的局面,全球范围内的大型企业与初创公司正开始转而采用定价更为低廉的人工智能模型工具。这些工具中包含了相当数量的国产大模型。这一市场趋势的转变,正在直接引发一场价格压力,并将其施加给美国的行业领军企业OpenAI与Anthropic。
根据初创公司Vercel所披露的信息显示,其在平台上的AI使用份额中,DeepSeek所占比例已从4月份的仅1%实现了急剧的增长,至5月份已达到17%。而在另一家专注于处理AI查询的初创公司OpenRouter的平台上,自5月中旬起,DeepSeek已持续占据最常用AI模型厂商的主导地位。
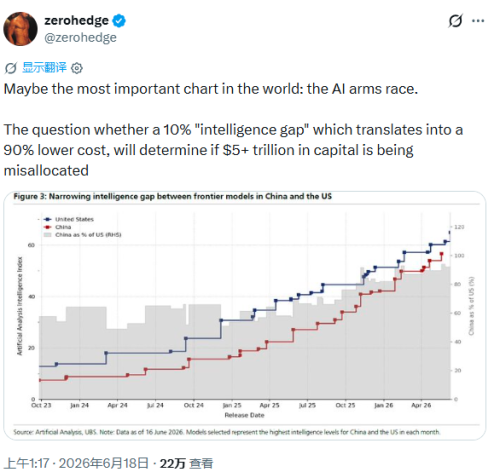
对此,知名财经博客网站zerohedge给出了这样的评价:在一定意义上,这也许是当前语境下全球范围内最重要的图表——它所揭示的正是那场人工智能领域的军备竞赛。
问题在于,当全球行业逐渐意识到中美两国大模型之间那"10%的智能差距"可能仅仅对应着"90%的成本优势"时,国际资本市场也将不得不展开一场深刻的反思:在过去数年的时间里,持续涌入人工智能领域的逾5万亿美元资本配置,是否已经出现了严重的方向性错配?
无论如何,当大模型的竞争焦点从单纯追求参数规模与封闭壁垒,转向侧重实际应用、开源生态以及性价比时,以智谱GLM-5.2为代表的中国技术力量,正凭借其超越外界预期的迭代速率,对全球人工智能竞争的格局进行着实质性的重塑。
来源:中国大模型何时能达Fable级别?马斯克预计明年Q1 唐杰称不用那么久 | 财联社