资讯
端到端4D流世界模型首次仅凭RGB图像完成三维流物理建模
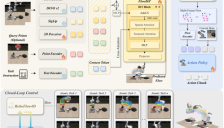
RoboFlow4D 是一个创新的端到端4D世界模型,专为实时机器人操控设计。它仅凭RGB图像和语言指令,直接预测未来多帧的三维运动轨迹(3D Flow),作为显式规划信号接入动作策略。这种方法避免了传统动作模型的不稳定性,让机器人在执行前拥有清晰的三维路径规划,有效应对遮挡、物体偏移等复杂场景。模型轻量级、即插即用,推动了机器人操控向更智能、实时的方向发展。

中科院与南京大学及Dexmal推出Realtime-VLA FLASH,机器人操控实现毫秒级
中科院联合南大与Dexmal推出Realtime-VLA FLASH框架,通过投机推理范式优化基于扩散的视觉-语言-动作模型,将推理延迟从58.0ms降至7.8ms,实现3.04倍加速。该框架采用轻量草稿模型生成候选动作块,主模型并行验证,并引入阶段感知回退机制,确保在精细调整阶段的可靠性,为机器人操控的实时应用如高速传送带抓取提供高效解决方案。

免费开源 AI 国际象棋引擎 Maia 3 正式发布 提升人类对局体验
Maia 3 是最新发布的免费开源 AI 国际象棋引擎,专注于模拟人类决策模式而非追求超人类水平。它基于 Llama 3.1 架构,通过 2.5 亿局真实人类对局训练,Elo 评分约 1800 分,支持国际象棋、将棋、围棋和中国象棋等多种棋类。该引擎易于在消费级硬件上本地部署,旨在提升业余玩家的对局体验,提供教育性陪练,并推动 AI 技术的民主化。

AtomicVLA让机器人像搭积木一样组合原子技能
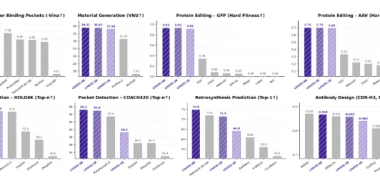
AtomicVLA是一种新型视觉-语言-动作模型,通过将机器人任务分解为原子技能(如pick、place),并利用技能引导的混合专家架构(SG-MoE),实现复杂长程任务的高效执行和持续学习。该模型引入思考-行动统一框架,支持技能库的即插即用扩展,避免灾难性遗忘。实验表明,AtomicVLA在LIBERO、CALVIN基准和真实世界任务中均优于现有模型,提升了机器人任务完成率和学习能力。

京东开源1680小时第一视角人类操作数据,助力具身智能学习人类操作
京东开源了EgoLive数据集,这是一个大规模的第一视角人类操作数据集,包含1680小时视频、65,866个任务片段,覆盖家政、零售、物流等真实场景。数据集提供手部轨迹、深度图、语言描述等多模态标注,旨在帮助具身智能机器人通过观察人类操作来学习任务执行,填补机器人训练数据的空白,推动智能机器人技术在真实世界中的应用。
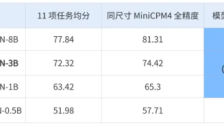
面壁智能与清华联合开源端侧新品BitCPM-CANN,突破手机运行大模型壁垒
面壁智能联合清华大学开源BitCPM-CANN,这是一项低比特大模型训练技术的最新突破。该模型在华为昇腾平台上完成,提供0.5B到8B多个尺寸,推理时能释放约6倍显存红利,大幅降低硬件门槛,使8B参数大模型可在主流手机上流畅运行。同时,模型能力保留率高达90%以上,证明了技术的可扩展性和工程可复现性,加速端侧AI的普及与落地。
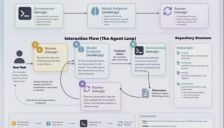
微软Webwright开源:网页智能体从点击式进化为代码式
微软开源了Webwright框架,这是一个创新的网页智能体框架,摒弃了传统的‘点击式’操作,转而让AI模型直接编写Playwright代码和执行Bash命令来完成复杂网页任务。该框架采用极简终端优先设计,代码量仅约1000行,支持逻辑复用、复杂逻辑处理和工程化纠错,并通过门控自检与历史压缩机制解决智能体常见痛点。在基准测试中表现优异,显著提升任务效率和成功率,标志着网页智能体向开发者范式转型的关键进展。

复旦、CityUHK、SMU、UIUC等13家机构联合发布具身智能安全综述
这篇文章报道了由复旦大学等13家机构联合发布的具身智能安全综述。综述提出了“五层能力圈”框架,系统分析了从感知到Agentic系统的安全风险,强调“能力—风险”二象性。它梳理了攻击与防御研究,并指出了多模态融合、规划层越狱等研究空白,为具身智能的安全发展提供了全面指导。

ICML 2026首个视觉语言模型并行思考框架发布,解析其内在机制
本文介绍了ICML 2026上提出的Visual Para-Thinker,这是首个针对大规模视觉语言模型的并行思考框架。它解决了视觉任务中深度推理面临的注意力漂移和视觉幻觉问题,通过引入Pa-Attention和LPRoPE机制,实现了不同推理路径的隔离性、无偏性和可区分性。框架采用以视觉为中心的路径划分方式,包括块划分和扫描划分,并结合混合训练策略,有效提升了模型在视觉理解任务中的性能。

人文赋能AI技术革新 赵佳音打造精细化人机互动全新架构
本文报道了赵佳音(笔名赵嘉音)在人工智能领域的重大创新,她历经十年攻关,开发出完整的AI人文算法原生体系,有效解决了AI在情感理解、共情适配方面的技术瓶颈。通过独创的嘉音常数、诗性基元等理论,该体系实现了人文艺术与AI工程的深度融合,填补了国际技术空白,被国内外主流系统集成,推动了人机互动的精细化发展。

仿生机器人从鱼、蛇、尺蠖、章鱼等生物中找到通用运动语言
华南理工大学等单位在Research期刊发表论文,提出一种通用运动学模型,通过结合身体曲率方程和非线性振荡器,统一描述鱼、蛇、尺蠖、章鱼等多种动物的运动方式。该模型为仿生机器人提供了通用的‘运动语言’,简化了控制算法设计,并能生成复杂运动如高机动转向。研究通过机器鱼实验验证了模型的有效性,推动了仿生机器人技术的发展。

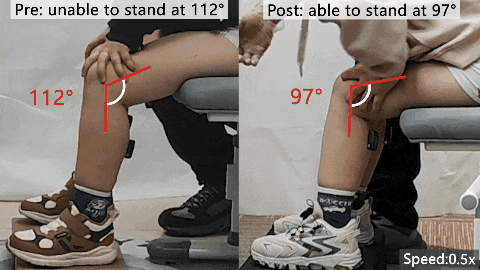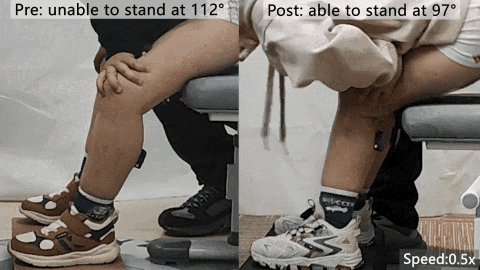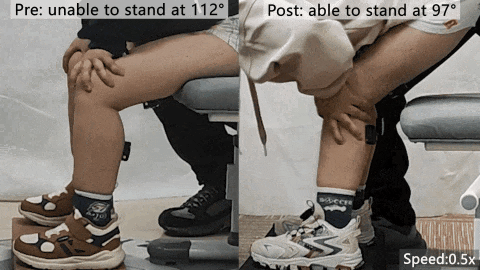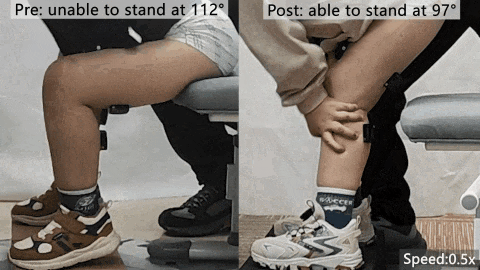
北航0.96公斤可穿戴机器人登Nature头版,助力肌萎缩症患儿独立起身
北京航空航天大学团队联合麻省理工学院与北京大学第三医院,开发了一款仅重0.96公斤的可穿戴机器人,用于肌萎缩症患儿的康复训练。该设备颠覆传统,通过提供可控阻力而非助力,促进神经肌肉重塑,帮助6名患儿在6周高强度训练后获得独立起身能力,肌力提升130%,肌肉增长19%,并能维持长期效果。研究以加速预览形式发表在Nature头版头条,提出了康复训练的新范式。

蚂蚁灵波“因果世界模型”论文被世界机器人顶会RSS 2026接收
蚂蚁灵波科技与香港科技大学合作的研究论文被机器人顶级会议RSS 2026接收。该论文提出了因果世界建模框架,并开发了全球首个开源的自回归视频-动作世界模型LingBot-VA。这一模型使机器人能在执行任务时预测环境变化,实现类似人类的‘边观察、边判断、边行动’能力,推动机器人从依赖指令执行向更强的环境理解和自主决策发展。

蚂蚁灵波LingBot-VA论文获RSS2026接收,实现机器人边推演边行动
蚂蚁灵波科技与香港科技大学合作的研究论文被机器人顶级会议RSS 2026接收。论文提出全球首个开源的自回归视频-动作世界模型LingBot-VA,通过因果世界建模框架,使机器人能够预测环境变化并生成动作指令,实现边推演边行动的能力。该模型在仿真和真实任务中表现优异,提升了机器人的环境理解、任务泛化和自主决策能力,为具身智能发展提供新方向。