资讯

兰州大学一教师论文图表被指含AI生成水印,涉事期刊声明已启动调查
兰州大学一名教师的学术论文被指图表存在AI生成水印,引发学术诚信争议。涉事期刊《膜科学杂志》已发布公告启动调查,兰州大学也成立专项调查组。事件凸显科研诚信与AI使用规范问题,受到广泛关注。

教师杨某某论文图表被指有AI生成水印,兰州大学成立调查组
兰州大学教师杨某某在《膜科学杂志》发表的论文被指含有豆包AI生成的水印,引发学术不端质疑。6月27日,兰州大学发布声明,称已成立专项调查组启动调查,并强调对科研失信行为零容忍。该事件凸显了AI技术在学术写作中的滥用问题,以及高校对学术诚信的严格监管。
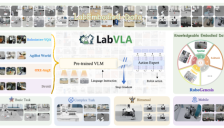
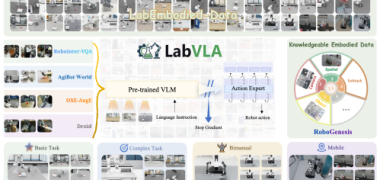
LabVLA:浙大与上海AI Lab联合探索科学具身智能,推动AI进入实验室
LabVLA项目由浙江大学和上海人工智能实验室联合推出,探索科学具身智能的新范式。通过引入视觉-语言-动作预训练模型,LabVLA使AI能够从自然语言实验描述中学习跨任务、跨环境的操作规律,利用知识增强的仿真数据引擎RoboGenesis和科学具身语料LabEmbodied-Data,在LabUtopia基准上实现高成功率并完成真机验证。这解决了现有实验室自动化系统泛化能力不足的问题,推动AI从认知推理向具身操作迈进,促进科学研究的实际应用。
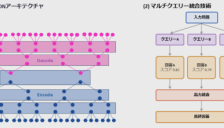
富士通推出PHOTON新架构,性能提升475倍以应对AI算力瓶颈
富士通推出PHOTON新架构,旨在解决AI领域中Transformer模型在复杂场景下的性能瓶颈。该架构通过语义分层技术优化并行计算,显著降低计算复杂度和内存占用,在多查询任务中实现高达475倍的性能提升,大幅降低AI运行成本,为智能化应用提供轻量高效的底层支撑。

上海通途与地平线战略签约,探路者大模型压缩迈向产业化
近日,上海通途半导体与地平线签署战略合作协议,共同开发大模型带宽压缩技术,以解决端侧AI部署中的带宽与内存瓶颈。此举标志着探路者全栈式大模型压缩技术从预研迈向产业化,加速智能驾驶、机器人等场景的高效部署。合作将优化车规级芯片推理性能,推动端侧AI市场扩容,结合探路者芯片业务的强劲增长,彰显了其在硬科技领域的竞争力。

商汤科技秘密研发多模态模型U1Pro,由林达华牵头,预计7月启动内测并对标OpenAI
商汤科技正秘密研发多模态大模型U1Pro,由首席科学家林达华牵头,预计7月启动内测。该模型专注于设计场景,对标OpenAI的GPT-Image2,具备长程逻辑能力和8K超清输出,内部测试效果接近甚至超越GPT-Image2。这标志着AI图像生成技术正从娱乐向专业生产力工具演进,并加速多模态大模型在设计领域的竞争。
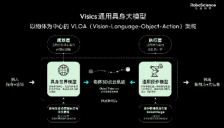
机器人有了通用大脑:RoboScience发布Visics大模型,实现跨场景自主执行
RoboScience 发布通用具身大模型 Visics,采用 VLOA(Vision-Language-Object-Action)架构,实现机器人跨本体、跨物体、跨任务的自主执行能力。该模型通过物体3D点云轨迹统一表征,结合双引擎设计和仿真+视频数据飞轮,显著降低数据成本,解决泛化能力差和长程任务执行难题,推动具身智能从实验室走向产业应用。
LeCun与谢赛宁转发中关村学院ECCV2026世界模型与VLA共融方案VLA-JEPA
本文介绍了VLA-JEPA,一个创新的Vision-Language-Action模型预训练框架,它借鉴Yann LeCun提出的JEPA方法,在潜在表征空间中学习预测世界状态变化,而非像素级重建。该框架能有效利用有限机器人数据和丰富人类视频,关注动作导致的状态转移,减少视觉噪声影响。VLA-JEPA仅使用13条轨迹即可完成任务,展示了在少数据下的稳健性,并获得LeCun和谢赛宁的转发关注,为机器人学习提供了新思路。
OpenAI 发布 GPT-5.5-Cyber,漏洞修补迈向自动化
OpenAI 发布 GPT-5.5-Cyber 模型,专为网络安全领域设计,能自动化发现并修补漏洞。该模型在 CyberGym 等测试中表现卓越,超越其他 AI 工具,填补了从漏洞预警到修复的空白。基于海量代码审计数据,它能深入分析攻击路径、生成补丁,大幅压缩安全响应时间,为企业数字资产提供关键防线。
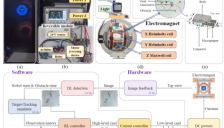
浙大团队T-RO研究成果:磁控微型机器人实现复杂环境中的凌波微步
浙江大学团队在顶级期刊《IEEE Transactions on Robotics》上发表最新研究成果,提出STTRL-DVO强化学习框架。该框架通过虚拟雷达观测和Transformer架构,解决微型机器人在复杂动态环境中的导航瓶颈,实现高鲁棒性自主导航。实验显示,磁控微型机器人在活体生物障碍物中追踪成功率达89.8%,超越现有方法,为微观世界的自动驾驶技术提供新突破。

生数 Vidu Q3 在华为云上线,推出面向剧集的视频生成方案
人工智能视频生成迎来新进展,生数科技的Vidu Q3模型正式上线华为云MaaS平台。这款‘为剧而生’的视频大模型具备16秒声画同步、高清画质和多镜头叙事能力,解决了长视频创作的痛点。它提供Turbo和Pro两个版本,分别针对快速创意和专业制作需求,为企业营销、影视制作提供高效解决方案,推动行业智能化升级。
智谱GLM-5.5预计8月发布,有望追赶全球顶尖大模型
智谱公司计划于8月发布新一代基座大模型GLM-5.5,参数量有望突破1万亿,实现架构重大跨越。此前,在美国对Anthropic模型实施访问限制的背景下,智谱快速推出开源模型GLM-5.2,并在AI编程等指标上取得优异成绩。GLM-5.5作为战略级产品,旨在追赶全球顶尖大模型水平,参数量提升50%以上,结合智谱的优化经验,有望成为中国AI技术追赶的重要转折点,加速国产大模型发展与生态构建。

京东开源JoyAI-VL-Interaction实时视频交互模型拒绝一问一答
京东开源JoyAI-VL-Interaction,全球首个全栈开源的实时视频交互模型。该模型打破传统‘一问一答’模式,能自主观察视频流并实时响应,适用于安防监控、直播解说等高实时性场景。通过后台委托机制处理复杂任务,支持模块化扩展,在盲评测试中表现卓越,为开发者提供了强大的AI技术基座。
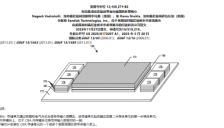
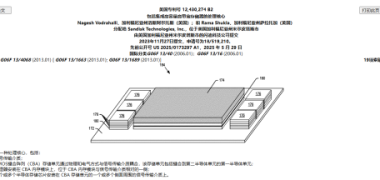
闪迪披露3D堆叠专利揭示闪存算力一体化趋势
闪迪披露一项3D堆叠专利,探索将NAND闪存直接集成到计算芯片内部,以缓解HBM供应紧张、容量受限和延迟问题。该方案基于CBA技术,让HBM与NAND分工协作,结合HBM高带宽和NAND大容量优势,旨在提升数据传输效率、降低成本和功耗,揭示了闪存与算力一体化的趋势,但商业化仍面临封装、散热等挑战。

小米开源全屋智能AI方案Miloco 2.0 让家具备记忆识人执行能力
小米开源全屋智能AI方案Miloco 2.0,基于自研MiMo大模型,实现从规则触发到自主推理的全面升级。该方案具备通用常识、身份识别、家庭记忆和任务执行四大核心能力,让家“能记忆、会识人、懂执行”。通过主动智能,系统像管家一样在用户需求前行动,提供个性化关怀和服务。部署需特定硬件,并可通过Web面板实时监控,推动智能家居向更智能、个性化方向发展。