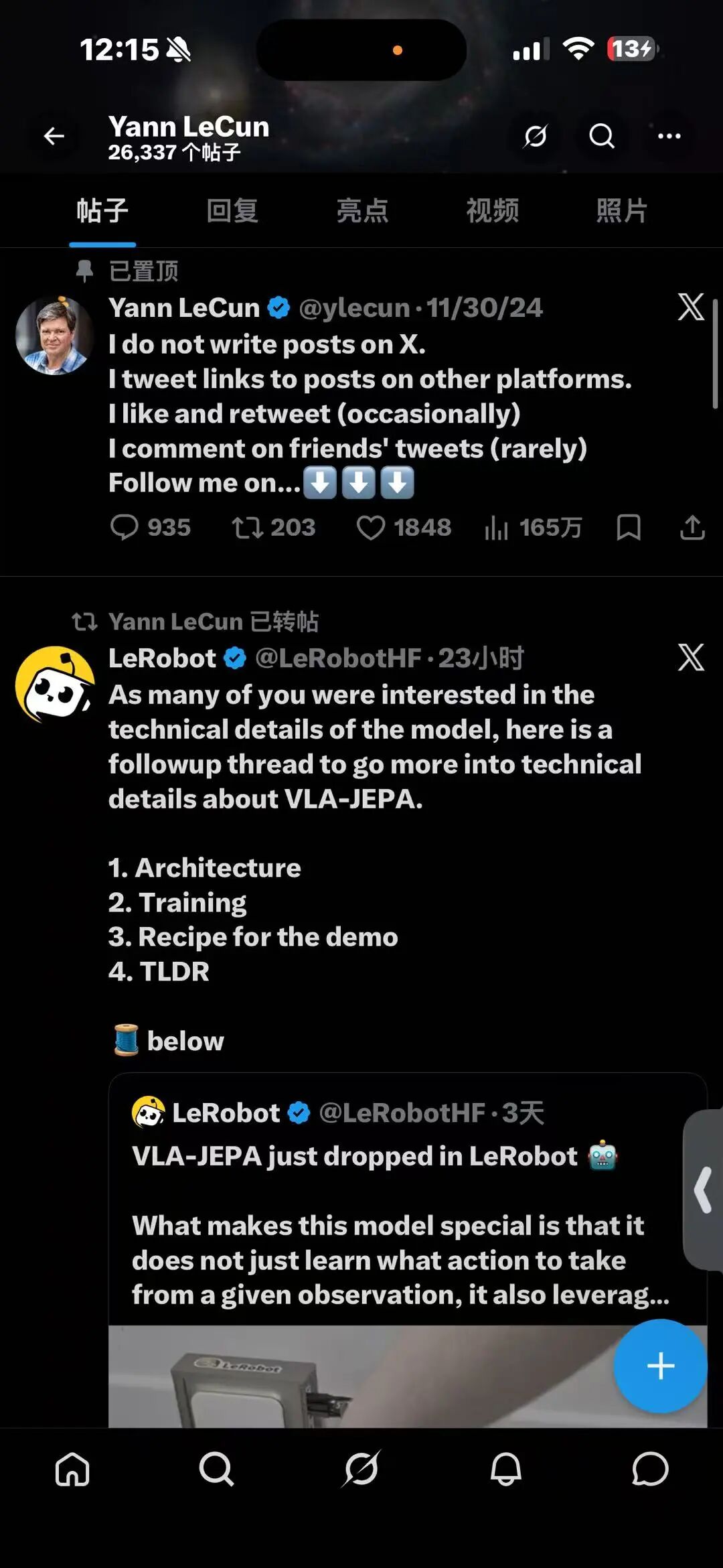
LeCun与谢赛宁转发中关村学院ECCV2026世界模型与VLA共融方案VLA-JEPA
借助于有限的机器人数据以及大量的人类数据,是否能够使得 VLA 模型变得更加稳健?
近期,来自中国科学技术大学、北京中关村学院、上海交通大学以及宁波东方理工大学等机构的研究团队所提出的VLA-JEPA模型,提供了一个值得关注的新思路。该思路主张,不应再让模型于像素空间中执着地追逐对“未来帧”的预测;相反,应当借鉴Yann LeCun等人所倡导的JEPA(联合嵌入预测架构)路线,转而在潜在表征空间内对世界状态的变化进行学习与预测。
作为首个成功移植至lerobot框架、并实现视觉语言动作模型(VLA)与世界模型有机融合的研究工作,其效能经过官方实验的严格验证。结果显示,VLA-JEPA仅凭借13条示范轨迹,便能胜任基础的部件装配任务,因而获得了Yann LeCun与谢赛宁等权威学者在社交平台上的认可与转发。
与逐像素重建方法相比,JEPA式潜空间世界模型更加注重对场景结构、物体交互以及由动作所引发的状态转移的捕捉,从而能够有效弱化背景、光照、视角变化和摄像机抖动等无关视觉噪声的影响。换言之,VLA-JEPA的目标在于让模型从人类视频以及机器人演示中学习到动作如何改变世界,而非仅仅记住画面中哪些像素发生了变化。
这一学术思路与Yann LeCun等人所倡导的JEPA(联合嵌入预测架构)潜空间预测路线,以及谢赛宁等学者在自监督视觉表征学习领域的相关探索是一脉相承的。其核心主张在于,模型应当超越对像素的直接重建,转而致力于从上下文中学习可迁移、可泛化的高层语义表征。


arXiv:https://arxiv.org/abs/2602.10098代码:https://github.com/ginwind/VLA-JEPA项目主页:https://ginwind.github.io/VLA-JEPA/Hugging Face:https://huggingface.co/ginwind/VLA-JEPA
一句话看懂

VLA-JEPA是一个面向Vision-Language-Action模型的JEPA式预训练框架。它将人类视频与机器人演示统一纳入到"潜在世界模型"的训练目标当中:当前观测经过VLA主干网络获得潜在动作token,未来帧仅通过目标编码器来提供监督信号,使得模型需要在Latent Space中完成对未来状态的预测任务。
这套设计方案旨在有效解决以往在潜在动作(latent action)预训练过程中所产生的一个核心偏差问题,即模型倾向于学习并捕捉图像中的像素级表面变化,而非由实际动作所引发的、具有语义深度的状态转移与演化。尤其是在互联网视频或人类演示视频这类数据场景中,画面中的镜头移动、背景光照变化,以及与核心操作无关的物体运动,其视觉显著性往往远超过真实有效的操作信号,这会导致模型所学到的所谓“潜在动作”表示,逐渐退化为目标图像的一种高效压缩编码,而丧失了与真实动作语义的对应关系。
为什么需要这种方法
Latent Action 方法的必要性
对于视觉语言动作(VLA)模型的发展而言,其面临着一个核心的瓶颈:从真实机器人身上采集轨迹数据的过程,伴随着高昂的成本投入、受限的数据规模,以及相对狭窄的任务覆盖范围。与之形成鲜明对比的是,互联网平台上蕴含着海量且丰富的人类视频与无标签操作影像数据。因此,潜在动作(latent action)方法的提出,正是为了有效利用这些无标签的操作视频,来对VLA模型进行预训练。在这一框架下,该方法致力于从缺乏动作标签的视频中,习得一种表征“状态如何发生变化”的中间表示形式,并进而将这种学得的表示能力迁移至下游的机器人控制任务。可以说,潜在动作方法在功能上,扮演了连接大规模视频数据与具体机器人动作策略之间的关键桥梁角色。
从理想角度而言,latent action 所应当捕捉的核心内容是与动作相关的状态转移语义——例如物体被推动、抓取或移动后环境状态随之发生的演变过程,而非仅仅记录画面当中哪些像素发生了变化。不过,VLA-JEPA 论文在其引言部分明确指出,现有的 latent-action 预训练方法普遍存在以下四类问题。
近期,由中国科学技术大学、北京中关村学院、上海交通大学以及宁波东方理工大学等机构组成的研究团队所提出的VLA-JEPA模型,提供了一种值得关注的新思路。该思路主张,不应再令模型在像素空间内持续追求对未来帧的逐像素预测;相反,应当借鉴Yann LeCun等人所倡导的JEPA(联合嵌入预测架构)路线,转而在潜在的表征空间之中对世界状态的动态变化进行学习与预测。
许多方法依赖未来帧作为监督信号,例如直接对未来像素进行预测,或将相邻帧之间的变化压缩成一个潜在动作(latent action)。
然而,一个技术层面的核心矛盾在于,视频画面中最为显著的视觉动态,往往并不对应于机器人的实际操作动作,而是表现为纹理、光照、背景以及视角等无关因素的变化。这类视觉因素的变化幅度通常较大且在预测上相对容易,却与机器人所需精确控制的运动自由度之间存在着较弱的关联。
由此来看,模型所习得的 latent action 可能更接近于一种"画面变化编码器",而非真正意义上的"动作语义表示"。
问题 2:真实世界视频当中存在的无关运动噪声往往会被进一步放大
在人类视频或互联网视频当中,诸如摄像机移动、背景变化以及非因果物体运动等各类噪声现象十分常见。
这些变化有时甚至比实际操作引起的状态变化更为显著。倘若 latent action 目标主要基于帧间差异来构建,模型就更倾向于去编码那些强视觉信号,例如镜头晃动以及背景移动,而非去捕捉有意义的交互动态。
其结果在于,latent action 被噪声运动所主导,从而难以有效服务于机器人控制任务。
问题 3:信息泄漏会让 latent action 退化
在训练过程中,一些 latent-action pipeline 会同时采用当前观测以及未来观测,或是允许未来的观测信息参与到 action variable 的学习过程之中。
这种设计在技术实现上会引入一个潜在的捷径:所学习的latent action无需对“状态为何发生转变”这一内在机制作出解释,而只须将未来画面本身编码即可。
通过这种方法所习得的潜在动作,在训练损失指标上可能呈现出良好的表现趋势,然而在语义内涵层面却显得相对空洞。这类潜在动作虽然能够有效地拟合训练目标所设定的优化任务,但其本身并不必然构成可用于实际控制的动作因素。
问题 4:多阶段训练流程过于复杂
为了有效缓解上述问题,许多研究方法会采用一种三阶段甚至更多阶段的训练流程。例如,该流程首先进行表示预训练,随后对 latent action 进行学习或对齐,最终完成策略模型的训练。
这种多阶段流程引入了额外的工程复杂度,也容易引入不同阶段之间的不一致性。具体而言,不同阶段所采用的目标函数、所依赖的数据分布以及所操作的表示空间之间可能存在着固有的不匹配性,这会导致训练过程难以保持稳定,也不利于清晰地评估每个独立模块所带来的具体贡献。
方法:把未来当监督,而不是输入
VLA-JEPA 框架。在人类视频阶段,该方法依赖于 latent world modeling 的对齐损失,而机器人数据阶段则在此基础上额外引入了动作预测损失。

具体而言,VLA-JEPA 选用 Qwen3-VL 作为其 VLM 主干网络,并引入了可学习的 latent action token 来表征相邻状态之间的转移过程。在这一框架下,视频帧借助 V-JEPA2 编码器被映射至世界状态表示;预测器则依据当前状态以及 latent action 来对未来的 latent state 进行预测,并将其与目标编码器所得到的未来状态进行对齐。
在具备机器人动作标注数据的情况下,该方法进一步引入一个基于flow matching技术构建的动作头,用于生成连续的末端执行器轨迹。其中,人类视频承担为系统提供通用动态知识的职责,而机器人轨迹则负责将这些知识转化为可具体执行的动作指令。相较于采用多阶段latent-action预训练的流程,此训练流程显得更为直接:首先在视频数据上进行JEPA预训练,随后在机器人数据上对动作头进行微调。
实验:
该研究涵盖了三个仿真基准以及一个真实机器人环境。
LIBERO、LIBERO-Plus、SimplerEnv 与真实 Franka 机器人实验

论文在LIBERO、LIBERO-Plus、SimplerEnv以及真实世界的Franka桌面操作任务上,对模型进行了评估。在预训练阶段,该方法运用了来自Something-Something-v2数据集中约22万个人类视频,以及DROID数据集中约7.6万条高质量机器人演示轨迹。LIBERO与LIBERO-Plus的微调环节则仅依赖于约2000条仿真专家演示;而真实世界实验所采用的三类任务,共使用了100条演示数据。
LIBERO 以及 LIBERO-Plus:
分别达到97.2和78.1的平均成功率
在LIBERO基准上,VLA-JEPA取得了97.2%的平均成功率,特别是在Object与LIBERO-10这两个子基准上取得了最优的性能表现。更值得关注的是,尽管OpenVLA-OFT与pi0.5等强力基线模型依赖于大规模的机器人数据进行训练,但VLA-JEPA的设计目标是在显著减少所需训练数据量的前提下,力争达到与之相当、甚至在某些情况下超越的性能水平。

在包含多重OOD扰动条件的LIBERO-Plus基准测试中,VLA-JEPA在7个扰动维度中的5项上取得了最佳结果,其平均成功率达到78.1%,显著高于OpenVLA-OFT的69.6%和pi0-Fast的61.6%。论文作者据此分析认为,这一表现说明模型所习得的latent action并非对应某种固定的视觉模式,而是更贴近于对世界状态转移过程的表示,从而进一步印证了VLA-JEPA在应对分布外扰动时所具备的鲁棒性优势。

SimplerEnv:
分别达到65.2和57.3的平均成功率
在SimplerEnv任务上的实验结果也向我们传达了一个具有实践意义的警示:人类视频数据并非能够解决所有问题的通用方案。具体而言,在若干项测试视觉匹配能力的任务中,移除了人类视频进行预训练的模型反而取得了更高的成功率。这一现象揭示,VLA-JEPA的核心价值并不在于凭空创造原本不存在的全新动作技能,而是依赖于已有的高质量机器人轨迹数据,去增强模型在不同条件下的鲁棒性以及策略输出的稳定性。

真实机器人通过训练,已经掌握在首次抓取失败后进行二次抓取的能力。
真实 Franka 机器人实验结果

真实世界实验环节采用了FR3机械臂、Robotiq 2F-85夹爪以及三台D435摄像头,训练数据集包含了100条涉及桌面抓取与放置任务的演示轨迹。论文将评估体系划分为三个类别:任务内分布(ID)、任务外分布(OOD)以及布局外分布(OOD)。
VLA-JEPA 与 pi0 及 pi0.5 相比,在真实操作环境中展现出一个有趣的现象:一旦发生首次抓取失败,该模型能够自动重新打开夹爪,并尝试进行二次抓取;然而,对比模型并未稳定地表现出此类行为。
研究团队将这一能力归因于人类视频中所蕴含的、关于“重复抓取”的操作知识。在人类操作视频中,包含“失败后调整并再次尝试抓取”这类片段的数据更为常见,而机器人演示数据通常不会特意包含此类恢复性的行为策略。这恰恰凸显了VLA-JEPA这条技术路线所具备的核心报道价值:人类视频数据虽然可能无法直接用于教授机器人进行精确的运动控制,却能够有效地补充现实世界任务中关于“出现问题时如何进行补救”的常识性知识。
消融:人类视频主要提升稳定性
研究人类视频比例对LIBERO-Plus在不同扰动维度下成功率所产生的影响。

随着所提供的VLA-JEPA模型中人类视频数据量的增加,LIBERO-Plus基准测试所展现出的模型鲁棒性获得了整体性的提升。论文对此现象提出的解释是,人类视频数据的作用更多地体现为强化模型已掌握技能的稳定性,而非直接为其注入全新的动作执行能力。基于这一发现,该框架成功地将人类视频从传统上作为“动作标签替代品”的角色,重新定义为一种“世界动态先验”,这一转变也令VLA模型表现出更优的数据效率。
结语
具身智能的核心,其目标并不止步于令模型对视觉内容进行简单的“识别”或“理解”,而是要使其进一步理解动作本身将如何引发并改变世界的后续状态。对于机器人系统而言,视觉感知、语言指令与机器人动作并非彼此割裂、独立运作的模块。语言负责定义目标与意图,视觉持续提供环境与物体的状态信息,而动作则经由物理交互直接作用于环境并改变其状态。世界模型的核心价值,正在于能够在这三种模态之间,构建起一条可预测、可推理的动态交互链条。
VLA-JEPA的核心贡献在于重新界定了人类视频数据的功能定位:该方法并未将其视为缺乏动作标注的机器人数据,而是将其转化为学习世界动态机制的训练素材。潜在世界模型在这一框架中承担了关键的中间层转换功能,负责将原始像素层面的变化压缩整合为更为抽象的状态转移表示,从而引导模型将注意力集中于动作与状态变化之间的因果关联,而非被光照、背景、视角切换以及相机运动等无关视觉因素所干扰。
这种在潜在空间中所采用的预测目标,也使得世界模型能够更为顺畅地与视觉语言动作模型(VLA)形成结合。与直接对未来像素进行预测的方式相比,对潜在状态(latent state)的预测更加贴近具身智能所真正需要具备的核心能力,即在当前观测信息与潜在动作表征的共同约束条件下,对环境后续将步入何种状态作出合理估计。换言之,潜在世界模型所承担的功能在于,将视频数据中所呈现的视觉变化,转化为可为下游控制任务所直接利用的动态先验知识。
需要明确的是,VLA-JEPA的工作并未表明人类视频可以替代高质量的机器人数据。相反,它更清晰地阐明了二者的具体分工:机器人数据为任务执行提供了可直接落地的动作表征,而人类视频与互联网视频则贡献了更为广泛的世界动态先验经验。倘若具身智能在未来需要持续拓展其能力边界,核心挑战将超越单纯的机器人轨迹数据积累,转而聚焦于如何将大规模的视觉世界经验,系统地转化为可供机器人调用、预测和泛化的潜在世界模型。
作者团队及合作单位
VLA-JEPA 的研究工作依托于北京中关村学院“高效通用跨尺度空间智能世界模型”项目得以完成,第一作者包括北京中关村学院与中国科学技术大学联合培养的博士生孙景文,以及上海交通大学与宁波东方理工大学联合培养的博士生张文垚。通讯作者由宁波东方理工大学助理教授、北京中关村学院共建导师金鑫,以及中国科学技术大学教授、北京中关村学院共建导师陈志波担任。该研究团队长期致力于具身领域世界模型的前沿探索。
来源:LeCun、谢赛宁转发的世界模型与VLA共融方案:中关村学院ECCV2026—VLA-JEPA | 具身研习社