资讯

2026智能养老服务机器人应用大赛精彩回顾:机器人赋能养老,科技温暖夕阳
2026智能养老服务机器人应用大赛在廊坊市圆满落幕,以‘机器人赋能养老,科技温暖夕阳’为主题,汇聚全国57支团队,在模拟真实家庭、社区和养老机构场景中,通过康复机器人和养老机器人两大赛道,围绕辅助行走、健康管理、情感陪护等八大核心任务展开激烈比拼。大赛展示了外骨骼机器人、二便护理机器人等产品从实验室走向实际应用的进展,精准解决养老服务痛点,提升照护效率与质量,彰显科技在温暖老年人生活中的重要作用。

机器人告别逐帧动作学习 全球首个事件级具身智能世界模型发布
5月29日,自变量机器人团队发布全球首个事件级具身智能世界模型WALL-WM,革新传统逐帧学习方式,采用以事件为中心的预测机制,提升机器人理解和执行任务的泛化能力。该模型通过工程重构和数据系统优化,在多项指标上领先,为具身智能领域带来突破性进展。

Genesis World 1.0开源,机器人评估成本降至零的基础设施发布
Genesis World 1.0重磅开源,这是一个革命性的机器人开发操作系统。它通过高保真仿真技术,将机器人模型的评估成本降至零,实现89%的真实相关性,允许开发者在虚拟环境中完成99%的验证工作。这解决了硬件评估的高成本和统计需求矛盾,加速了机器人基础模型的迭代和创新,为行业提供了高效的基础设施。

高擎Mini Pi plus开源人形机器人平台ICRA 2026全球首发
本文介绍了高擎动力在ICRA 2026上全球首发的Mini Pi plus开源人形机器人平台。该平台以15kg的轻量化机身、高性能动力学和完整的开源生态,旨在打破科研平台的价格壁垒与技术黑箱,解决高校和研究机构在人形机器人开发中面临的‘不可能三角’问题。通过提供从仿真到真机的全栈工具链,Mini Pi plus使研究者能更专注于算法创新,推动机器人科研与教育的发展。

阶跃星辰开源 Step 3.7 Flash 大模型 速度翻倍
阶跃星辰正式开源Step 3.7 Flash大模型,专为智能体生产化落地设计。该模型采用稀疏混合专家架构,参数量达196B,生成速度最高每秒400 Tokens,显著提升效率并减少延迟。具备原生多模态理解能力,可解析UI、图表等视觉信息,并增强联网搜索功能。在智能体工作流中表现出高工具调用稳定性和生态兼容性,降低开发门槛,助力复杂任务高效执行。

具身智能迈入下半场,RoboMemArena全面评测机器人记忆系统
文章介绍了具身智能领域首个聚焦机器人记忆能力的评测基准RoboMemArena,由香港科技大学等多所顶尖高校联合打造。该基准旨在解决机器人在长时程任务中‘记不住’的瓶颈,通过物体转移、目标遮挡、动作计数和顺序执行四大核心场景,提供多模态标注、2600条专家轨迹和真机测评支持,为机器人记忆系统评估建立了统一标准,推动了具身智能在长期规划与动态决策方面的发展。
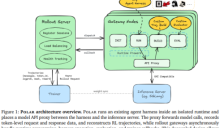
英伟达开源 Polar 框架,助力 AI 编码智能体实现强化学习零门槛进化
英伟达开源了Polar强化学习训练框架,使AI编码智能体如Codex和Claude Code无需修改原生代码即可接入GRPO训练。该框架通过透明代理拦截API请求并重构训练轨迹,解决了传统方法的高成本和信息丢失问题。实验显示,在SWE-Bench测试中性能大幅提升,训练效率显著优化,为AI智能体进化提供标准化路径。

国产具身大模型Wall-OSS-0.5开源发布,实现预训练零样本部署
自变量机器人开源了国产具身大模型Wall-OSS-0.5,该VLA模型通过预训练实现零样本部署,无需任务特定微调即可在真实机器人上执行多种挑战性任务。测试显示其性能远超行业标杆,包括零样本任务得分高、微调效率提升,并通过四项技术创新构建护城河。这标志着具身智能开发范式转变,加速通用机器人在复杂环境中的落地。
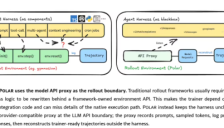
英伟达推出开源 AI 框架 Polar,Codex 性能提升近 600%
英伟达近日推出开源AI框架Polar,该框架旨在帮助现有智能体框架如Codex接入广义相对策略优化(GRPO)训练方法,无需改变原有工具调用和上下文管理逻辑。通过在模型API边界处放置智能体,Polar能记录关键数据用于训练,显著提升代码智能体的性能。实验表明,使用Polar训练的Codex在SWE-Bench测试中性能提升近600%,同时训练效率大幅提高,GPU利用率优化,为智能体强化学习提供新方向。

400万条问答、四大推理模块、超越通用大模型,这项成果被CVPR 2026收录
北京大学团队在CVPR 2026上发表论文,提出EQA-Decision数据集和RoboDecision训练框架。EQA-Decision包含超过400万个多模态问答对,覆盖静态场景构建、空间理解、任务动态推理和即时决策四大推理模块。通过监督微调、思维链和强化学习的三阶段训练,模型能有效整合感知与决策,实现'先想后做'的具身智能,为该领域设立全新评测基准。
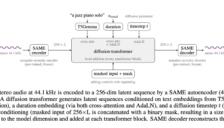
Stability AI 发布 Stable Audio 3:可秒级生成长音频
Stability AI最新发布的Stable Audio 3音频大模型,通过创新的SAME自编码器和扩散变换器架构,实现了音频生成的革命性突破。该模型支持高品质双声道立体声输出,能以秒级速度生成长达数百秒的音频,显著提升创作效率。同时,它降低了硬件门槛,使个人创作者能在消费级设备上进行专业级音频制作。开源部分权重,为音乐和音效创作带来前所未有的灵活性。
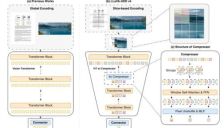
MiniCPM-V 4.6 重新定义端侧多模态巅峰,搭载1.3B模型
面壁智能联合清华大学发布MiniCPM-V4.6,一个仅1.3B参数的端侧多模态大模型。它在多项评测中表现卓越,性能直逼更大模型,同时优化了推理速度和资源占用,支持主流设备运行。通过LLaVA-UHD v4技术降低开销,并开源适配多种框架,已在汽车、智能家居等领域落地,推动端侧AI普及。

X-Humanoid首发统一具身智能范式
北京人形机器人创新中心(X-Humanoid)提出Pelican-Unified 1.0模型,首次将具身智能的理解、推理、想象与行动整合为一个统一的自适应智能闭环。该模型通过共享潜在表示,实现多模态上下文嵌入、思维链推理和未来视频-动作生成的联合学习,克服了现有模型的碎片化局限。实验表明,Pelican-Unified在感知-推理、物理交互和想象规划等多个基准测试中表现优异,并在真实世界机器人任务中展示出强大的组合泛化和零样本迁移能力。

OmniHumanoid:让机器人通过少量视频继承人类动作并适配新本体
OmniHumanoid是一项创新技术,旨在通过跨本体视频生成,实现机器人从人类视频中“继承”动作的功能。它解决了真实机器人数据收集成本高的难题,通过分离动作迁移和外观学习,利用共享动作模型和特定机器人的轻量级LoRA模块,仅需少量视频即可适配新本体。该技术提升了视频生成的稳定性和效率,为具身智能的训练提供了低成本的数据扩展方案。

小鹏机器人新框架集成VLM与隐式世界模型提升机器人物理直觉
香港大学、小鹏机器人及北卡罗来纳大学教堂山分校的研究团队提出了DIAL框架,这是一个端到端的VLA架构,将视觉语言模型(VLM)集成到隐式世界模型中。该框架让机器人在VLM的原生特征空间中进行物理预测,无需额外生成视频,从而提升语义推理和物理直觉。通过双系统协同和两阶段训练,DIAL在仿真和真实机器人上实现了鲁棒的多阶段任务执行,解决了现有VLA架构的训练不稳定和物理直觉不足问题。