

作者:深蓝学院—具身君 出品:深蓝具身智能
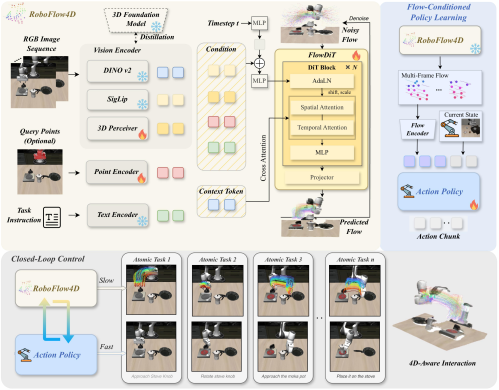
RoboFlow4D 是一套面向实时机器人操控的轻量级 4D World Model。
它从 RGB 视觉观测和语言 指令出发,直接预测未来多帧 3D Flow,并将这个显式的运动先验接入动作策略,让机器人在执行 前拥有更清晰的三维规划信号。

▲图| RoboFlow4D 的整体 pipeline:从 RGB 观测和语言指令出发,预测 3D Flow plan,并将其作为显式 规划信号接入动作策略。©【深蓝具身智能】编译
从“直接出动作”到“先预测该怎么动”
视觉语言动作模型正在快速推动通用机器人操控的发展。给定一张图像和一句指令,机器人可以直接预 测下一段动作,例如“抓起杯子并放入盒子”。
但在真实场景中,直接从观测映射到动作并不总是稳定。
机器人面对遮挡、物体偏移、抓取失败或长程任务时,容易出现犹豫、绕路、重复修正甚至任务失败。背后的一个核心问题是:
动作模型虽然知道“要 做什么”,但未必显式知道“接下来应该沿着怎样的三维路径去做”。
因此,我们希望在动作执行前加入一个中间规划接口。这个接口不直接输出控制命令,而是预测未来一段时间内机器人或任务相关点在 3D 空间中的运动趋势。动作策略再根据这个运动趋势生成具体控制动作。
这正是 RoboFlow4D 想解决的问题。
从 2D Flow 到 3D Flow,再到可闭环的 4D World Model
RoboFlow4D 延续的是近几年 Flow-guided manipulation 的思路:在动作策略之前,先预测一个可解 释的运动先验,让机器人不只是“直接出动作”,而是有一个可以追踪和修正的中间目标。
在 2D Flow 路线上,Im2Flow2Act (CoRL 2024)是一个代表性工作:
它将 2D Object Flow 作为跨域操控接口,从 RGB 与语言中生成任务相关的 2D Flow,再由 Flow-conditioned policy 执行动作。
这条路线证明了 Flow 可以成为连接视觉理解和动作生成的有效桥梁。
但 2D Flow 仍然停留在像素平面,缺少显式 3D 几何。当任务需要精确的空间操作时,一个图像上看似合理的轨迹,未必对应物理世界中可执行的三维运动。

▲图| 基于流的规划在系统级上的比较。©【深蓝具身智能】编译
沿着这条路线继续走向 3D 空间,Stanford 李飞飞团队的Dream2Flow (ICRA 2026)尝试从生成视频 中重建 3D Object Flow,并将其用于开放场景操控和 model-based control。
这类方法展示了 3D Flow 对机器人操作的潜力,但通常依赖视频生成、深度估计、点跟踪和规划等多个专家模块。模块越多,系 统越重,误差也更容易在管线中累积。对于需要快速反馈的真实机器人闭环控制来说,分钟级的规划延 迟很难接受。
再往前一步,来自 Stanford 与 NVIDIA、由李飞飞和 Kaichun Mo 共同指导的PointWorld (arXiv 2026),则将 3D Point Flow 放到更统一的 3D World Modeling 框架中,强调在共享空间域里建模场景动态。
这带来了更强的物理 grounding,也让 3D Flow 更接近世界模型的表达形式。不过,固定时间窗口的规划并不总是适合机器人操控:真实任务往往由多个原子阶段组成,当前阶段需要的不是“未来固定 几帧会怎样”,而是“从当前状态如何到达当前原子目标”。
因此,RoboFlow4D 的目标不是简单替换其中某一个模块,而是把这条路线向实时闭环机器人操控再推进一步:
它保留 3D Flow 的空间表达能力,同时避免复杂模块堆叠;
它不预测固定窗口的未来片段,而是生成朝向当前原子目标的 3D Flow;
它也不绑定某一个特定动作策略,而是作为 plug-and-play 的显 式运动先验,接入不同下游策略。
概括来说,RoboFlow4D 的设计目标包括四点:3D Spatial Awareness、End-to-end and Lightweight、Goal-Oriented、Plug-and-Play。

▲图| RoboFlow4D自适应地将流规划时间范围从当前状态调整到原子任务目标。©【深蓝具身智能】编译
这些目标共同指向同一件事:让机器人能够在三维 空间中在线规划,并在执行过程中通过闭环反馈不断修正。
RoboFlow4D 想提供什么?
RoboFlow4D 的核心输出是3D Flow:也就是未来多帧的三维运动轨迹。
模型本身是一个 4D World Model,因为它在 3D 空间中建模随时间演化的运动。相比只在图像平面上预测 2D 轨迹,3D Flow 更贴近真实机器人操作,因为它保留了深度、空间结构和时序变化。
更重要的是,RoboFlow4D 不依赖复杂的多阶段视频生成管线。
现有一些 3D Flow 方法通常需要先生成 未来视频,再经过深度估计、分割、点跟踪和 3D 重建等多个模块,才能得到三维运动先验。这类方法表达能力强,但端到端延迟高,难以支持机器人实时闭环控制。
RoboFlow4D 选择了一条更直接的路线:
用一个端到端轻量模型,从 RGB 图像和文本指令直接预测未来多帧 3D Flow。
这样,3D Flow 不再是离线后处理结果,而可以成为机器人在线执行时随时调用的规划信号。
方法概览
RoboFlow4D 整体由三个部分组成:
4D World Model:从视觉观测、语言指令和可选查询点中提取多模态条件,并预测未来 3D Flow。
3D-Flow-conditioned Action Policy:将 RoboFlow4D 预测的 3D Flow 作为显式条件,辅助动 作策略生成 action chunk。
Closed-loop Control:在执行过程中反复观察、规划、行动,让机器人根据最新状态更新 3D Flow plan。
这个设计使得 RoboFlow4D 不只是一个预测模型,而是一个可以接入真实机器人系统的轻量规划模块。
核心关系:从观测到3D Flow,再到动作
RoboFlow4D 不直接替代动作策略,而是在语言目标和连续控制之间插入一层显式的三维运动先验。
模型先预测“机器人接下来应该在 3D 空间里怎么走”,动作策略再把这条 3D Flow plan 转成具体动作。
这个核心关系也是 RoboFlow4D 被称为 4D World Model 的原因:它建模的不是单张图像里的静态位 置,而是三维空间中随时间展开的运动过程。
关键设计一:端到端预测 3D Flow 运动先验
传统模块化方法把 3D Flow 的生成拆成多个专家模型,每个模块都可能带来误差和额外计算开销。
RoboFlow4D 则把未来运动建模压缩到统一网络中,直接学习从当前观测到未来 3D Flow 的映射。
(1)首先编码 RGB 图像序列、语言指令以及可选的 2D query points;
(2)然后通过扩散式 FlowDiT 在多模 态条件下预测未来 3D Flow;
(3)最终输出的是一组多帧 3D 点轨迹,可作为后续动作策略的显式规划提示。
这种端到端设计带来两个直接好处:
减少对视频生成、深度估计、分割和点跟踪等外部模块的依赖;
将 3D Flow 预测延迟压缩到机器人闭环控制可以接受的范围内。
关键设计二:让纯视觉模型具备三维意识
机器人操控发生在 3D 空间中,但 RoboFlow4D 的主要输入是 RGB 图像。
为了缓解纯视觉输入带来的 空间歧义,RoboFlow4D 引入了 3D-aware representation learning。
具体来说,模型设计了一个 3D Perceiver 模块,并利用 3D foundation model 提供的几何特征作为教 师信号。通过特征对齐,RoboFlow4D 在训练过程中学习到更具空间结构的视觉表示。
这使得模型即使不显式依赖 RGB-D 输入或完整三维重建,也能形成对场景几何、机器人运动和物体交互 的更强理解。

▲图| 数据生成流程。©【深蓝具身智能】编译
关键设计三:面向原子目标的 3D Flow planning
很多机器人任务并不是一步完成的。
比如“打开抽屉,把红色方块放进去,再关上抽屉”,可以自然拆解为多个阶段:接近抽屉、拉开、抓取、放置、关闭。
RoboFlow4D 不强行预测固定时长的未来动作,而是围绕当前原子任务目标预测 goal-oriented 3D Flow。
换句话说,模型关心的是“从当前状态到当前阶段目标,机器人应该如何运动”。
为了学习这种阶段性规划能力,RoboFlow4D 在数据构建中利用 gripper 状态变化来划分原子任务,并围绕每个原子目标采样关键帧 3D Flow。
这样得到的监督信号更贴近真实操作中的阶段性决策,也让模型更容易在闭环执行中重新规划。
关键设计四:低频规划,高频执行
RoboFlow4D 与动作策略组合成一个 slow-fast 机器人系统。
在这个系统里:
RoboFlow4D 是低频规划器,它根据当前观测生成一个较长跨度的 3D Flow plan;
动作策略则是高频执行器,它根据该 3D Flow plan 输出多个连续 action chunk。
这种设计避免了每个控制步都调用规划模型的高成本,同时保留了闭环更新能力。当机器人抓取失败、 物体移动或当前状态偏离预期时,系统可以重新观察场景并生成新的 3D Flow plan,引导策略回到正确的操作路径。
实验表现
RoboFlow4D 在仿真和真实机器人任务上进行了验证。

▲图| RoboFlow4D 的真实机器人实验平台与任务设置。©【深蓝具身智能】编译
LIBERO成功率(%)
在仿真环境中,RoboFlow4D 可以作为 plug-and-play 的 3D Flow guidance 模块接入不同基础策略。在 LIBERO 上,DP 和 DiT 接入 RoboFlow4D 后平均成功率分别提升 6.2 和 4.0 个百分点。


真实机器人实验:成功率(%)/完成时间(秒)
在真实机器人实验中,RoboFlow4D 覆盖了 Pick-and-Place、Stack、Assemble 和 Drawer 等任务。接 入 RoboFlow4D 后,DP 和 DiT 等动作策略在平均成功率和任务完成时间上均得到改善。以真实实验平均结果为例:DP 接入 RoboFlow4D 后成功率提升 12.5 个百分点,平均完成时间减少 1.4 秒;DiT 接入 RoboFlow4D 后成功率提升 11.3 个百分点,平均完成时间减少 1.2 秒。

在延迟方面,RoboFlow4D 的单次 3D Flow plan 推理约为 0.68 秒。相比依赖视频生成和 3D lifting 的 分钟级模块化 3D Flow 方法,它更适合实时机器人系统中的在线规划和快速修正。
可视化:把机器人的“下一步意图”画出来
RoboFlow4D 的一个重要优势是可解释性。它不仅告诉策略该输出什么动作,还显式预测未来 3D Flow,让我们可以看到机器人预期的运动路径。

▲图| RoboFlow4D 在连续任务阶段中预测的 3D Flow,可直接展示机器人下一步运动意图。 ©【深蓝具身智能】编译
在真实机器人可视化中,RoboFlow4D 能够为连续原子任务生成清晰的阶段性 3D Flow。
更有意思的是,在抓取失败等异常情况下,模型可以基于新的观测重新预测 corrective 3D Flow,引导机器人重新对齐并完成二次抓取。

▲图| 当执行出现偏差时,RoboFlow4D 可以基于新观测重新生成 corrective 3D Flow,引导机器人恢复并 继续完成任务。 ©【深蓝具身智能】编译
这说明 RoboFlow4D 学到的不只是静态轨迹模板,而是一种可以随状态更新的三维运动先验。
为什么机器人需要先规划再行动?
对于通用机器人操控来说,仅仅提升动作模型规模并不一定能解决所有问题。机器人需要在真实三维世 界中与物体交互,很多失败都来自对空间、时序和阶段目标的理解不足。
RoboFlow4D 提供了一种中间层思路:在高层语言目标和低层连续动作之间,引入可解释、可复用、可 闭环更新的 3D Flow planning interface。
它让机器人操控从“直接猜动作”更进一步,走向“先预测三维运动,再生成动作”。
总结
RoboFlow4D 的主要贡献包括:
提出轻量级端到端 4D World Model,直接从 RGB 观测和语言指令预测未来多帧 3D Flow;
通过 3D-aware 表示学习,将三维几何先验注入纯视觉 3D Flow 预测模型;
设计面向原子任务目标的 goal-oriented 3D Flow planning,提升长程任务中的阶段性规划能力;
构建 slow-fast closed-loop control,让低频 3D Flow planning 与高频 action execution 协同工 作;
在仿真和真实机器人任务中验证了其对成功率、执行效率和实时部署潜力的提升。
RoboFlow4D 表明,显式三维运动先验可以成为连接视觉语言理解与机器人动作执行的重要桥梁。
对于未来实时、稳定、可解释的机器人操控系统,这种 3D Flow planning interface 提供了一条值得探索的路线。










