资讯

PNAS:新型软体机器人遇水变形,游泳速度提升780%,可滚动、爬坡并牵引重物
关于PNAS:这种软体机器人会“遇水变形”,游泳速度暴涨780%,还能滚动、爬坡、拉重物的文章


影禾医脉联合北京天坛医院发布全球首个全疾病覆盖颅脑CT辅助报告大模型
首都医科大学附属北京天坛医院与影禾医脉联合发布了全球首个全疾病覆盖的颅脑CT辅助报告大模型“小君医生2.0”。该模型基于海量高质量影像数据及AI Agent技术架构,实现了从影像解析到诊断报告生成的全流程自动化,标志着AI辅助诊断从单纯的病灶识别进化为具备临床思维的报告生成,显著提升了神经影像诊断的精准化与标准化水平。

谷歌DeepMind推出解耦式DiLoCo:优化异步训练架构 可容忍硬件故障
本文介绍谷歌DeepMind推出的解耦式DiLoCo分布式训练架构,该架构通过将训练任务分散到异步计算孤岛,解决传统同步训练易受单点硬件故障影响的问题,可大幅降低跨数据中心带宽需求,具备自愈能力且支持异构硬件协同,有效提升大模型训练效率与鲁棒性。

乒坛的阿尔法狗来了?索尼AI机器人击败职业选手
本文介绍索尼研发的乒乓球AI机器人Ace击败人类职业选手,创下实体竞技运动机器人新里程碑。文章详解其技术架构、比赛表现,同时提及国内人形乒乓球机器人、马拉松人形机器人的相关进展,探讨实体运动AI机器人的技术突破与未来应用潜力。
DeepSeek-V4发布 性能直逼顶级闭源模型 百万上下文定价1元起
关于DeepSeek-V4 发布!性能直逼顶级闭源模型,百万上下文 1 元起的文章

DeepSeek-V4预览版正式发布:1M超长上下文能力面向全员普惠
DeepSeek正式发布并开源DeepSeek-V4预览版,标志着1M超长上下文进入普惠时代。该系列分为Pro与Flash双版本,通过创新的DSA机制大幅降低长文本处理成本。模型在Agent协作、代码生成及逻辑推理性能上表现卓越,支持动态调节思考强度,不仅在性能上直逼顶级闭源模型,更通过技术突破加速了AGI的普及进程。

Soul 开源实时数字人生成模型SoulXFlashTalk 实现亚秒级延迟
本文介绍Soul AI Lab开源业内首个14亿参数实时数字人生成模型SoulXFlashTalk,该模型可实现亚秒级延迟与32帧高帧率,开放相关资源能有效降低行业研发门槛,此举完善了Soul“语音+视觉”双模态开源布局,未来将持续推进开源战略,推动AI与社交等多领域的创新发展。

腾讯发布并开源全新AI大模型混元Hy3 Preview
腾讯于4月23日发布并开源全新大模型混元Hy3 preview,作为混元重建后训练的首个模型,也是当前系列最智能版本。该混合专家模型具备2950亿参数、256K超长上下文,强化复杂推理、指令遵循、代码处理与智能体能力,并已在腾讯云、元宝、QQ等多平台首发,后续将扩展至更多产品以提升智能服务体验。

《Science Robotics》重磅:科学家让机器人学会削皮,实现复杂曲面通用任务迁移
本文介绍了发表在《Science Robotics》上的一项前沿研究:科学家提出“扩散方向场”方法,攻克了机器人在复杂曲面上执行任务的难题。该技术通过将任务动作与物体几何形状解耦,使机器人能像人类一样在不同形状的物体(如香蕉、梨等)上实现通用的技能迁移。这一突破极大地提升了机器人在非规则表面操作时的灵活性与鲁棒性,是机器人通用技能学习领域的重要里程碑。

腾讯混元重建后首次发布并开源Hy3 Preview:主打全面实用性,Agent能力大幅提升
关于混元重建后首发并开源 Hy3 preview:主打全面实用性,Agent能力大幅提升的文章
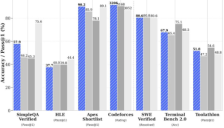
腾讯发布最新开源语言模型 Hy3 Preview,聚焦智能时代应用趋势
腾讯正式发布混元系列最新开源模型 Hy3 Preview,总参数量达295亿并支持256K超长上下文。该模型在复杂推理、指令遵循和代码处理等核心能力上显著提升,已广泛应用于元宝、QQ、腾讯文档等产品。此外,腾讯云同步推出了极具竞争力的API价格体系和定制化套餐,旨在通过高性能、高性价比的AI方案,助力开发者和企业在多样化场景下实现智能化升级。
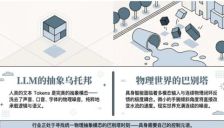
超越VLA与世界模型:解析GEN-1、Being-H0.7与π0.7的架构演进与共性路径
本文深入解析了2026年涌现的具身原生模型新浪潮,重点探讨了GEN-1、Being-H0.7、π0.7及GR00T N1.7等前沿架构的进化。文章指出,具身智能正摆脱传统VLA与世界模型的局限,通过UMI设备、人类第一视角视频等原生数据实现规模化增长。通过对比隐式空间对齐与显式多模态调节等不同路径,揭示了行业在异构数据处理与物理世界理解上的突破,标志着具身智能正式进入原生时代。

机器人数据困局怎么破?一文拆解Sharpa全栈数采布局
本文深入拆解了Sharpa公司在机器人灵巧操作领域的数据采集布局。针对高自由度机器人面临的数据采集难题,文章重点介绍了Sharpa如何通过DexEMG技术利用表面肌电信号(sEMG)实现高效的闭环遥操作。通过对63个自由度的精准控制与系统性解法分析,文章揭示了Sharpa如何突破传统仿真与数采的瓶颈,为具身智能实现高质量示教数据规模化生产提供了前瞻性的技术路径。

自变量WALL-B以世界统一模型架构解锁进入家庭能力
本文深入探讨了自变量机器人推出的新一代具身智能基础模型WALL-B。该模型摒弃了传统的VLA架构,采用全球首创的世界统一模型架构(WUM),实现了视觉、语言与动作的原生多模态融合。通过重构底层逻辑,WALL-B赋予机器人如同人类般的“下意识”行为能力与原生本体感,使其能深度理解物理规律并实现跨场景能力迁移。这一技术突破标志着具身智能正从表象模仿走向本质理解,为机器人真正走进家庭生活奠定了坚实基础。