2026年了,我们还在用爱迪生试灯丝的方式评估世界模型
上个月,五源信号站5Hz第一期活动还在对Sora的“死亡”究竟意味着什么进行讨论。然而在今天,多模态几乎已经从AI热点方向的语境当中消失,而World model则成为最受关注的下一个战场:其中不仅学术界在密集地发布论文,工业界也在真机上开展验证工作,投资人则在追问这条赛道到底是否存在Scaling Law。
World Model领域所呈现出的三种“未来”路径——生成派、JEPA派以及空间智能派,它们所押注的其实并非同一个AGI。它们的终局,有可能会发展成为一场关于压缩比所进行的效率竞争。
以下内容,是对五源信号站5Hz第二期活动内容开展了提炼以及整理之后所形成的结果。
如何严肃界定World Model
1. World model这一术语在具身领域中存在着大量混用的情况。一种比较严格的区分方式在于判断它是否真正做到了action-conditioned(动作条件化):如果只是把video prediction(视频预测)作为一个辅助loss,添加到action学习过程当中,让模型在预测action的同时,顺带对接下来一段时间的视频画面进行预测,那么它的输入并不是真正的action-conditioned,而只是在借助video prediction来增强表征能力。
另一种更具原教旨主义特点的定义方式在于,world model必须要能够接收action作为输入条件,例如当机器人接下来执行往左移动或者往上移动的操作时,这个世界会随之产生怎样的状态变化;或者在游戏环境当中,键盘W/A/S/D指令的输入会如何导致世界状态发生相应变化。只有当模型能够接受action输入并且据此对状态变化开展预测的时候,它才应该被称作action-conditioned world model。

2. 但是与其对到底什么是world model开展争论,不如首先回答一个更为根本的问题:你希望借助world model来达成什么样的事情?目的会反过来对模型进行定义,对技术路线进行定义,也最终决定了benchmark。
在具身场景当中,最核心的追求在于让world model得以直接生成决策,并且直接在现实世界中开展行动。它与VLA这类直接行动范式之间的区别在于:在执行行动之前多了一层对于世界的想象——如果我这样进行了动作,那么世界将会发生怎样的变化?这种multi-step reasoning ability(多步推理能力),才是world model真正区别于其他模型的核心。
3. World model 并不只局限于具身智能。如果把视角拉远一些来看,AlphaGo 里面的 value network(价值网络),本质上也是一种 world model。你输入一个 action 进来,它会对棋盘状态产生 disturbance(扰动),然后 predict 下一步的局面会如何演变,再给出对应的打分。
在生物领域当中所建立的虚拟细胞同样可以视为world model,当你向其输入一种药物的时候,它会预测该药物对人体细胞层面所产生的影响。自动驾驶领域内的仿真系统同样如此,它属于deterministic(确定性)的类型而并非generative(生成式)的类型,但是它所发挥的作用正是对那个世界的prediction。两者之间的区别仅仅在于,传统仿真系统的泛化能力显得过于有限,它所能够实现的事情是设计者事先想到了所有内容之后才能够设计出来的prediction。
而在当前阶段,目标是让world model能够真正capture the world,而非仅被设计者自己脑中的思考边界所限制。从这一视角来进行观察可以发现,world model实际上代表着从“确定性”走向“概率性”的一个重要跃迁过程,从而得以建模那些连设计者自己都未曾预想到的未来。
4. 最终,对于world model的严肃界定,可以收敛到一个公式当中:它作为一个predictor(预测器),会对状态从S到S'在action条件之下所发生的变化进行预测。
剩下的一切分歧,其本质上是对三个核心问题的不同回答:究竟什么是state?predictor应当如何设计?action应当如何表达?State可以是像素级别、可以是latent形式、可以是3D几何结构、可以是细胞里的一组分子状态。Action可以是机器人末端的位姿、可以是键盘的W/A/S/D、可以是latent action、甚至可以是一句自然语言指令。
正是这三者所采取的不同组合方式,会直接决定出所形成的技术路线以及对应的应用场景。
Morgan Stanley近期的研报中也给出了一个类似的通俗定义:world model本质上是一个“想象力引擎”(imagination engine),它能够对当前世界状态开展模拟,在假设条件下来进行向前推演,并将模拟得到的结果暴露给Agent或者人类去加以使用。(Morgan Stanley Research, World Models: AI's Journey from Digital to Physical)
Language model 依托于碳基生命的长期积累——碳基生命所完成的任务在于对信息开展抽象、表征以及理解的工作,language model 正是以这一基础来建立自身体系。如果 language model 代表了“有了语言之后的智能”,那么 world model 需要实现的目标,便是代替整个生命过程来对世界中声、光、电这些原始信号进行总结。
5. World model的终极形态可能是一种world intelligence:它与语言推理、下棋以及搜索属于不同类型的智能。人类将触觉、听觉、嗅觉以及视觉最终都转化成为文字,而文字对于人类来说是良好的state,然而对于机器人来说却未必如此。一个真正具备world intelligence的系统,需要去为五感信号寻找到更好的representation space(表征空间,即模型对世界开展内部抽象所使用的空间),而不是将一切都转化成为文字。这也正是representation(表征)可能成为world model在今天最困难且最核心问题的原因所在。
三条技术路线,各押不同的AGI
6. 当前的world model可以粗略地分为四条技术路线。它们背后所押注的核心假设各不相同,所擅长的东西也有所不同,命门也互不相同。
。
第一派属于生成模型,以 Sora 或类 Sora 为代表,也包括 Genie 以及 Decart。这一派的前身是 Midjourney、Stable Diffusion 这类图像生成产品,从 image 自然延伸到 video。但早期 video generation model 本质上更像是对 image 开展线性外推,生成出来的内容可能是一个人进行一些轻微动作,画面很漂亮,但缺乏长程逻辑。它们的需求是画质和美学,是 text following(文本跟随)能力,这与今天 world model 需要的抽象与逻辑是完全不同的需求层面。Genie 和 Decart 尝试向其中融入了 autoregressive 成分,让秒与秒之间有串联,但从效果来看,当时间尺度从秒级拉到小时级的时候,这些模型依旧很弱。
第二派为JEPA(Joint Embedding Predictive Architecture),它由Yann LeCun提出并加以推动。JEPA的核心方法论在于对隐空间(latent space)进行压缩以及抽象:它并不尝试去预测每一个像素,而是预测更高层次的表征(representation),在这个representation之中摒弃无关紧要的噪音,从而只保留那些对理解世界变化而言真正重要的信息。
从方法论层面来进行分析的话,这个目标是十分值得欣赏的。但是在具体的method设计方面,对比学习以及mask model(掩码模型)的融合在实践过程中所达成的效果目前仍旧不够令人满意。从Meta以及LeCun本人讨论这个具体路线时所付出的着墨程度来看,他们的内部可能也正在对这条路线开展重新思考的工作。LeCun已离开Meta去创立AMI Labs,拿到了10亿美金想要对这个方向的scaling工作进行推进,但结果如何仍然需要时间来加以验证。
第三派属于空间智能,它以World Labs作为代表,从3D几何结构出发来进行建模。这一派的思路在于首先构建好XYZ,先把三维空间的建模工作完成好,也许未来再加入时间T从而变成XYZt。但今天还没有把时间引入,这使得它在时间建模方面处于最初级的阶段。
而world model拥有一个不变的核心,它始终在对时间上的状态转移(transition)开展建模工作。无论输入是什么、action处于输入还是输出位置,时间t都是那个最底层的维度。其他路线已经在做XYT(视频)或XYD(带深度信息的视频),World Labs还在XYZ,所以它必须思考如何把T引入进来。当然,这一派在落地方面可能有优势,比如做mesh(三维网格)生成、做3D资产,这些不需要时间维度也可以产生价值。
7. 目前已经在真实车辆上得到充分验证的是第一派技术路线,而第二派也就是JEPA的latent rollout虽然在理论上具备上限优势,但是至今还没有被成功实现出来。在一段式端到端的自动驾驶范式之下,第一条路线也就是生成式co-training协同训练已经被验证是能够有效工作的:训练阶段会把video prediction加入进来开展co-training协同训练,从而增强backbone主干网络的表征能力,但是在推理阶段则会把video generation部分去除掉,以便满足实时性要求。JEPA的latent rollout在隐空间开展推演的方法在理论上限上可能会取得更好的效果,如果能够把所有表征都拉到隐空间当中来进行长程rollout,那么对于长程任务将会拥有非常大的潜力。但是在实际实践过程中,目前还没有人能够做出与第一条路线一样好或者更好的效果。
8. 有一位研究员提出了一种比较激进的观点,他认为JEPA是所有人都相信其正确性、然而却没有任何一个人能够真正将其实现出来的一种幻梦。V-JEPA World Model在最新发布的最优秀paper当中,最终所实现的也只是Push-T这类依靠MLP模型就能够顺利跑通的小型任务。而在Veo 3团队方面,当他人询问他们如何取得这样出色的效果之时,他们的回答仅仅只有两个字:diffusion(扩散模型)加上scaling。
(字数控制符合要求,段落结构一致)

与此同时,视频生成领域也正在发生着架构层面的变动:根据讨论过程中所提及的非公开传闻,Veo 3的多模态联合生成团队可能已经完成了拆分工作并入到了Omni team,而Sora 2也在公开尝试将AR以及diffusion混合在一起加以运用。但这些内容都更像是multi-modal generation model(多模态生成模型),距离真正的world model还存在着很大距离。
无论生成的画面多么精美,它本身也并不具备任何实质意义。我们真正所想要实现的是:如果我把杯子推倒,它将会倒到我身上,我会因此跳起来并且情绪破防,所以借助从结果来开展倒推,我认识到不能做出这么没素质的事。这种具备长程因果推理的能力,才是world model和video generation的本质分水岭。
9. 如果将这三条路线放在一起进行考察,world model本质上所呈现的便是一场关于效率的比较。假设我们拥有无限规模的模型、无限数量的数据以及全地球的电力全部用来运行world model,那么任何一条路线都能够scaling出一个无敌的世界模型,但现实的问题在于我们并不拥有如此充裕的资源。

在机器人层面,末端最多只能部署一个7B的模型,延迟要求被严格控制在50-100毫秒以内。在这个约束之下,架构范式的核心问题就在于:谁的压缩比更高?谁能够运用更少的参数、更少的计算量,将更多关于物理世界的知识压进模型?符合Bitter Lesson的那条路线,最终会在这场效率竞争中胜出。
世界模型开展推理工作目前所需要的成本确实很高。据 The Information 报道内容,Odyssey 运行其世界模型时每一位用户都需要占用一整张 H200 芯片来进行操作,这使得成本达到数美元每小时,而运行一个 70B 文本模型则只需花费几美分每小时即可。MoE Capital 的综述同样指出,Genie 3 的运行成本大约在 100 美元每小时。这些数字让“压缩比”这个问题变得格外紧迫。
10. 这几条路线并不一定是在同一个赛道里展开竞争。更有可能的情况是,它们会在应用场景上逐步实现分化:3D路线最后可能会专注于游戏引擎和数字资产的制作;生成式模型则可能更适合进行内容创作;而对于物理世界表达要求最为严格的机器人场景,则可能需要采用一种特殊的混合架构——比如一个20B的编码器(encoder)再加上一个5B的预测器(predictor)。
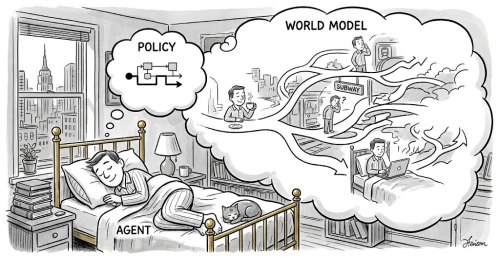
一种更为本质的理解方式在于:world model 所对应的是梦境,policy 所对应的是策略,agent 所对应的是做梦的人。做梦的人开展行动之后,梦境会做出回应;梦境做出回应之后,做梦的人则会继续开展行动。而 action 则是绕过传统仿真计算成本的“作弊码”,在传统引擎当中,模拟成本会随着物体数量以及互动复杂度而急剧上升,因此场景越复杂引擎就会变得越慢;但 world model 在训练过程中,就会把世界的运行模式吸收进入权重里面,使得推理过程转变为一次固定成本的前向传播,场景再复杂也不会让 engine 出现急剧变慢的情况。
Benchmark:评估世界模型为什么比评估LLM难得多
世界模型开展基准评估工作目前所面临的难度确实比LLM要高得多。这是因为据相关研究报道内容显示,LLM主要依赖于下一个token预测准确率来进行衡量,其中每一次测试都可以借助清晰的ground truth快速完成操作,这使得评估过程维持在较低成本水平,而世界模型则需要对连续世界状态的长期演化进行验证,这直接导致评估复杂度以及资源占用都急剧上升。当前基准综述同样指出,世界模型的评估大约需要检验误差累积以及全局一致性等问题。这些因素让“如何构建可靠基准”这个问题变得格外紧迫。
这几条评估路线并不一定是在同一个赛道里展开竞争。更有可能的情况是,它们会在应用场景上逐步实现分化:视觉质量路线最后可能会专注于短期预测保真度以及视频指标的测量;一致性模型则可能更适合进行长时序连贯性的验证;而对于物理规律遵守要求最为严格的机器人场景,则可能需要采用一种特殊的混合架构,比如一个基于感知的编码器再加上一个规划成功预测器。
一种更为本质的理解方式在于:benchmark所对应的是对梦境稳定性的检验,world model所对应的是梦境生成机制,evaluator所对应的是清醒的观察者。观察者开展检验工作之后,梦境会接受全局审查;审查发现状态漂移之后,开发者则会继续开展针对性优化。而closed-loop evaluation则是绕过传统局部准确性指标的“作弊码”,在传统基准当中,误差会随着交互轮次以及场景复杂度而急剧累积,因此序列越长评估就会变得越不可靠;但如果world model在训练过程中把世界运行模式吸收进入权重里面,那么评估过程就可以转变为固定成本的稳定性检验,场景再复杂也不会让整个评价体系出现急剧失效的情况。
核心差异总结(供参考,非输出部分):LLM评估依赖局部离散预测,存在成熟标准化数据集;世界模型则需检验全局长期稳定性、因果一致性、物理合规以及闭环交互效果,传统指标难以捕捉复合误差与潜在漂移,导致新基准(如WBench)仍在快速发展中,且评估成本高昂。不同技术路线(生成式、3D、混合架构)需差异化评估维度,这与此前讨论的世界模型“梦境-策略-行动者”框架完全呼应。
11. 语言模型的 benchmark 形态相对单一,只要对 next token prediction 以及 few-shot 方面的工作进行处理就能够得以解决。但 world model 的任务形态天然更为复杂:state 是多模态的、action 是异构的、时间尺度跨越从毫秒到分钟,这使得 few-shot 在 world model 里比在 language model 里要难以实施得多,评估它的 benchmark 也相应地复杂很多。
12. 当前具身智能benchmark的设计方面存在两个典型问题:要么任务设计呈现“反人类”特征,比如要求机器人借助单臂完成踢足球这类动作,这不仅无法反映任何真实的操作需求,还完全脱离了人类日常行为模式;要么当任务设计贴近真实场景(例如让机器人在家庭环境中执行长时序复杂指令)时,包括Dreamer Zero和π0.5在内的所有前沿模型成功率最高也仅约22%。在这种“所有模型均表现不佳”的情况下,benchmark便失去了区分模型优劣的实际能力。一个优质的benchmark(比如Mandarin)应当优先面向人类常见的自然操作任务,借助合理设计避免单纯为难机器人,也不应仅为拍摄亮眼demo而局限于最简单的pick-and-place操作。
13. 从评测技术的角度来看,当前对世界模型开展评估工作存在三个主要方向,其中每个方向都存在自己的差距:让VLM直接开展理解工作(但是VLM所观察不到细节形变以及微妙的物理量变化情况),选用潜空间模型(例如JEPA)来进行latent距离计算也就是得出“surprise值”(但是latent本身并不具有解释性),选用像素级追踪技术(例如CoTracker)来开展运动分析工作(但是这一方法会被视角变化以及光线干扰严重影响)。这三种方式如果单独使用都不足够,需要把它们组合成为一个Agent系统来进行综合评测工作。但是这样的系统目前还不存在。
14. 长时间 rollout 操作如果不出现崩溃的情况就是一个关键的评估维度。如果世界模型能够支撑分钟级别的自主 rollout 过程而不发生崩溃,它就可以充当一个安全的 simulation(仿真)环境,从而替代真机上的 RL 训练工作。这意味着可以像大规模训练那样开展相关工作。
来源:2026年了,我们还在用爱迪生试灯丝的方式评估世界模型 | 具身研习社