

LoongForge 全链路优化 GR00T N1.6 训练,训练周期减半,吞吐提升至 2.3 倍

机器人大讲堂
针对 GR00T N1.6 VLA 模型在训练中出现的 IO 阻塞、通信开销过大以及算子调度低效等问题,百度百舸 LoongForge 对全链路进行了优化,最终成功实现了训练吞吐量2.3倍的提升,并将训练周期缩短了56.6%。
GitHub 地址:https://github.com/baidu-baige/LoongForge
PART 01
背景:探讨具身智能底座 GR00T N1.6 的能力跃迁及所面临的挑战
在人形机器人产业化进程不断加速的背景下,Vision-Language-Action(VLA)模型凭借其打通感知、理解到执行全链路的技术优势,已逐渐成为支撑人形机器人实现具身智能落地的核心技术路径。在众多具身智能基础模型之中,由NVIDIA推出的GR00T N系列开源模型,因其针对人形机器人场景进行了专门适配,已成为该领域具有高度代表性的核心技术底座,并被广泛应用于机器人的智能训练与研发实践。
2025年完成迭代升级的GR00T N1.6模型,在架构与动作生成范式上均实现了进一步革新,使得人形机器人的端到端智能控制能力得以大幅强化。该模型选用Cosmos-Reason-2B视觉语言模型来充任其多模态感知核心,同时引入由32层DiT构成的网络作为动作生成主干。它将机器人的第一视角视频、本体状态信息以及自然语言指令这三类输入,统一建模为一种共享的策略表征,从而能够实现感知、理解与动作控制这三者的一体化建模。
得益于深层DiT对长动作序列所具备的高精度建模能力,GR00T N1.6的智能控制效果得以大幅提升,但与此同时,模型的训练过程也呈现出了计算密集以及通信密集的双重高强度特征,使得训练成本与难度始终居高不下。
依据官方所公开的配置信息,其预训练阶段需要采用规模高达16384的全局批次(Global Batch Size),依托1024张H100 GPU来完成约300K步的训练任务;即便是仅开展下游任务的微调,单节点的训练也需要持续数天之久。数据IO层面所存在的阻塞、多卡之间的通信开销,以及训练调度低效等问题,共同导致了GR00T N1.6的训练成本居高不下,训练周期被大幅拉长,从而阻碍了模型的快速迭代。
PART 02
方案概览:LoongForge 全链路系统级优化
为进一步提升 GR00T N1.6 的训练效率,百度百舸团队基于其自研的开源全模态训练框架 LoongForge,对模型训练的完整链路开展了系统级优化,并对其进行了深度重构。
针对 VLA 训练场景所具备的特点,LoongForge 团队重点围绕"数据 IO 链路"、"通信-计算重叠"以及"训练调度"这三大方向开展了优化工作:
在数据处理过程中引入异步 Prefetch 预取机制,用以缓解因数据加载与传输延迟所引发的 GPU 空转问题;
基于分布式优化器,借助通信与计算之间的细粒度重叠(Overlap)机制,降低多卡间因同步等待所导致的额外开销;
通过适配 CUDA Graph,减少大量小粒度算子的 Launch Overhead。
与官方训练方案相比,LoongForge 成功实现了最高达 2.3 倍的训练吞吐提升,并且将整体训练周期缩短了 56.6%。那么,LoongForge 是如何进一步释放 GPU 算力、从而实现 GR00T N1.6 高效训练加速的呢?接下来,团队将系统地拆解其背后的核心优化思路与关键技术实现。
PART 03
深度揭秘:2.3倍提速背后蕴含的三大工程优化方案
为进一步充分释放 GR00T N1.6 模型所蕴含的训练潜力,该研究团队并未止步于单纯的参数层面调优,而是分别从数据 IO 链路优化、通信与计算过程的重叠策略,以及训练任务的调度机制这三个关键层面,着手开展了系统性的优化工作。
优化一:IO 链路优化 —— 异步数据 Prefetch
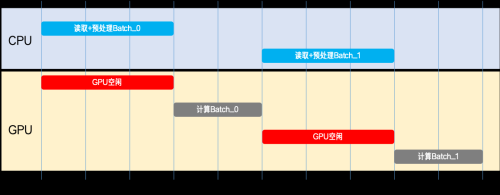
GR00T N1.6 的数据预处理过程涵盖了视频解码、图像增强以及多模态编码等CPU密集型操作。在Lerobot框架下,GPU会大量时间处于空转等待数据的状态,从而形成了典型的IO Stall现象。
Baseline:数据处理与 Forward 串行执行
LoongForge 借助三级异步流水线,成功实现了数据生产与 GPU 训练之间的解耦:
在第一级数据读取环节,多个DataLoader Worker被启动以实现从磁盘的并行数据读取,同时每个Worker还会额外预取n个批次的数据,从而减少因等待数据加载而导致的延迟。
Level 2 CPU预处理:由独立的Daemon线程负责执行图像、视频以及文本的预处理工作,并借助双缓冲队列实现与训练主循环的解耦,以此避免跨进程环境下的Tensor序列化开销。
在第三级优化中,GPU直接存储器访问(DMA)传输机制通过运用页锁定内存技术(亦称为Pinned Memory)以及非阻塞数据传输方式,使得GPU能够在一个独立的拷贝流(Copy Stream)上,以异步方式将数据从主存搬移至显存,从而实现数据传输与模型计算之间的完全并行。
在GPU执行当前批次计算的同时,下一个批次的数据正在传输过程中,更后续的批次正在经历预处理,而更远的批次则正在被读取,从而成功形成了完整的Pipeline Overlap。
优化后完整数据 pipeline
借助IO链路优化,GPU等待数据的时间得以显著压缩,IO Stall问题基本被隐藏。

优化二:针对通信与计算重叠的优化,借助 Megatron Distributed Optimizer 来驱动实现细粒度的通信重叠机制
在 Lerobot 框架之下开展 GR00T N1.6 的训练工作时,往往会面临以下几类典型的瓶颈问题:
In the Forward phase, one must wait for the computation of the current layer to be completed before pulling the parameters of the next layer, making it impossible to initiate the communication in advance.
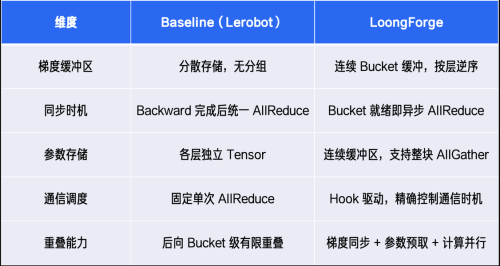
梯度存储方面存在分散问题,致使同步出现滞后现象:各层梯度均进行独立存储,无法依据 Bucket 逐步触发异步通信操作,导致 Backward 阶段完成后才触发 AllReduce 同步,使得同步与计算过程串行执行。
为了有效应对上述训练过程中所面临的瓶颈问题,LoongForge 运用了 Megatron Distributed Optimizer 技术,借助连续化梯度缓冲区管理以及基于 Hook 机制的通信调度策略,对参数同步、梯度归约与模型计算三者进行了深度融合,从而实现了细粒度层面的通信与计算重叠,能够有效地隐藏通信开销,并进一步提升训练吞吐。
Baseline 与 LoongForge 核心优化特性对比如下:
具体采取的优化措施包括:
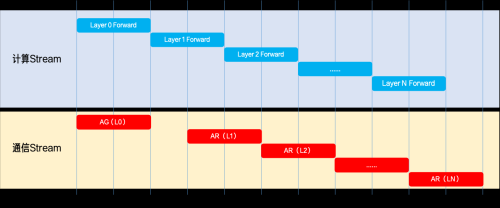
在 Forward 阶段的执行过程中,借助 Pre-hook 机制于 NCCL 通信 Stream 之上提前发起针对下一层参数所执行的 AllGather 操作,从而使得通信操作能够与当前层的计算过程实现并行执行。通过这一优化手段,总耗时得以从「Forward + Backward + 通信 + Step」优化为「Forward + max(Backward, 通信) + Step」,通信开销几乎被完全隐藏。
Forward 阶段逐层参数预取
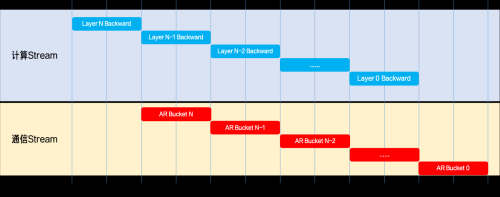
基于Bucket的梯度同步重叠机制:其核心在于,连续梯度缓冲区中的数据按照Backward传播的逆序进行排列。每当一个Bucket的梯度计算完成之后,便会立即在独立的NCCL通信Stream之上启动AllReduce操作,从而能够实现计算过程与通信过程的并行执行。在时间维度上,这一机制表现为计算Stream与NCCL通信Stream之间高度的并行关系。
Bucket 粒度通信-计算重叠
优化三:极致的训练调度优化——Per-Microbatch CUDA Graph for GR00T N1.6
Python 调度机制以及 GPU Kernel Launch 所产生的开销,往往是大模型训练过程中的隐形性能瓶颈。尤其是在 GR00T N1.6 这类包含大量小粒度算子的 VLA 训练任务当中,前向传播、反向传播以及 Loss 计算等环节均会触发大量细碎的 Kernel。如果完全依赖 Eager 模式来逐个进行 Launch,那么 CPU 调度开销会被持续地放大,GPU 利用率方面也难以获得充分的释放。
CUDA Graph 是 GPU 生态当中广泛运用的训练调度优化手段,其能够借助 Graph Replay 机制,对 Python 调度以及 GPU Kernel Launch 开销实现有效压缩。
LoongForge在此基础上,并未对通用的CUDA Graph流程进行简单复用,而是针对GR00T N1.6的真实VLA训练链路开展了进一步的适配工作。研究团队将训练过程中那些稳定且重复的Forward与Backward计算路径,纳入到了CUDA Graph的捕获范围之内,同时将诸如随机噪声采样以及动态输入处理等更适宜保留灵活性的操作逻辑,保留在了Eager执行路径之中。在此基础上,并结合了多Microbatch梯度累积以及DDP Overlap这两者的执行时序,重新对Graph的捕获与回放边界进行了划分,从而使CUDA Graph能够稳定地应用于GR00T N1.6的实际多卡训练场景。
CUDA Graph 执行模式对比:Eager VS. Full-Iteration VS. Per-Microbatch
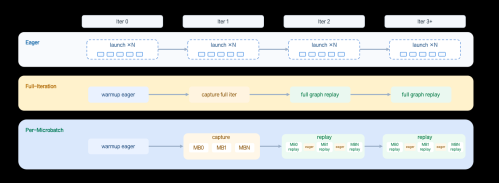
基于 LoongForge 框架,GR00T N1.6 的训练过程保留了 Eager、Full-Iteration CUDA Graph 以及 Per-Microbatch CUDA Graph 这三条执行路径,分别面向不同的训练阶段与应用场景:
Eager模式在全局层面未启用CUDA Graph的情况下运行,该模式可用于开展功能验证与Loss对齐工作,并能辅助进行动态图问题的排查,同时也适用于新模型或新数据形态接入训练流程的初期阶段。
Full-Iteration CUDA Graph:其具体做法是将单个完整Iteration内所包含的多个Microbatch的Forward/Backward计算过程以及随后的Grad Sync操作,统一封装并录制为一个CUDA Graph。运用此方式能够最大限度地降低CPU调度开销与Kernel Launch开销,因此更适合用于在验证场景中测试CUDA Graph所能实现的吞吐上限。
Per-Microbatch CUDA Graph:将捕获粒度进一步细化至Microbatch层面。在Capture阶段,并非固化整个Iteration,而是为不同Microbatch的Forward及Backward子图,分别生成更小的、可复用的Graph。在Replay阶段,则按照Microbatch的顺序复用这些Graph,并于最后一个Microbatch中保留梯度同步逻辑,从而继续兼容DDP Overlap机制。
相比 Full-Iteration 模式,Per-Microbatch 模式并未一味追求「更大的图」,而是把关注重点放在了「边界留对」之上:beta.sample、torch.randn 等随机数相关逻辑被保留于 Eager 路径当中,以此避免随机状态在 Capture 固化之后对 Loss 对齐造成影响;梯度同步点则被安置于合适的 Microbatch 边界处,从而确保 CUDA Graph 的优化不会破坏既有的通信与计算重叠节奏。
为了使CUDA Graph能够在GR00T N1.6的真实工作负载中稳定落地,研究团队针对视觉编码器、语言主干以及动作DiT等核心组件,开展了graph-safe改造工作,具体涵盖静态Buffer复用、固定Shape Padding、缓存位置编码与窗口索引、规避在Capture阶段发生动态内存分配,以及对部分不支持捕获的算子进行替换处理等措施,从而使CUDA Graph得以稳定应用于真实的多卡训练流程。
借助此项优化,GR00T N1.6模型的训练过程在多卡环境下实现了接近1.5倍的吞吐提升。Per-Microbatch模式在维持与Full-Iteration模式相近性能的同时,能够实现更优的Loss对齐效果,从而为GR00T N1.6的训练提供了一条更为高效且稳定的执行路径。
PART 04
性能实测:训练周期实现直接减半,整体时间缩短了56.6%
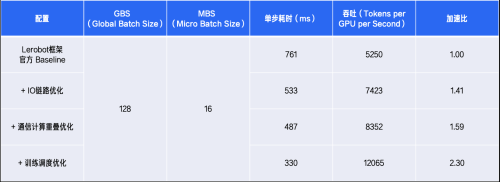
在8×A800(80G)计算节点上,运用Libero数据集对GR00T N1.6模型开展了训练测试。针对完整的训练任务,成功将整体训练周期缩短了56.6%,从而显著增强了模型的研发工作效率与实验迭代速度。
各优化阶段的性能对比如下:
PART 05
总结:提升 GPU 有效算力利用率
通过对训练调度、通信与计算重叠以及数据IO链路开展系统级优化,研究团队显著降低了Python调度方面的开销、通信等待时的空转以及数据供给的滞后现象,从而使GPU得以从"被动等待"状态转变为"持续计算"模式。最终,在不改变模型结构的情况下,成功实现了2.3倍的加速效果与56.6%的训练周期缩短,大幅提升了模型的迭代效率以及研发节奏。
目前,上述优化已被集成至全模态训练框架LoongForge当中。研究团队欢迎并邀请具身智能领域的研究者以及开发者,共同探索更加高效的VLA训练方案。
来源:训练周期减半:LoongForge 全链路优化 GR00T N1.6 训练,吞吐提升至 2.3 倍 | 机器人大讲堂










