卧安机器人CEO李志晨在谈及具身智能下一阶段竞争时说,核心在于“高质量真实世界数据的获取和利用效率”。
这句话看似老生常谈,但如果将它放在卧安切入的家庭具身智能场景以及技术架构里审视,背后或许是一条与主流VLA路线截然不同的逻辑。

具身智能行业正在经历一次认知分层。站在2026年中点往回看,过去十八个月里,全球涌现了数十家人形机器人公司,融资总额突破百亿美元,演示视频的精度和流畅度每隔几个月就会刷新一次公众预期。但真正能拿到客户订单、能在非结构化真实场景持续部署、能把数据闭环跑通的,屈指可数。
如果说,热闹的上半场,考验的是PPT和原型机;冷静的下半场,考验的是数据工程能力、场景积累深度,以及能把两者转化为模型迭代速度的组织能力。
聚焦家庭场景的卧安机器人,在五月连续打出的两张牌,罕见兼顾了落地和模型的突破。其近日以4495.32万元中标深圳市“AI生态创新社区设备购置与场地搭建项目”,为目前公开可查的家庭家务场景中最大规模的具身智能数据基础设施订单。
两天后,公司发布自研世界动作模型OneModel1.7 FrontoStria-RL,在标准评测基准LIBERO上以99%的平均成功率超越π0.5、GR00T-N1.5等主流模型,日常操作任务真机成功率同样达到99%。
当整个具身智能行业仍在争论VLA模型与世界模型谁更优越时,卧安已经建立一条从数据基础设施到模型训练的闭环,而4500万订单的本质,是它为自己铺设的家庭场景“数据飞轮”,也在累高这家企业的真正护城河。
01.
从商业化先行到基础设施延伸
家庭场景是具身智能最性感的叙事,也是最残酷的考场。为什么家庭场景如此之难?不是机械臂不够灵活,而是环境太不“规矩”。实验室里的桌面永远是干净的,灯光永远充足,物体位置永远固定。但在真实的家庭中,没有两间完全相同的厨房,没有两个摆放一致的桌面,每天的任务组合也在不断变化。机器人不仅需要精确完成开门、叠衣、端碗、收纳等具体动作,还需要面对陌生物品、变化光照、不同户型时仍然能够理解任务并做出合理行动。
这正是家庭场景数据采集难度远高于工业场景的本质原因。工业场景的变量是可控的,数据边际成本随着规模扩张快速下降。而家庭场景中,每多一个户型、一种光照、一件家具、一项任务组合,都可能引入全新的数据维度。据行业测算,全球机器人行业拥有的具身智能交互数据仅几百万条,而实际商业化所需的数据规模可能达到数千万甚至上亿条。家庭场景的数据缺口,在其中占据了相当的比例。
卧安此次中标项目的核心价值,尤其体现在家庭服务场景的数据基础设施建设上。家庭场景的搭建包含标准家庭单元和主题功能单元,覆盖客餐厨、卧室、卫生间、阳台等空间,围绕收纳、整理、取放、开合等高频真实生活任务采集数据。卧室里被子的叠法、厨房里锅铲的握持角度、阳台上的晾衣手势,这些在工业机器人的世界里不存在的“琐碎任务”,恰恰是家庭具身智能必须攻克的核心。

这也可以解释为什么家庭场景的数据资产有着独特的战略价值。工业场景的数据结构性强、可仿真度高,合成数据能够以较低成本覆盖大部分训练需求。但家庭场景的非结构化程度远高于工业场景,真正高质量的家庭操作数据,目前几乎只能通过真机在真实环境中采集。这种数据稀缺性本身就是一道天然的竞争壁垒。
卧安切入家庭具身智能这道难题的方式,不是通过烧钱堆硬件,而是试图利用商业化领先优势,把真实世界的部署规模转化为数据积累速度。公开信息显示,卧安机器人产品目前已覆盖全球90余个国家和地区。这个数字背后,是持续运转的真实场景数据采集通道,每一次成功的任务执行都是一条有效轨迹,每一次失败的尝试都是一个有价值的边界样本。这正是实验室数据无法替代的东西,其能获得更多真实物理接触的噪声、真实光照条件的变化、真实用户行为的随机性。
在这样的背景下,此次中标的深圳项目,是卧安在这条路径上的一次主动放大。因为该中标项目,本质上是一套具身智能数据工厂的系统集成工程。项目将配置卧安自研的onero H1移动双臂具身机器人、UMI数据采集终端、穿戴式遥操作数据采集系统,并同步建设覆盖多类真实应用场景的物理环境。

这意味着其不是一个展示用的样板间,而是一个可以规模化、可复现地产出训练数据的物理工厂。这套基础设施一旦运转,产出的将是覆盖真实家庭场景、经过系统化标注、可直接用于具身模型训练的高质量数据集。而这类数据,正是当前整个行业最稀缺的生产资料。
02.
数据荒漠里的“卖铲人”有多贵
具身智能的数据窘境已经不是什么秘密。大语言模型GPT-5的训练语料折合约100亿小时,而全行业汇聚的高质量具身数据仅约50万小时,差距以万倍计。人形机器人单条数据采集加工成本达50至500元,日均仅能产出200至1000条,而传统工业机器人单条成本不到1元,日均产出超过10万条。这就是整个行业正在经历的“数据荒漠”。
在此基础上,数据采集训练场却正在成为全国性“新基建”。据不完全统计,北京、天津、上海、郑州、无锡、苏州、成都等十余座城市均在2025年后启动或建成了具身智能数据采集训练场。QYResearch数据显示,2024年全球具身智能数据采集工厂市场规模约为7.53亿美元,预计到2031年将达67.52亿美元,年复合增长率36.8%。例如卧安不仅拿下了国内基础4500万的标杆大单,旨在建设一套家庭场景的训练场,更基于期在海外C端家庭市场的深耕,在海外悄然跑通了另一条更大规模的“商业化数据暗线”,形成了更大的数据飞轮。
为什么要做数据?自动驾驶给了具身智能行业一个足够清晰的参照系。Waymo自2009年开始积累路测里程,到2023年才在旧金山和凤凰城实现商业化运营。这十四年间,它积累了超过3200万英里的真实道路数据,以及远超这个量级的模拟数据。即便如此,仍有分析师指出,Waymo的核心壁垒不在于算法,而在于那套几乎无法被快速复制的数据采集、标注、训练和部署一体化体系。
但具身机器人的数据难度,在某些维度上高于自动驾驶。驾驶场景的状态空间相对有限:车道、路口、行人、信号灯,物理交互以感知为主。而卧安选择的家庭具身机器人面对的更是一个几乎无穷维的操作空间:每一间厨房的橱柜高度不同,每一只杯子的抓取位姿不同,柔性物体的形变几乎无法穷举,更不用说双臂协同、多步骤任务中的误差累积和容错需求,其难度更大,数据采集和飞轮更难。

斯坦福大学2024年的一项研究估算,训练一个能够在5类典型家庭场景中泛化执行的具身策略,至少需要跨越50个不同物理环境、覆盖超过10万条真实操作轨迹的高质量数据。这还是在场景设置相对标准化的前提下,一旦引入真实家庭的非结构化变量,数据需求量级将继续上升。数据的稀缺,从根本上制约了模型的泛化能力。这正是卧安布局家庭数据采集训练场的根本原因。
03.
OneModel 1.7:打通世界理解到动作执行的隐式通路
为了提高数据竞争力,除了搭建数据训练场,背后还需要具备把数据转化为模型能力的架构设计,这也是卧安真正让数据飞轮转起来的钥匙。
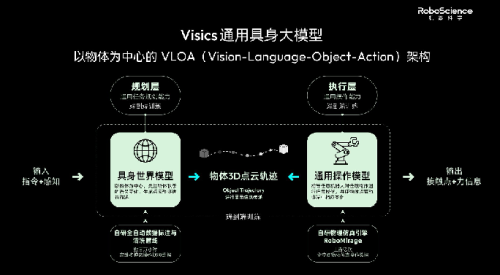
当前具身智能的主流模型范式,大体分为两条路线。一条是VLA(视觉-语言-动作)端到端模型,另一条是World Model路线。但卧安OneModel 1.7 FrontoStria-RL的RL-LWAM架构(RL-Latent World Action Model),则不同于两条路线,而是在于提出Predictive Policy Latent机制。
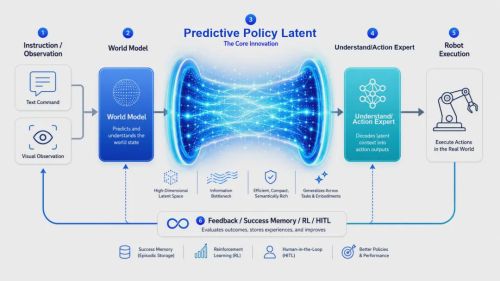
(OneModel 1.7 FrontoStria-RL 完整架构;Predictive Policy Latent 作为核心传导机制,连接 World Model、Understand Expert 与 Action Expert)
这是一种以面向动作策略的隐式表征,在高层世界理解和底层动作策略之间建立连接通道,取代传统方案对显式未来图像或目标坐标的依赖。这个设计消除了显式中间表征带来的生成误差和信息冗余,也解决了World Model与Action Policy之间长期存在的理解-执行断层。这样的设计有助于减少显式中间表征带来的生成误差和信息冗余,也在一定程度上解决了 World Model 与 Action Policy 之间长期存在的“理解—执行”断层问题。
RL-LWAM架构由三大模块构成。World Model负责跨场景泛化,Understand Expert负责任务理解与Skill调度,Action Expert负责精准执行,三者通过Predictive Policy Latent隐式连通。
在机器人大讲堂看来,OneModel 1.7 的技术价值主要体现在四个方面:
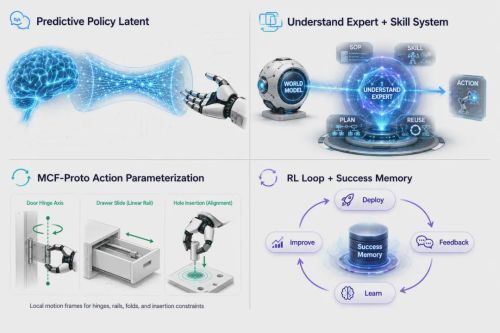
(OneModel 1.7 FrontoStria-RL 四大核心技术创新点)
首先,Predictive Policy Latent。以面向动作策略的隐式表征传递World Model的高层理解,取代传统方案对显式未来图像或目标点的依赖。这一设计消除了生成误差的累积,也避免了信息在转换过程中的冗余。
其次,Understand Expert + Skill系统。将复杂任务拆解为可执行步骤,并调度可复用的Skill模块。每个Skill是一个针对特定动作的专业能力,抓取、放置、旋转、推拉各有专长。简单来说,Understand Expert 负责告诉机器人“这件事应该怎么分步骤完成”,Skill 则负责把每一步具体做出来。
MCF-Proto。围绕门轴、滑轨、孔位、折叠线等局部运动结构组织动作表示,使策略对视角变化、初始位姿偏差和场景扰动保持更强的鲁棒性。家庭场景中,机器人的物理接触对象有规律可循,动作表示围绕这些规律组织,比围绕原始像素组织更具泛化能力。换句话说,MCF-Proto 让机器人不再依赖对固定坐标的“死记硬背”,而是学会理解物体背后的运动结构。抽屉怎么滑、柜门怎么转、衣物沿哪条线折叠,这些动作规律一旦被抽象出来,机器人就能在不同户型、不同摆放和不同视角下,更稳定地完成推拉、开合、折叠等家庭操作任务。
RL闭环 + Success Memory。这就是将强化学习与成功经验复用接入真实部署反馈,突破了“离线训练模型训完即用”的局限。意味着机器人每完成一次真实任务,无论成功与否,反馈信号都会回传给模型,能力随部署规模不断增强。
最后一项,其实就是理解前文中,卧安数据战略与模型战略为何构成协同闭环的关键。大规模真实场景部署积累的数据,通过RL闭环持续回流到模型训练,模型能力的提升进一步增强部署稳定性,更稳定的部署产出更高质量的数据。
简单说,这套架构试图避免“先理解再执行”的两段式割裂,而是让世界理解通过隐式通道直接作用于动作策略。这是一个正向循环,而启动这个循环的前提,恰恰又是真实商业化部署的规模和深度。
卧安的真机实测数据已经印证了这套逻辑的有效性,在具身智能标准评测基准LIBERO上,OneModel 1.7平均成功率达到99%,对比π0.5、GR00T-N1.5、OpenVLA-OFT等主流公开模型均领先。在真机实测中,日常操作任务(洗衣、叠衣,洗碗机操作、传送带拿取)成功率达99%,高精度任务(拔插试管、叠纸杯、倒咖啡豆)成功率达97%。
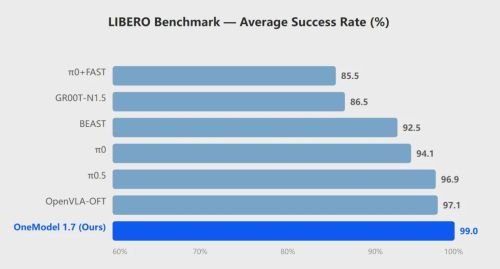
(标准 LIBERO 平均成功率对比)
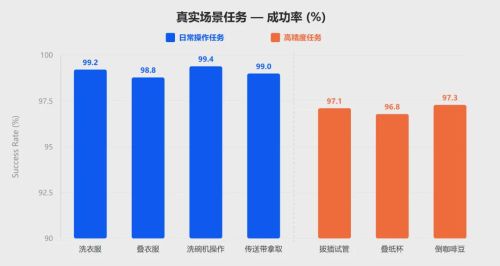
(日常操作与高精度任务真机验证)
数字说明了一定问题,而真正值得注意的是,这些数字对应的任务类型:柔性物体、多阶段流程、精细对准、真实接触反馈。这类任务正是家庭场景中最常见、也最难被机器人掌握的类别。
此外,机器人大讲堂注意到,卧安还在真人对打乒乓球的场景中验证了模型的高动态交互能力。乒乓球对实时感知、轨迹预测和快速动作生成的要求远高于日常操作,是具身智能系统综合能力的高强度测试。
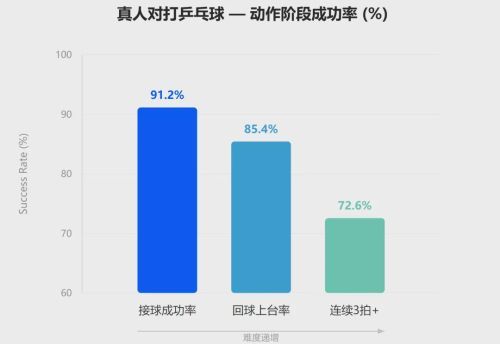
(真人对打乒乓球动态场景验证)

benchmark领先不等于真实场景可用,这是行业长期存在的数据可信度问题。很多模型在评测中表现优异,但在真实家庭环境中难以复现,原因是benchmark的任务边界相对固定,而真实家庭的干扰项更多、更随机。卧安这次选择直接上柔性物体和真实接触反馈,正是在弥合这个差距。
从行业角度看,OneModel 1.7 的意义不只是一次模型性能提升,而是指向具身智能从“专用任务模型”走向“通用世界动作模型”的趋势。只有当机器人能够把真实场景中的感知、规划、动作和反馈经验沉淀为可迁移能力,具身智能才有可能从实验室演示走向规模化部署。卧安这套“数据—模型—场景”闭环,本质上是在为家庭机器人构建可持续进化的底层系统能力。
04.
从模型竞赛到基础设施竞赛的行业拐点
具身智能行业有一个被反复低估的规律:技术代差很少靠单点突破建立,更多靠体系能力的持续积累兑现。
OpenAI在GPT-4之后并非因为某次模型架构创新而保持领先,而是因为其RLHF数据标注体系、人类反馈收集管道和安全迭代机制共同构成了其他玩家难以快速复制的系统。特斯拉FSD的核心竞争力,同样不在于单次算法突破,而在于数百万辆量产车形成的影子模式数据采集网络,以及把这些数据转化为模型迭代速度的自动标注和训练流水线。
具身智能行业正在走向同一个竞争逻辑,不少人发现,真正的门槛,是数据基础设施和模型训练体系的深度绑定。机器人大讲堂认为,在这个框架下,卧安的两步棋其实具有超出单一事件的战略意义。近4500万元的数据基础设施项目,既是一笔可见的商业收入,也是一套将在未来持续产出数据资产的物理网络节点。OneModel 1.7的技术发布,证明卧安有能力把数据优势转化为模型代差,而不只是停留在数据层面的积累,并把真实数据进一步转化为模型泛化、任务规划和动作执行能力。
两者叠加,勾勒出的是一家公司从“具身机器人制造商”向“具身智能数据-模型-场景一体化平台”演进的轨迹。这个演进方向,与整个行业从硬件驱动向软件和数据驱动的重心迁移高度同频。
05.
结语与未来
家庭具身机器人距离真正的大规模普及,仍有相当距离。但行业格局的雏形,正在被每一个数据基础设施节点、每一次真机部署反馈、每一轮模型迭代静静塑造。
技术演示可以在短时间内被复制,数据积累和场景工程能力的差距,需要以年为单位来弥补。
这或许才是卧安真正想说的事。