光轮智能被看见,不只是因为融资多,而是它切中了机器人持续学习的关键:数据采集、仿真放大、评测检验和部署反馈。
最近,光轮智能的融资消息一轮接着一轮。
3月,A++及A+++轮融资10亿元;5月,蚂蚁集团领投新一轮融资,估值被推到20亿美元;6月,又是一轮10亿元战略融资。这个速度放在具身智能赛道里,很难不被看见。
很多人会把它理解成:资本又盯上了一家具身智能的数据公司。
但我觉得,这件事真正重要的地方,是资本正在给“数据驱动的学习系统”定价。这是行业向前发展的一个新信号。
什么叫学习系统?
不是给机器人一次性喂一批数据,而是让真实世界里的经验能被采集,被仿真放大,被评测检验,再被部署反馈修正。说得更直白一点,就是让机器人形成“学习、考试、改错、再学习”的闭环。
过去两年,大家看机器人,先看本体,再看大脑。现在开始看数据和机器人的学习能力。
这才是光轮智能最值得看的地方。
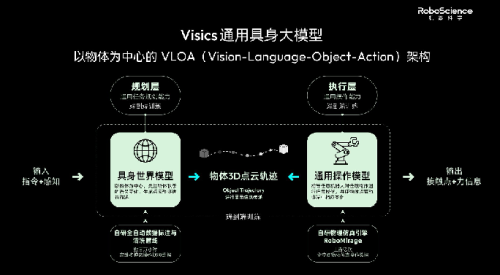
它不造机器人身体,也不直接做机器人大脑。它做的是机器人学习背后的那套基础设施:数据、仿真、评测、部署反馈。
一、光轮卖的是一套数据闭环
很多不太熟悉光轮智能的朋友,容易把它理解成一家“数据公司”,其实偏窄了。
传统数据公司的逻辑是:甲方客户提需求,乙方去采集、清洗、标注、交付。项目结束,价值也基本结束。
但在物理AI时代,光轮讲的不是这个故事。
它想做的是一个循环:真实世界里的人类操作和产业任务,先被采集成数据;这些数据进入仿真系统,被放大成更多训练场景;模型训练之后,再通过工业级评测找出失败原因;机器人进入真实场景后,现场反馈再回到下一轮数据生产里。
这不是提供数据,而是交付一套闭环的学习系统。
这也是为什么光轮一季度5.5亿元的订单值得关注。这订单背后,不只是模型公司、机器人公司采购数据,而是产业开始为这套闭环付钱了。
资本看中的也是这个变化。
3月那轮融资里,既有新希望、奥克斯这样的产业方,也有建投华科、国方创新这类财务和国资背景资本;5月蚂蚁集团领投;6月又引入中关村科学城基金、巨人网络、宝通科技等。
钱来自不同方向,但逻辑指向同一件事:具身智能不能只投本体和模型,还要投支撑机器人持续学习的数据系统。
一个行业什么时候真正走向规模化?不是Demo最热的时候,而是大家开始为底层能力付费的时候。
二、机器人没有数据红利
为什么现在轮到光轮这类公司被看见?
原因很简单:机器人没有天然的数据红利。
大语言模型有万亿规模的互联网文本,自动驾驶有超千万辆汽车的路测数据。机器人不一样,真机数据贵、慢、分散,还受本体数量限制。
更麻烦的是,机器人面对的是物理世界。材料、光线、摩擦等很难靠少量真机数据覆盖,变化也几乎无法穷尽。
所以,具身智能越往后走,瓶颈就越清楚:能不能稳定获得高质量数据,能不能复现评测,能不能把失败变成下一轮进步。
这也是光轮智能创始人谢晨一直讲“非本体数据”的原因。
所谓非本体数据,就是不完全依赖真实机器人本体产生的数据,比如人类行为数据和仿真合成数据。它的价值在于,绕开真机数量不足的问题,把机器人学习材料规模化。
但数据只是起点,真正值钱的是把人类数据、仿真数据和工业评测接成闭环。
这就是光轮和普通数据公司的差别。
三、它真的是“数据英伟达”吗?
也有人喜欢把光轮叫成“数据英伟达”。
我觉得这个说法很大,也很容易虚。但如果拆开看,它不是完全没有道理。
英伟达真正的护城河,不只是GPU。GPU是入口,CUDA是接口,开发者生态是网络,训练和部署工具链是基础设施。它最后厉害的地方在于,全行业都围着它的接口工作。
光轮想做的,是物理 AI 里的数据接口,或者更准确地说,是学习接口。
我们看它旗下的产品就明白了。EgoSuite提供人类行为数据,SimFoundry和SimReady把真实世界转成仿真训练场,RoboFinals负责评测,RoboStack把真实部署反馈带回来。
这几个产品,指向的其实是一件事:让机器人学习过程变成可生产、可测量、可复用的系统。
它的生态动作也在往这个方向靠。
比如英伟达把光轮列为Isaac Lab-Arena的核心共建方,提到其评测层和任务层由双方合作设计开发。这事的分量在于,它不是说光轮只是数据供应商,而是承认它参与了评测框架和任务体系。
还有一点更值得关注:光轮加入Newton技术指导委员会,和NVIDIA、Google DeepMind、Disney Research、Toyota Research Institute一起参与下一代物理AI仿真标准。
谁定义训练场,谁定义考试方式,谁就有机会影响行业怎么判断机器人有没有进步。
但它和英伟达也有明显不同。
英伟达有硬件壁垒,有CUDA多年沉淀出来的开发者锁定,有清晰的全球标准地位。
光轮现在还没有这么强的锁定能力。机器人行业本身还处在初期,客户需求分散,标准没有完全收敛,很多项目也都是高度定制的。
更关键的是,英伟达的护城河最终来自迁移成本。开发者、模型公司、云厂商、应用公司都围着它的工具链工作,换掉它,不只是换一块芯片,而是重写一套工作方式。
光轮要真正接近“数据英伟达”,也必须形成类似的迁移成本。
客户不是因为它便宜才用它,而是因为一旦训练、评测、仿真资产、部署反馈都接进光轮的系统,换掉它就意味着重新搭一套机器人学习流程。 这才是“数据英伟达”这个故事里最核心的部分。
所以,“数据英伟达”可以当成方向,不能当成结论。光轮现在更像是在争夺这个位置,而不是已经坐稳这个位置。
四、故事越大,硬题越多
当然,光轮这个故事越大,风险也越清楚。
一位做具身数据的创业者跟我说,行业现在最怕的不是没有数据,而是“数据看起来很多,但不知道有没有真的让机器人变强”。
其中,最显著的问题,还是仿真到现实的鸿沟。
仿真里能跑通,不代表机器人在真实工厂、仓库、家庭里就能稳定跑通。真实世界是非标准化的。光轮必须持续证明,它的数据和仿真资产不是看起来高级,而是真的能让模型能力提升、部署失败率下降。
另一个问题是,数据规模不等于数据有效。
光轮对外披露过几组数据:150万小时数据、25000多个环境、10万种任务。这些数字很亮眼。但客户最后不会只为数字买单。他们要的是任务成功率有没有提高和部署成本有没有下降。
具身数据行业下一阶段,一定会从“拼数据量”转向“拼数据有效性”。
还有一个更现实的问题:今天的客户未来可能变成对手。
头部机器人本体公司、模型公司,早期会买光轮的数据和评测能力,因为行业发展太快,自己来不及建。但从长期看,谁都知道数据闭环是核心资产。真正高价值的数据,尤其是失败样本和部署反馈,谁都想握在自己手里。
所以光轮要证明自己不可替代。不是因为它能采数据,而是因为它能把数据、仿真、评测和反馈组织成一套更高效的学习系统。
光轮智能现在站在一个很好的生态位上,但还没到可以轻松庆祝的时候。
它赶上了具身智能从Demo走向规模化的拐点,也抓住了机器人持续学习这个真问题。
但接下来,它要证明的不是自己会讲“数据英伟达”的故事,是自己真的能把真实世界的经验,变成机器人可学习、可评测、可复用的能力。
如果这件事成立,光轮就不只是又一家融资很快的独角兽。它代表的是一个新信号:谁更会学习,谁就更有机会被看见。
原文标题 : 光轮智能融资提速:机器人行业开始给“学习系统”买单了