具身机器人研究全都错了?最新论文:不能只靠VLA和世界模型
具身机器人研究难道都走偏了?最新论文指出:不能仅仅依赖VLA和世界模型
具身机器人的“GPT时刻”依然很远。
更多的机器人示范数据、更大的视觉-语言-动作(VLA)模型,以及更理解“物理定律”的世界模型,是否就足以实现“通才机器人智能”呢?
这正是当前具身智能所遵循的主流研究范式,但一篇刚刚发表在arXiv上的研究论文却得出了一个颇为直接的结论:这条路径并不可行。
在这篇立场论文中,来自具身智能数据初创公司 Motoniq 团队及其合作者,指出了当前VLA以及世界模型研究范式所存在的不足、真正物理智能所缺失的“四个组件”,以及面向物理世界可泛化机器人的未来研究方向。
论文链接:https://arxiv.org/abs/2606.06556
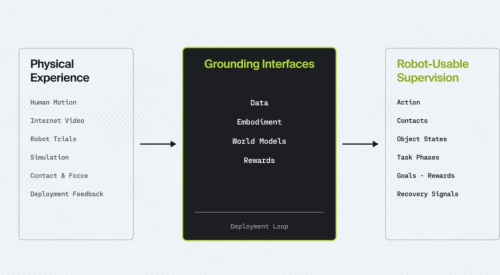
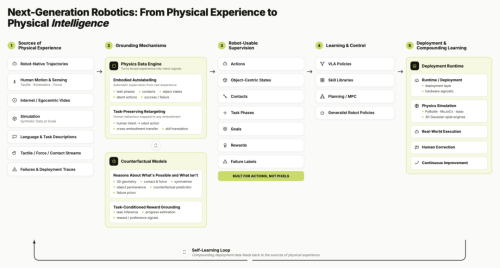
具体来看,通用机器人真正所欠缺的,并不只是规模更大的策略模型,而是一整套能够把非结构化的物理行为转化为监督信号的机制;只有将数据接口、具身接口、世界模型接口以及奖励接口这四个关键组件补齐,机器人才能够不再仅仅依赖示范数据,而是得以在更为广阔的物理世界当中持续学习。

图|从物理经验出发,转化为机器人可用的监督信号。
当然,这篇立场论文并不是认为 VLA 模型以及世界模型并不重要。恰恰相反,它们更像是整套物理智能系统当中的一个层次,而其背后则离不开数据、本体、动力学、奖励以及部署反馈等方面的支撑。
为什么说现有范式不完整?
研究团队指出,机器人原生监督、视频弱监督,以及仿真与世界模型,共同构成了当前具身智能研究所依赖的主要范式。
目前的进展和不足如下:
机器人原生监督的进展与不足
当前主流的机器人学习,仍然依赖于机器人能够直接学习的数据,诸如观测-动作轨迹、任务标签、语言指令以及成功信号。BridgeData V2、DROID、Open X-Embodiment 扩大了这类数据的规模,并为 OpenVLA、GR00T N1、Gemini Robotics 等系统提供了训练基础。
但最为有效的监督,依然来源于已经 grounded 的机器人轨迹。动作标签、任务描述以及成功/失败信号,要么在采集阶段被直接记录下来,要么在后期被补充齐备,VLA 的扩展至今仍然建立在预先整理完成的监督数据之上。
弱监督视频所包含的信息更为丰富,但却难以被直接加以利用
互联网上存在着大量的人类操作视频。这些视频可以展示任务是如何完成的、物体是如何运动的,以及接触会在何时发生,但却不能被直接转化为机器人可执行的动作。现有研究更多是把这类视频视作间接监督信号。R3M被用于视觉表示的预训练,VIP被用于对任务进度进行刻画,而LAPA以及UniVLA则尝试借助这类视频学习潜在动作,并将其映射到机器人控制之中。
但视频当中所包含的信息,并不能被直接用于机器人的学习过程,潜在动作并不等同于指令,进度信号也未必能够被直接转化为奖励,人类所采取的操作策略同样未必适用于特定机器人的具身形态。
生成物理经验:仿真与世界模型
受限于真实机器人数据采集的高昂成本,研究团队开始借助仿真以及世界模型来补充训练经验,目前相关进展也已经从 MimicGen、RoboCasa365、RoboGen 等数据生成方法,进一步扩展到 DreamerV3、V-JEPA 2 等控制与交互仿真探索,以及 ParticleFormer、ContactGaussian-WM 等面向点云与接触操作的建模工作。
不过,研究团队也进一步指出,现有世界模型仍然存在着较为明显的局限。除了生成逼真的未来画面之外,未来更为关键的方面在于,能否保留那些决定控制成败的物理变量,其中包括几何形状、物体状态、接触、力、稳定性以及材料响应。如果忽略接触、质量以及摩擦,那么预测结果即便在视觉上显得合理,也难以成为可靠的机器人监督信号。
物理智能缺失的四个组件
在对现有研究进行回顾之后,研究团队进一步指出,下一步研究的突破口未必在于更大的模型,而更有可能取决于这四个仍然缺失的关键组件:
1.物理数据引擎与具身自动标注
要让机器人得以利用更广泛的物理经验,首先所需要补上的,是一个“物理数据引擎”。当前的机器人学习在很大程度上仍然依赖于已经整理完成的训练样本,而人类视频、可穿戴传感器数据、工厂流程以及失败轨迹虽然包含着丰富的物理交互信息,却往往难以被直接转化为可用于训练的监督信号。
为此,研究团队提出了“具身自动标注”Embodied Autolabelling这一概念,也就是从原始数据当中自动识别任务的起止、操作对象、接触情况、状态变化以及最终结果,并进一步完成时间对齐、事件分割以及状态估计。
研究团队还进一步指出,人类视频以及可穿戴数据不仅能够被用于任务学习,也有助于机器人对人的动作以及互动方式形成理解。
2.跨具身的任务保留重定向
跨具身的任务保留重定向,所关注的核心问题在于,如何把潜在的物理动作或人类演示转化为机器人能够执行的动作,同时保留其对于世界的预期作用效果。由于不同具身在运动学、动力学、传感器以及接触面等方面存在很大差异,因此其中所需要保留的,应当是与任务相关的物理变化,诸如物体位移、姿态变化、接触状态以及插入过程中的对齐关系。
3.物理扎根的世界模型
物理扎根的世界模型被用于预测动作所带来的物理后果,例如物体是否会发生滑落、接触是否会因此丢失,以及抽屉是否会出现卡住。这类模型所关注的,并不是视觉效果在表面上是否足够逼真,而是与任务相关的几何、接触、力、约束、材料属性以及任务进度,能否得到正确预测。研究团队也进一步强调,世界模型还需要具备可靠的不确定性估计能力。
4.自我改进的部署循环
机器人在执行动作之后,需要依据任务目标来判断结果是否有效,而这依赖于任务条件化的奖励扎根(Task-Conditioned Reward Grounding)。如此一来,部署轨迹便不再只是对成败的记录,而会进一步转化为监督信号,由此推动闭环迭代,并继续对失败来源进行定位。
图|下一代机器人:从物理经验迈向物理智能
未来方向
目前,当前各类物理经验所能够提供的都只是并不完整的监督:机器人数据缺少标签,视频缺乏动作信息,可穿戴数据并不绑定具体的机器人具身,而仿真则会受限于物理保真度。未来,需要构建物理数据引擎,把这些异构来源统一为同一底层物理结构的不同视图,并进一步将其转化为结构化标签。
研究团队也进一步指出,世界模型在表示方式的选择方面,至今仍未形成统一的方案。现有的像素表示、物体中心表示,以及点云、网格、神经场、Gaussian Splatting等三维表示,各自都存在一定局限,而在对接触、受力以及材料响应进行建模的能力方面,也仍然不够充分。未来,需要发展物理扎根的世界模型,并进一步提升其不确定性量化能力。
与此同时,当前跨具身重定向在实现路径以及验证方案方面,仍然缺乏足够清晰的框架。未来的研究重点,需要从对姿态的保留进一步转向对任务效果的保留,也就是不再把重点放在动作形式的复制之上,而是更加关注动作对于世界所产生的实际效果。
最后,研究团队还提到,部署过程中的失败往往仍然难以沉淀为具有针对性的改进信号。未来需要建立任务条件化的闭环机制,使系统能够区分进度、失败、恢复以及成功,并据此对相应组件进行更新,而不是笼统地重新训练。
本文来自微信公众号“学术头条”(ID:SciTouTiao),作者为夏千斯
来源:具身机器人研究全都错了?最新论文:不能只靠VLA和世界模型-36氪 | 36氪