出品:机器人技术笔记
现在我们想让机械臂自主把桌上的杯子夹起来。它看见了杯子,也规划了一条靠近路线,但夹爪一碰到杯子,杯子就被轻轻碰歪了,下一步到底该继续夹,还是先退回来重新调整,这种物理接触发生之后的规划问题往往很难决策。
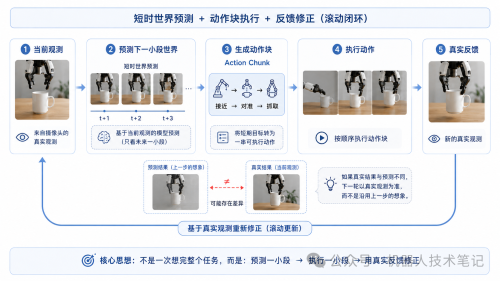
这些问题只看当前这一帧机器人相机获得的画面,很难回答。机器人需要在动作发生前,先对世界做一次短暂的预演:如果我这样动,下一刻会变成什么样。WAM 的核心就落在这里。
WAM,全称 World Action Model,可以翻译成世界动作模型。它要处理的核心,是让机器人把世界会怎么变和自己该怎么动放在同一条链路里学。用最简单的话说,VLA 更像是看见当前画面、听到任务指令,然后直接输出下一步动作;WAM 则会多想一步:它会结合刚才发生过什么,先预测下一刻世界可能怎么变,再生成能让世界朝这个方向变化的动作。
WAM 不一定是先生成一段完整高清视频,再把视频逐帧翻译成电机命令,真实控制里这样太慢,也太容易误差累积。更实际的方式是小段预测、小段执行、真实反馈、小段修正。很多机器人策略会用 action chunking,也就是一次不只输出一个瞬时动作,而是输出接下来一小段动作序列,让机械臂能连续、平滑地执行。
更进一步,这个 action chunk 还会和世界预测结合起来。模型先预测接下来一小段世界变化,再生成对应的一小段动作;机器人执行这段动作以后,相机会拿到新的真实观测。如果真实观测和原来的预测不一样,下一轮预测就要基于真实观测重新修正,而不是继续沿着旧想象往下跑。

动作和世界理解如何融合在一起?
WAM 大致有两类融合路线。一类是级联式:先预测未来状态,再从未来状态里解码动作。好处是结构清楚,中间结果比较容易检查;代价是前面想错了,后面很容易跟着错。
另一类是联合式:未来状态预测和动作生成在同一个框架里一起学。它想解决的问题很直接:世界预测和动作生成不能各干各的。一个模块在想象世界怎么变,另一个模块在生成动作,这两边需要互相看见,动作才更可能和预测后果对齐。
联合式里一个典型思路是 MoT,Mixture-of-Transformers。它可以理解成给不同模态各自留出专业通道:视频 token 走视频流的 transformer,动作 token 走动作流的 transformer。视频流更擅长处理高维视觉变化,动作流更贴近低维控制命令,两边再通过注意力 attention 机制交换信息。
这样做的好处,是不把视觉和动作强行塞进同一个空间。模型既保留了各自的处理方式,又能让动作生成看见世界预测的结果,让世界预测也知道机器人过去和接下来大概要怎么动。 MoT 就像是两个专业小组定期开会:一个负责想象世界,一个负责生成动作,中间通过共享信息把两件事对齐。
VLA 不够用了吗?
VLA 仍然很重要。它解决的是机器人能不能把视觉、语言和动作接起来。你说抓红色杯子,模型能找到红色杯子,理解抓取意图,并输出一段动作。对很多短时程、接触不复杂、容错比较大的任务,这条路线已经很有价值。
但要理解 VLA 的边界,先要抓住它的本质。
VLA 本质上是一种 mapping。
它学的是从观察和语言指令到动作的映射关系:画面里有什么,任务说了什么,历史上类似状态下人类或机器人示范过什么动作,于是模型输出下一段动作。这个 mapping 可以很强,可以覆盖很多物体、场景和语言表达,但它的基本形式仍然是从输入模式映射到动作模式。它可以通过历史帧、action chunking、扩散策略等方法变得更稳定,也可以把这个 mapping 做得很大、很泛化。
WAM 想补的是另一块:动作后果。
这个差别在静态语义任务里问题不大,到了长时程、强接触、高精度、可变形物体,问题就会冒出来。模型知道哪个是杯子,不代表它知道这个角度夹会不会滑。软物体、插孔、双臂协作这类任务也会遇到类似问题。这些失败点都发生在动作之后,也就是说,它们不只要求模型知道当前输入应该映射到什么动作,还要求模型提前判断这个动作会把世界推向哪里。
我的判断是,WAM 真正开始有价值的场景,是任务步骤长、接触多、物体会变形、失败后需要恢复,或者数据可以持续回收迭代。项目越接近真实物理交互,这种预测后果的能力就越值得认真评估。
现在看 WAM,先别急着下终局判断
WAM 这个方向很热,但我不太建议现在就把它看成一个已经定型的新范式。它还在起步阶段,很多方法其实是在 VLA、Diffusion Policy、视频生成模型和世界模型之间重新组合。比如 action chunking、视觉语言条件、闭环执行,这些思路很多都能在 VLA 或动作策略的发展里找到影子。
它真正新的地方,是把动作后果这件事摆到了更显眼的位置。机器人不能只把当前观察映射成动作,还要对动作之后的世界变化有一个可修正的预测。这个判断方向很重要,但具体怎么实现,还没有完全收敛。
原因也很简单,世界模型这个定义太大了。它可以是视频预测,可以是潜空间动态模型,可以接入 3D、触觉、力反馈和本体状态,也可以和 VLA 继续融合。只要一个模型在预测世界如何变化,并把这个预测接到动作生成里,它就有可能被放进 WAM 这条技术路线下。
所以 WAM 会发展成一个独立架构、一组训练目标,还是逐渐融进下一代 VLA 里,我们都还需要持续观察。具身智能领域现在新颖的概念层出不穷,我们需要的不是盲目追求热点,而是站在更长的时间周期上判断哪些工作能真正推动行业发展。