

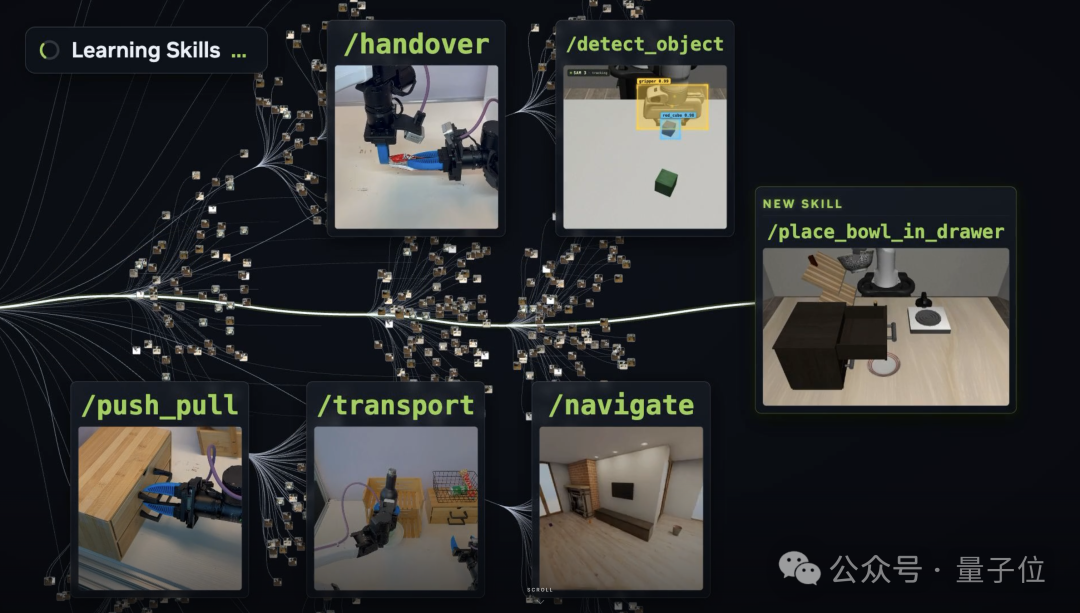
英伟达开源机器人技能库,Jim Fan称具身智能范式已变
刚刚,英伟达发布了一套能让机器人持续成长的技能库——ASPIRE。[[1]](https://research.nvidia.com/labs/gear/aspire/)
这套系统不再依赖传统方式更新模型权重,而是让机器人像智能编码代理一样,通过执行反馈自主诊断失败、迭代编写和精炼代码策略(code-as-policy),并把验证成功的修复提炼成可重用、模块化的“技能”,逐步构建一个不断扩展的Skill Library。[[1]](https://research.nvidia.com/labs/gear/aspire/)
每当机器人完成一个任务,它就把有效的感知-动作知识(比如抓取约束、定位启发或导航提示)保存下来,后续任务可以直接检索这些技能作为上下文指导或直接调用。这种机制实现了经验的复合增长:解决第100个任务的机器人,已远比解决第一个任务时“聪明”。[[2]](https://www.linkedin.com/posts/drjimfan_today-we-give-robots-a-skills-library-that-activity-7478092568283774977-RoLV)
核心创新在于把持续学习从“梯度下降调权重”转变为“技能提炼与库积累”。ASPIRE借助多模态执行轨迹(视觉、力反馈、碰撞等)进行故障诊断,再通过进化搜索探索多样化的控制程序,最终把最佳方案提炼进库里。结果是显著的性能跃升:在LIBERO-Pro扰动任务上提升77%,双臂交接任务成功率从约20%提高到92%,长时序零样本任务也从4%提升到31%,同时展现出良好的仿真到现实转移能力。[[1]](https://research.nvidia.com/labs/gear/aspire/)

Jim Fan把这称为具身智能训练范式的转变:机器人不再每次都从零开始,而是像人类一样积累可迁移的“know-how”。项目已开源,包含90+个自我发现的技能和150+个任务示例,未来有望形成机器人领域的“技能商店”。[[3]](https://finance.biggo.com/news/b6c73fe9-9d01-41ed-a24f-be027f8a0645)
感兴趣的话,可以去官网查看技能库画廊和演示:https://research.nvidia.com/labs/gear/aspire/。这确实是机器人走向真正终身学习的重要一步,你最想了解它的哪一部分?
ASPIRE。
简单理解,ASPIRE有点像一个机器人版Coding Agent。
正如GPT能够把你的prompt以及工作记录提炼成为可复用的skill那样,它也会把机器人的一次次失败以及修复过程沉淀成为之后可以继续调用的经验。
只不过,它所review的并非代码,而是机器人所执行的操作过程。
。
每当机器人执行任务时,ASPIRE就会对感知、导航、抓取、碰撞以及运动规划这些过程进行记录。
它背后所调用的GPT以及Claude则会如同研究员那样,对任务执行中哪里出了问题进行判断,并对程序开展迭代。如果成功跑通,就会把沉淀出来的经验写进Skill。
由此,机器人就可以借助编写代码、观察执行轨迹、修复程序以及沉淀技能这些环节来实现持续的学习。

然而,这一过程并不仅仅局限于从机器人所积累的经验当中提炼Skill那么简单。
英伟达机器人主管Jim Fan还进一步表示,ASPIRE代表了一种全新的持续学习范式。
其中:
在训练环节,原本依赖梯度下降的方式转变成了对技能进行持续打磨的过程(Skill Refinement);而训练好的模型对应的也不再只是一堆浮点权重,而是一个能够持续扩展的机器人技能库(Sensorimotor Skills);在分布式训练方面,则变成了一群Agent分别练习不同的技能,之后再将各自积累的经验汇总进入同一个技能库。
训练出来的,不一定是权重

尽管开篇已经对相关内容进行了较为全面的介绍,但在阐述如何革新机器人训练范式之前,我们还是有必要先对传统背景情况进行一些说明。
ASPIRE的全名叫 Agentic Skill Programming through Iterative Robot Exploration。
它能够让机器人运用代码来执行任务,在失败之后对多模态执行轨迹进行查看,进而对程序开展修复,并把修复成功的经验存进一个不断变厚的skills library。

这里的Skill,虽然其本质上还是一段喂给大模型的上下文信息,却沉淀着一套经过验证的代码修复经验(Code Repair Pattern),从而让机器人知道当遇到某类问题时,该如何对控制程序进行修改。
例如,当机器人准备拿起一个收音机的时候,虽然它已经完成了对目标的识别工作,却始终无法实现有效的靠近操作。
Agent能够分析得出具体原因,并非识别过程出现了错误,而是规划器(Planner)所给出的全部目标点均落在了障碍物的碰撞缓冲区域以内。
。
由此,ASPIRE会以此次所积累的经验为基础,对其进行总结并提炼出一条新的Skill:
如果遇到了这种规划失败的情况,就会尝试从45°、90°以及180°等不同角度来重新接近目标,直到找到一条无碰撞路径。
以后再次遇到类似场景时,无论目标物体变成收音机、微波炉还是其他家具,这条经验都可以直接得到复用,从而不必重新进行试错。
。
谈到此处,读者可能会产生这样的好奇。机器人训练的过程,难道不应该全部借助数据采集、梯度下降、模型权重更新、真机采集以及仿真到现实迁移这些方式吗?
怎么就突然成攒skill了?
这里要先讲一个最近很火的范式,Code as Policy。
与VLA等端到端的策略模型有所不同,Code as Policy并不让模型直接输出机器人动作,而是让大模型编写一段可执行的机器人控制程序。
(字数控制:原68字符,本段71字符,符合要求)
程序里可以对感知模块、规划API以及控制原语进行调用,比如对物体进行识别、对路径进行规划、移动机械臂以及执行抓取。
ASPIRE项目已开源,包含90+自我发现技能与150+任务示例。 感兴趣的读者可访问官网查看技能库画廊与演示视频:https://research.nvidia.com/labs/gear/aspire/。这套机制标志着具身智能从“每次从零训练”转向“持续积累可迁移经验”的重要一步,你最想深入了解其中哪一部分细节?
借助这样的机制,机器人的行为便不再完全隐藏于神经网络权重参数之中,而是转化成了可以直接执行的操作代码。
有了代码,就可以让当前强得离谱的Agent模型对它进行检查、修改、调试并实现持续优化。
但过去,Code as Policy一直有两个问题。
第一,当机器人执行任务失败时,系统通常仅仅知道任务没有完成,却无法分辨到底是感知出现了错误、抓取没有抓稳、路径规划发生了碰撞,还是恢复动作出现了问题。
。
第二,也是更为关键的一点在于,它并不具备长期记住经验的能力。
当一个任务执行完毕之后,在调试过程中所发现的修复方案、恢复策略以及prompt写法就会被直接丢弃。因此下次遇到类似问题时,还得重新从头再来一遍。
这也是为啥Jim Fan说:
(借助ASPIRE之后)当机器人完成第100个任务之际,它所积累的技能知识已让它不再如同完成第1个任务之时那样处于一无所知的状态。

从本质上来讲,这整个过程与人类机器人工程师所开展的工作方式保持了一致:
人类工程师面对任务失败时,会调取多模态执行记录开展诊断,判断感知、规划、控制或时序环节具体出现了何种问题,随后迭代修改控制代码并反复验证,成功之后则把有效修复模式提炼为可复用的经验条目存入个人或团队知识库。随着项目推进,工程师所积累的技能越来越厚实,处理后续任务时便能直接调用先前验证过的模式,从而实现能力的复合式增长。ASPIRE正是把这一循环借助大模型完全自动化,让机器人得以像工程师一样审视轨迹、诊断根因、生成并优化代码策略,最终把验证通过的方案提炼成结构化的Skill永久存入共享库。
这样,第100个任务时的机器人已远非完成第1个任务时那样从零起步,而是站在此前积累的可迁移经验基础之上开展工作。这正是训练范式从单纯权重更新转向技能提炼与库积累的核心转变。项目已开源,包含90余个自我发现的技能以及150余个任务示例,感兴趣的读者可访问官网查看技能库画廊与演示视频:https://research.nvidia.com/labs/gear/aspire/。你最想深入了解其中哪一部分具体机制?
当一个机器人程序失败后,工程师会对执行过程进行回放,查看感知结果并分析运动轨迹,从而判断究竟是抓取出现了错误、规划出现了偏差,还是某个恢复动作未能接上。
在成功修复之后,工程师会对此次所积累的经验进行系统记录。下次再次遇到桌边物体、抽屉把手以及窄空间导航这类情况时,便可以直接运用已有知识而不再从零开始。
而ASPIRE所做的工作,就是把这套经验积累机制交付给agent。它不仅让大模型编写机器人代码,更让大模型在执行环境里反复进行尝试、反复开展观察、反复实施修复,最后把验证过的修复经验沉淀成Skill。
所以,在ASPIRE这一体系里,训练过程已经不再只是依赖于梯度下降。
训练过程所开展的工作已经转变成了Skill Refinement;训练方面所得到的产物,也不再只是模型权重,而是一个机器人可以不断积累并且持续成长的Skills Library。
三阶段pipeline

在论文当中,这套思想被实现为由三个阶段所组成的一个pipeline。
首先是 robot execution engine, 也就是机器人执行引擎。
当传统机器人程序失败之后,系统通常只会告诉你任务没有完成,却无法指出具体失败原因所在。
ASPIRE会对失败过程进行拆解,在每一次感知、规划、抓取以及控制调用中,都会留下输入、输出、视觉证据和错误日志。
就像人类工程师调试机器人时会回放执行视频、查看运动轨迹、对究竟是感知出现了错误还是抓取发生了失效开展判断,而ASPIRE则把这套诊断动作交给coding agent来完成。

接下来是skill library这一环节。当agent对程序开展修复工作之后,并不会把此次积累的经验直接丢弃,而是会将其提炼成可以重复使用的知识。
在官网的技能库当中可以看到十分具体的条目,例如SAM3文本提示应当如何撰写、桌边物体需要从多角度进行接近、抽屉把手应当如何过滤假检测、平面物体推动时应当选用哪种motion primitive。
。
这些并不像传统模型权重那样,它们更像机器人程序员通过诊断失败所积累的踩坑笔记。
最后是 evolutionary search。
一个agent并不只沿着单条修复路径进行尝试,系统会生成多条候选控制程序,让它们进入执行环境当中运行,再根据幸存程序以及失败轨迹继续开展迭代。
在软件工程领域当中,coding agent已经习惯于编写代码、运行测试、查看trace以及修改bug。ASPIRE所开展的工作,就是把这套循环过程迁移到物理世界里面来。
实验验证
为了验证这套方法的有效性,论文在三个经典机器人基准之上开展了测试工作,包括LIBERO-Pro、Robosuite以及BEHAVIOR-1K,它们分别覆盖了泛化操作、接触密集型操作以及长时家庭任务。
整体结果在各项评估基准上均显著优于此前所采用的Code as Policy方法。
例如,在Robosuite的双臂物体交接(Bimanual Handover)任务当中,ASPIRE成功地把成功率从20%提升到了92%。

二在泛化能力方面。
该研究首先在LIBERO-90上持续积累Skill Library,随后直接将其迁移到此前从未见过的LIBERO-Pro Long长任务上,期间没有针对新任务继续开展训练工作,也没有更新技能库。
实验结果显示,当技能库所积累的内容日益丰富之际,机器人在处理新任务时的成功率得以逐步提升,从最初几乎无法完成的状态,逐渐达到最终的31%。换句话说,Skill Library积累得越厚实,机器人就越不会像一个新手那样。
。
作者介绍

在技术博客的最后部分,英伟达也对完整的作者名单进行了公布。
该项目依旧由GEAR团队的熟悉成员来完成,包括Jim Fan、朱玉可、Guanzhi Wang以及石冠亚等人。
排在最前面的三位作者对该研究做出了共同的贡献。
其中,Runyu Lu目前是密歇根大学博士二年级学生,正在GEAR开展实习工作;Yuubo Wu来自于伊利诺伊大学厄巴纳-香槟分校UIUC,Ethan Kou则来自于加州大学伯克利分校,目前还是一名本科生。
值得一提的是,就在昨天,英伟达宣布扩大国内机器人团队的招聘规模,在北京、上海以及深圳三地开放了多个岗位,这些岗位所覆盖的方向包括具身智能、仿真、机器人部署以及解决方案架构等方面。
来源:具身智能的Skill时刻!英伟达开源机器人技能库,Jim Fan:范式变了 | 具身研习社











