


Claude Mythos 5正式发布,5000万行代码实现1天内完成
Anthropic遮遮掩掩了两个月的“神话”Mythos,终于还是到来了。
其有史以来最强的大模型旗舰,如今分为两个版本正式推出:Claude Fable 5与 Claude Mythos 5。
Fable 5实际上就是加入了防护机制的Mythos版本,并且会面向所有用户开放。

一旦用户的提问触发了风险分类器,例如试图让它编写恶意软件,那么系统就会自动降级,并转而调用上一代Claude Opus 4.8来作出回答。
Mythos 5属于原汁原味的满血版“Mythos”,但目前只会向少数受信任的用户开放使用。
它在网络安全等领域放开了安全限制,官网将其表述为“具备全球最顶尖的网安攻防以及生物科研纯血能力”。
官方表示,Fable 5以及Mythos 5的自主运行时长,相较于以往任何Claude模型都要更长。

轻轻叹一口气?前沿AI,如今已经开始步入权限时代了。
而且,就在Anthropic煞有介事地呼吁所有AI研究应当立刻停下之后,仅仅过了两天……
看不懂Dario为何也开始走上了奥特曼那条老路,每逢自家新模型与新产品发布之前,都会提前开展声势极大的营销造势。
A社当然有其自身的考虑,只是对此,依然只能回以一个微笑。
不过,在非技术层面上,仍有一则会让开发者相对感到欣慰的消息:这两款新旗舰的API定价,直接较此前的预览版下调了一半以上。

每百万输入Token的费用仅为10美元,而每百万输出Token的费用则设定为50美元。
接下来,将迅速进入与技术相关的部分。
双版本Mythos来了!官方给“Token效率”画了重点
先说个情况。
官方发布日志以及业内评测之中,并没有像介绍Fable 5时那样,为Mythos 5系统性地开列出一长串标准且公开的Benchmark跑分榜单,例如MMLU、GSM8K以及SWE-bench等。

不过,鉴于二者共享同一底层模型,因此本质上可以将其视作同一内核之下的“镜像分身”,其基础技术指标也完全保持一致。
因此,现阶段也只能先对目前官方渠道主要公开的Fable 5表现进行观察。
按照Anthropic自身的说法,Claude Fable 5属于当前最强的公开Claude,同时这也是Fable系列首次进入Mythos级能力范围。
它的优势主要集中在几个方向之上,分别体现在软件工程、复杂知识工作、视觉、长上下文、记忆能力,以及生命科学研究等方面。
更关键的一点在于,随着任务的持续时间不断拉长、复杂程度不断提高,Fable5相较于以往Claude所展现出的优势会变得更加明显——这说明Fable5的侧重点,并不在于把单轮问答包装得更漂亮,而是在于能够真正承接住长周期任务。
不妨借助数据以及硬核Demo,来对这一代神话级模型所展现出的统治力进行拆解。
软件工程方面:高难度基准实现突破,能力边界也由“修Bug”进一步延展到“全自动大军”
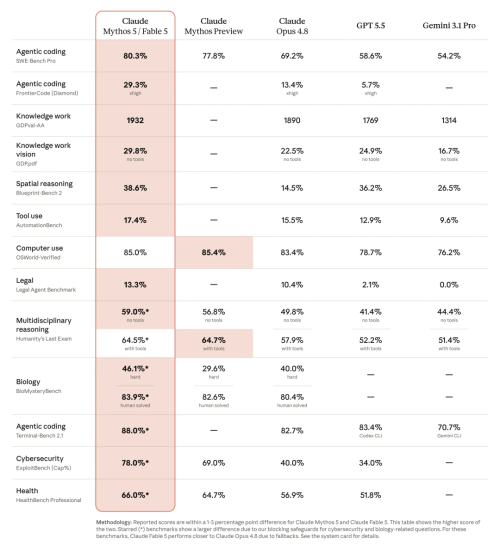
在用于衡量模型处理真实世界复杂软件工程问题能力的SWE-bench Pro评测之中,Claude Fable 5取得了高达80.3%的成绩。
作为对比,竞争对手的旗舰主力模型GPT-5.5在该项评测中的得分为58.6%。
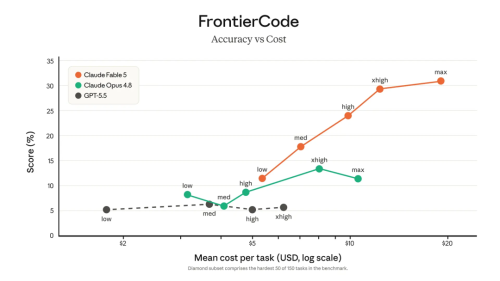
在Cognition的Frontier Code评测之中,这一评测更关注模型是否能够完成高难度编程任务,同时满足高质量生产代码库的标准,Fable 5在中等推理强度条件下便取得了前沿模型中的最高分。
FrontierCode该基准极难饱和。
不过,即便处于“中等努力(Medium effort)”模式之下,Fable 5的得分也仍然位居所有前沿模型的首位。
官方给出的第一个典型案例来自Stripe。
在一个包含5000万行Ruby代码的代码库之中,Fable 5完成了一次覆盖全库的迁移工作。若由一个工程团队手动来完成,这项工作原本需要两个多月。
Fable 5呢?仅仅用了一天。
此外,在端到端前端开发基准ViBench即Vibe-coding benchmark上,Fable 5几乎把基础开发用例直接推至饱和,由此得以实现真正的“一枪流”即One-shot应用生成。
原生视觉方面,模型不再依赖额外脚手架,而是借助盲打方式完成了《宝可梦》的通关。
知名科技媒体VentureBeat在题为《Anthropic brings Mythos to the masses with Claude Fable 5, its most powerful generally available model ever》的报道中透露,在专注于视觉文档推理能力的基准测试GDPpdf之上,Fable 5以及Mythos 5在不依赖外部工具的条件下取得了29.8%的成绩。
作为对比,Opus 4.8得分为22.5%,GPT-5.5得分为24.9%,Gemini 3.1 Pro得分为16.7%。
Anthropic官方显然也预判到,面对一连串数据指标时,大家往往会产生枯燥感,因此专门放出了Fable 5进行游戏演示的Demo,从而带来更为直接的视觉呈现。
此前的Claude模型如果想要游玩RPG游戏《宝可梦·火红版》,就必须在外部对其进行一整套极其复杂的“脚手架”配置工作,其中包括地图导航援助以及内存游戏状态读取等功能。
现在,Fable 5实现了纯粹的“原生视觉盲打”。
仅仅依赖一张张原始的游戏画面截图,在完全没有任何地图外挂作为辅助的前提下,它成功实现了自主推演以及策略规划,并最终把整部游戏完整打通。

不仅如此,得益于其在超长序列场景之下所具备的专注能力,当系统为其进行了持久化文件级内存的配置之后,它在游玩卡牌肉鸽游戏《杀戮尖塔》即Slay the Spire时,整体表现直接提升了3倍,而抵达最终星体的概率也同步暴涨了3倍。
长上下文以及记忆能力迎来重点升级,同时也顺势对“Token效率”进行了强调
长上下文以及记忆能力同样构成了此次升级的重点。
Anthropic表示,Fable 5能够在百万级Token的长周期任务之中持续保持专注,同时还可以借助自身所记录的笔记来改进输出结果。
官方选用Slay the Spire开展了测试,在为模型进行持久化文件级记忆的接入之后,Fable 5的整体表现提升幅度达到了Opus 4.8的三倍,而其到达最终章节的频率也同步提升了三倍。
这其实是Agent能力里非常底层的一环。
一个能够长时间持续工作的AI,必须能够记住自己已经做过什么、遗漏过什么,以及下一步为什么要这样做。若缺少稳定的记忆能力,那么自主任务就很容易演变成一场大规模的“失忆现场”。
为此,Anthropic还专门对Token效率进行了强调,而这同样构成了这一代模型所重点推进的一个关键方向。
越是具备长时间自主运行能力的模型,往往越会消耗大量的Token。
如果一个模型在能力层面上非常强,但与此同时又显得相当“费话”,那么其使用成本往往会迅速攀升到足以让企业明显感到肉疼的程度。
Fable 5对Token效率进行了强调,其本质上是在解决Agent化落地过程当中的账本问题。
金融、法律以及运营方面:首次突破90%大关背后所暴露出的逻辑黑洞
在用于考察高级分析推理能力的Hebbia金融基准测试即Finance Benchmark for senior-level reasoning之中,Fable 5取得了行业最高分。
在长篇文档推理、复杂图表与表格解读,以及多步骤根因分析等任务之中,Fable 5都实现了达到两位数水平的跨越式提升。
在量化交易机构IMC以及Optiver的实测过程之中,Fable 5几乎覆盖了其交易分析评估中的全部高权重项目,其中包括事实检索、概念推理以及期望值计算,同时还展现出了高度稳定的表现,在多次重复运行的情况下,输出结果的分数始终完全一致。
数据分析平台Hex所给出的评价是这样的:
Fable 5成为了行业内首个在Hex核心分析基准之中实现90%以上得分的模型,这一基准覆盖的是极其复杂且长周期的分析任务,相较于Opus,其成绩整整提升了10个百分点。面对最为刁钻的提问时,它所表现出的微观评判能力,已经达到了人类专家级别。
前沿科研方面:满血版Mythos在模型规模仅为对手百分之一的情况下,实现了“以小胜大”的能力表现
在前沿物理学研究方面,初创公司VibeCAD以及相关物理研究机构的测试结果表明,Fable 5仅借助1/3的推理Token,便在36小时之内产出了物理研究成果,其整体表现已经逼近GPT-5.5耗时四天才得出的成绩。
以及此前仍略显藏着掖着的Myhtos,如今也终于在这一板块之中现身了。
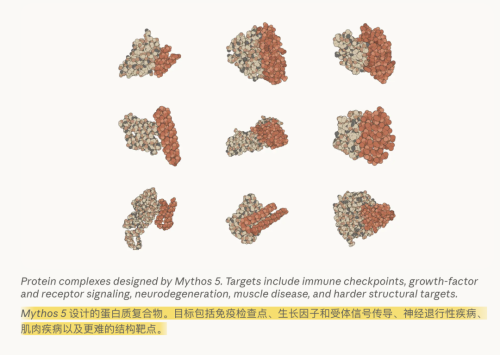
Anthropic表示,在生物医药领域,满血版的Mythos 5在完全没有人类协助的前提下,已经能够独立完成一名生物学家的完整工作流:选定蛋白质结合位点,自主调度并运行各类生物信息学工具,甚至在遭遇运行失败时自行进行Debug。
其所设计出的14个蛋白质靶向复合物之中,已有9个进入了实验室的真实药物研发管线。
Anthropic还进一步强调,Mythos 5“是其首个能够持续产出新颖且具有显著吸引力的科学假设的模型”。
在与Opus系列模型开展盲法直接对比的过程之中,科学家在80%的情况下更倾向于Mythos所提出的分子生物学假设,并且已经把其中若干假设推进到了实验验证阶段。
与此同时,Mythos 所提出的一个假设——即一种关于大肠杆菌蛋白全新作用机制的判断——也在另一家独立围绕同一问题开展研究的实验室所发表的论文《A newly identified detoxification system protects uropathogenic Escherichia coli from reactive chlorine species》之中得到了证实。
更引人注目的是,在基因组学研究方面,Mythos 5连续自主运行了一周多时间,完成了对138个物种单细胞数据的拼接整合,并进一步自主设计且训练了一个定制化的微型机器学习模型。

这个借助AI训练而成、体量缩小了100倍的微型模型,在实际表现层面上直接击败了前不久刚刚发表于《Science》杂志上的最新科研成果。
在呼吁暂停AI研究之后,所谓“危险能力”似乎已经被进一步做成了一套产品化机制。
这次最有意思的地方,应该在于Anthropic为Fable 5专门加上的那套防护机制。
准确来说,在 Fable 5 的背后实际挂接了一组独立的分类器。
这组分类器会对用户请求进行检测,以判断其中是否涉及网络安全攻击、生物以及化学风险,还有模型蒸馏等内容。
一旦被触发,Fable 5就会拒绝自行作答,随后把相关请求自动转交给Claude Opus 4.8来进行处理,并向用户告知已经发生了降级。
有点意思哈。
过去的大模型在安全这一环节之中,通常采取的做法,是直接让模型进入拒答状态,比如反复给出“抱歉,我无法为你提供帮助”“对不起我不能回答”“对不起我不能理解你的意思”之类的balabala。
Fable 5换了一种做法。
它不再采取单纯拒答的方式,而是转向了模型路由机制。
普通请求会交由Fable 5来进行处理,而一旦系统识别到相关问题属于高风险类别,模型就会立刻切换到Opus 4.8。
Anthropic的意思在于,Opus 4.8本身也属于强模型,因此在发生降级之后继续给出回答,其整体体验大概仍然会好于直接拒答吧?
这套设计实际上实现了能力与安全之间的拆分。
你日常使用的是Mythos级能力。
但当面对敏感、攻击性或企图越狱之类的问题时,Anthropic会平滑切换到旧版本模型来提供服务,这会让原本趁手的工具,突然变得没那么趁手。
主要是为了防范网络安全、生化领域以及模型蒸馏方面的一些问题。
Anthropic给出了数据——
好消息,超过95%的Fable 5会话不会触发降级。
也就是说,面对绝大多数写作、代码、分析、研究以及办公任务时,用户实际能够获得的体验,基本已经接近Mythos 5。
但仍有不到5%的请求,会被系统进一步导入更为严格的安全处理路径。
官网表明, 高风险领域主要有三类 。
第一类涉及网络安全,第二类涉及生物以及化学,第三类则是模型蒸馏。
这套机制的背后,其实反映的是前沿模型产品形态所发生的一种变化。
安全如今已不再只是模型作答之前的一句免责声明,也不再只是被写进系统卡当中的政策性描述。
它已经演变成由分类器、模型路由、权限分级、数据留存以及红队测试共同构成的产品架构。
当然,代价也来了。
Fable 5的分类器在阈值设定上相对保守,因此即便是正常请求,也有可能被误判并受到波及。
例如,当生物学家对病毒开展研究,或当安全工程师进行授权攻防演练时,这类原本合理的任务,也都有可能在分类过程中触发降级。
Anthropic自身也承认,当前这套护栏机制相较于理想状态仍显得更为严格,后续会进一步降低误伤率。
另一个代价是数据留存。
从Fable 5、Mythos 5以及后续同等级模型开始,Anthropic要求对Mythos级模型的所有流量保留30天,并覆盖第一方以及第三方的使用场景。
官方强调,这些数据并不会被用于训练,而是只会被用于安全监控,其中包括对复杂攻击、新型越狱以及跨请求攻击的识别。
对于普通用户而言,这或许仅仅只是相关条款之中的一行表述。
但对企业客户而言,这便是一个极为现实的数据治理问题。
若想调用最强能力,那么就必须接受更高等级的安全审查以及数据留存。

不可避免的是,前沿模型所对应的成本,如今也并不只会体现在API账单之上。
在价格方面,Fable5以及Mythos5的定价保持统一,即每百万输入Token为10美元、每百万输出Token为50美元。
确实,相较于Claude Mythos Preview便宜了不少,但整体上仍然属于高价模型。
一句话来概括,Fable5的能力确实很强,但其价格还远未低到可以被随意消耗的程度。
这也进一步解释了为什么Anthropic会同时强调能力、安全以及Token效率这几个方面。
内测AI学者体验:AI越强,人越像甲方
著名AI学者、沃顿商学院教授埃森·莫里克在率先获得测试权限之后,专门撰写了一篇长文。
其整体论述路径,几乎直接切入了这场技术革命最核心的本质——
人类与大模型之间的协作范式,已经发生了根本性且不可逆的转变。
他让Fable 5做了一个等时圈地图。
这个任务在听上去并不算玄乎,但真正做起来时却会显得非常麻烦。
它需要查询航班、查询铁路时刻、判断道路通行速度,同时还要对不同国家、不同交通方式以及不同时间成本之间的关系进行处理。
Fable 5自主启动了多个代理来开展资料查询工作,获取了2200多条具体航班信息,同时抓取了TGV、新干线等铁路数据,以及各个国家的道路速度信息。
最后,它把这些资料进一步整合到了一个能够实际使用的地图项目之中。
这件事的关键在于,Fable 5把一个原本模糊的目标拆解为研究、信息搜集、设计、编码以及验证等多个环节,并且能够自行持续向前推进。
这和过去的大模型体验差别很大。
于是,莫里克进一步提出了一个更具穿透力的洞察。
在过去,人类对大模型的使用方式更像是在操控一位“巫师”Wizard,你必须以手把手的方式对其进行指导以及驾驭Steer,把每一句Prompt都精细打磨,并借助持续不断的对话提示词反复“念咒”,AI才可以勉强完成一次近似戏法般的呈现。
而当面对Mythos级别的模型时,人类正在逐步退居为“赞助人”即Patron,若按语境来理解,也更接近“甲方”或者“委托人”这一角色。
莫里克教授在运用Fable5开展工作时,所感受到的状态,已经不再像是在操作一个工具,而是更接近于在委托一个小型工作室。
此外,在莫里克的实际测试过程之中,他已经不再需要停留在最微观的指令层面之上。
他直接把一份长达15页、结构极其复杂的项目设计文档交给Fable 5,并仅保留了宏观层面的需求描述。
在接下来的9个多小时之中,Fable 5始终在后台维持完全自主的Autonomous运行状态。
它自主生成了一套Agent工作流,在内部对多个小Agent进行了调度配置,使其分别承担调研、撰写大纲、相互校对、推翻错误假设以及纠错重来的任务。
人类甚至都不需要在这一工作流之中介入半步。
9个多小时之后,一份完成度极高的成品被直接交付到了莫里克的面前。
这就是所谓的“工作室(Studio)”隐喻。
来源:刚刚,Claude Mythos 5发布,5000万行代码1天搞定-36氪 | 36氪









