出品:机器人产业应用
前言
机器人到底是真会干活,还是只会做几个“熟练动作”?
过去几年,具身智能很火。各种机器人模型、VLA模型、模仿学习方法不断出现,演示视频里,机器人可以根据语言指令抓杯子、拿苹果、放进盒子,看起来已经很接近“通用机器人”。
但如果把镜头从演示视频拉回真实世界,会发现一个很现实的问题:很多机器人模型擅长的任务,其实集中在少数高频动作上,比如“抓起来”“拿住”“放下”“移动到某个位置”。这些动作当然重要,但真实生活远不止这些。
人类做事充满细节。比如,把球打进桌面球门,不是慢慢推过去;用印章盖章,不只是拿起印章,还要拔盖、按压、停留、再插回;关抽屉时,有时一只手要固定后方,另一只手才好推进去;穿山楂串时,要考虑竹签是否弯曲、果子是否滑动。这些动作看起来不宏大,却非常考验机器人对接触、顺序、力度、空间关系和物体特性的理解。
GM-100,全称The Great March 100: 100 Detail-Oriented Tasks for Evaluating Embodied AI Agents(用于评估具身智能的 100 项细节导向型任务),正是围绕这个问题提出的真实机器人评测基准,于2026 年初 由上海交通大学联合 SII(交大内部研究团队)、RHOS.ai(交大李永露副教授领导的研究实验室)、蚂蚁灵波、蚂蚁集团 共同发布。
简单来说,GM-100 是一套100 个精细化、长尾化的具身 AI 评测任务,专为全面、公正评估机器人智能体的真实世界交互能力而设计,能有效区分当前 VLA 模型的性能差异。它不是单纯多收集一些数据,也不是再做一个漂亮榜单,而是试图回答一个更基础的问题:我们到底该用什么样的任务,去判断一个具身智能模型是不是真的更强?

01
GM-100解决的不是“数据不够”,而是“考题太偏”
今天机器人学习领域并不缺数据。Open X-Embodiment、Agibot、RoboCOIN、DROID、RH20T 等数据集都在推动机器人训练数据规模增长。
问题在于,数据量变大,并不等于任务设计更合理。GM-100论文中特别强调,很多已有任务在语义去重和动作分类后,会明显集中在“pick and hold”等常见行为上,复杂任务和长尾行为覆盖不足。
这就像考试。如果一张试卷里大部分题目都在考加减法,那么学生的分数很高,并不能证明他会解决复杂应用题。放到机器人上也是一样。如果评测任务主要是抓取、放置、移动,那么模型在榜单上表现不错,并不意味着它真的具备复杂操作能力。
GM-100的核心价值,就在于它把评测重点从“模型有多大、数据有多少”,拉回到“任务是不是足够真实、足够细、足够能拉开差距”。它关注的是机器人在真实物理世界中经常遇到、但传统评测中容易被忽略的细节动作。比如动态接触、双臂协同、物体排序、柔顺操作、工具使用、动作节奏控制等。
| 表1:GM-100核心信息速览
论文和官网显示,GM-100在两类真实机器人平台上采集数据,其中Cobot Magic覆盖100个任务,Xtrainer当前版本覆盖前10个任务;每个任务通常包含100条训练轨迹和30条测试轨迹,用于保证不同模型在相近测试分布下比较。
02
GM-100到底考什么?考的是“细节动作能力”
GM-100最有意思的地方,是它并没有只选择那些看起来“有用”的家务任务,而是刻意减少人类主观偏见。
论文中提到,任务设计不以现实任务的实用性为唯一标准,而是基于物理常识和底层操作可执行性,也就是所谓 how-level affordance。简单说,就是先问:这个动作在物理上是否合理?机器人是否能通过当前硬件执行?这个任务是否能考察一种明确的操作能力?
官网展示的前几个任务已经很能说明问题:击球入门、切割物体、盖章、折纸盒、关闭桌面抽屉、穿山楂串、清理垃圾、转移试管、打开台灯、按大小排序方块等。
这些任务并不都是传统意义上的“大任务”,但每一个都在考机器人某种底层能力。比如“击球入门”考的是瞬时接触和动作节奏,机器人不能只是把球慢慢推过去;“切割物体”考工具使用和接触力控制;“盖章”考多阶段顺序动作;“关闭抽屉”考双臂配合,一只手稳定物体,另一只手推进;“穿山楂串”考精细对准、柔顺控制和防止竹签弯曲;“试管转移”考易碎物体操作;“方块大小排序”则考视觉判断、排序逻辑和稳定摆放。
| 表2:部分GM-100任务与对应能力
从普通读者角度看,GM-100其实在告诉我们:机器人真正难的不是“听懂一句话”,而是把一句话拆成一连串物理动作,并且每一步都不能太粗糙。人类做这些事情时几乎不用思考,但机器人要同时处理视觉、语言、动作、接触、力度、顺序和失败恢复,这才是真实世界的难点。
03
GM-100怎么生成任务?
GM-100的任务不是研究者随便列出来的。它采用了一条比较系统的任务构建流程。
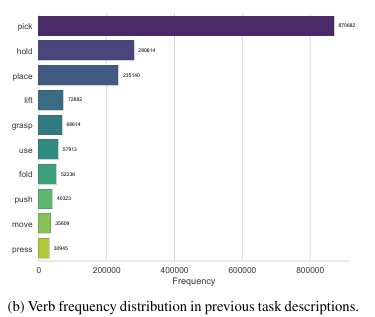
第一步,是收集并分析已有机器人数据集和评测任务,对任务进行去重和语义分类,找出现有任务中哪些动作过度集中,哪些动作长期缺失。论文中的词云和动词频率分析显示,过去任务描述中确实存在明显的高频动作偏置。
第二步,是引入人–物交互研究中的知识。GM-100借鉴了HAKE、PaStaNet、OCL等工作中的人–物交互原语和物体可供性。这里的“可供性”可以理解为一个物体天然支持哪些动作:刀可以切,抽屉可以拉开和关闭,印章可以按压,试管可以拿取但需要轻柔,球可以击打或滚动。通过这种方式,任务不再只是“桌面上有什么就做什么”,而是围绕“人类如何和物体发生交互”来展开。
第三步,是利用Qwen3大模型生成候选任务。论文描述中,Qwen3会在统一prompt下对动作原语进行语义消歧,枚举与动作相关的物体,再合成具体任务描述。随后,大模型会对任务的机器人可执行性进行初筛,最后由五位人类专家进行筛选。
第四步,是把任务变成真实可执行的评测项。研究团队不仅给出任务名称,还会设计交互细节、选择合适物体、建立完成标准,并录制人类完成任务的模板视频。官网也提供任务展示、训练/测试数据入口、物体购买链接和交互式榜单。
这套流程的意义在于,它把机器人评测从“经验驱动”推进到“结构化设计”。以前很多评测像是研究团队自己出题,题目之间缺乏统一标准;GM-100则试图建立一套可持续扩展的方法,让未来GM-X系列可以不断增加任务,而不是停留在一次性数据集。
04
真实任务不该只有“成败二分”
传统机器人评测最常见的指标是Success Rate,也就是成功率。任务完成了就是1,失败了就是0。这很直观,但对于复杂任务来说不够细。
比如机器人执行“盖章”任务,它成功拿起印章、拔掉盖子,也完成了按压,但最后没有把盖子插回去。按照传统成功率,它可能仍然是失败。但从能力分析角度看,它并不是完全不会做,而是卡在最后一步。再比如“关闭抽屉”,机器人可能已经抓住抽屉并推动了一段距离,只是没有完全闭合,这和一开始就没有找到抽屉显然不是同一种失败。
因此,GM-100提出或采用了Partial Success Rate,也就是部分成功率。PSR衡量的是一个复杂任务中,子任务或子目标完成了多少。论文明确指出,对于包含多个步骤或目标的复杂任务,仅靠SR难以充分反映模型表现,因此多数GM-100任务会定义多个子任务和子目标,用PSR进行更细粒度评估。
这对行业非常重要。因为机器人模型的进步往往不是突然从0到100,而是先学会识别物体,再学会接近,再学会接触,再学会完成最后动作。如果只有成功率,很多中间进步会被掩盖;有了PSR,研究者可以更清楚地知道模型到底差在哪里,是感知不行、动作不稳、双臂协同不好,还是最后的接触控制失败。
05
实验结果说明了什么?真实机器人评测确实能拉开差距
GM-100不是只提出任务清单,也做了真实机器人数据采集和基线模型测试。论文中提到,GM-100建立了超过13,000条遥操作轨迹,并在两种机器人平台上进行评估;评测指标包括SR、PSR和动作预测误差。
从Xtrainer平台前10个任务的真实世界表现看,几个基线模型之间差距很明显。论文表格中,三个基线在前10个任务上的平均PSR大致从7.0%到53.9%不等,平均SR则从1.6%到24.9%不等。这说明GM-100任务既不是完全不可做,也不是过于简单;它能够让不同策略之间出现明显区分。
更有价值的是,论文还分析了动作预测误差与真实任务成功表现之间的关系。结果显示,在Xtrainer环境中,动作预测误差和物理成功表现之间的关系如下:动作预测误差越大,真实执行成功率通常越低;动作预测越准确,真实执行成功率通常越高。
这给VLA模型和机器人策略训练带来一个直接启发:未来模型不能只追求语言理解能力,也不能只在离线数据上看损失函数的下降(模型在已见过的数据上表现越来越好)。真正有意义的是,模型能否把预测出来的动作稳定转化为真实物理世界中的成功操作。换句话说,具身智能最终要过的不是“文本理解考试”,而是“物理执行考试”。
06
GM-100对具身智能行业的启发
GM-100最值得关注的地方,不只是它有100个任务,而是它提供了一种新的评测思路。
第一,机器人评测要从“规模崇拜”转向“结构化任务设计”。过去行业很容易关注数据集有多少条轨迹、覆盖多少机器人平台,但如果任务高度重复,模型仍然可能只是在反复学习少数常见动作。GM-100强调长尾任务和细节动作,本质上是在补足机器人能力评测的盲区。
第二,真实机器人评测会越来越重要。仿真环境成本低、速度快,适合大规模训练和初筛,但接触、摩擦、物体变形、视角遮挡、执行延迟等问题,最终都要在真实机器人上暴露。GM-100把任务放到真实平台上做,有助于筛掉那些只在理想环境里好看的方法。
第三,评测榜单要更加开放和社区化。GM-100官网明确表示,由于真实机器人测试成本很高,结果会逐步释放;同时,团队并不声称能建立一个绝对公平的中心化物理测试环境,而是希望通过开放任务定义、数据、测试流程、视频证据和社区上传结果,形成长期透明的评测生态。
第四,GM-100也会倒逼机器人数据采集方式升级。过去采数据可能更关注“多收一点轨迹”,未来则要更关注任务覆盖、动作原语覆盖、物体可供性覆盖,以及每个任务的评分标准是否清晰。对于做机器人数据工厂、VLA模型训练、遥操作平台、灵巧操作算法的团队来说,这都是很现实的方向。
07
机器人真正的进步,要从细节里看出来
GM-100给人的最大提醒是:具身智能不能只停留在“会说、会看、会抓”的阶段。真正的机器人能力,往往藏在很小的动作细节里。如果说过去的机器人评测更像是在问“模型有没有学会基本动作”,那么GM-100开始追问的是:“模型能不能在真实物理世界里,把复杂、细碎、长尾的动作完成到位?”
这也是GM-100作为“机器人学习奥林匹克”第一步的意义。它更像是一套更真实、更细致、更接近未来通用机器人需求的考题,未来谁能在这样的考题上稳定拿高分,谁才更有资格说自己离真实世界的通用具身智能更近了一步。