作者:Marilyn Liu 出品:具身纪元
文章亮点
一、 机器人学习的三个时代
时代一:存在性证明 (2016–2021)
核心命题:机器人能否像 Atari 游戏或围棋一样,通过数据驱动的深度强化学习(RL)来解决?
关键实践:Google Brain 的“机械臂农场”。
代表工作:
QT-Opt:证明了大规模分布式强化学习在连续动作空间抓取任务中的可行性。
从单任务到多任务:通过 BC-Z、MT-Opt 和 Learning from Play,探索了多任务学习和目标重标注(HER)的可能性。
关键转折:从 RL 转向大规模模仿学习。研究团队意识到 RL 极其痛苦且难以规模化,而通过长达一年半的“埋头苦干”收集专家演示数据,证明了大规模行为克隆(BC)在性能上可以突破瓶颈(从 80% 提升至 95%)。
时代二:基础模型 (2020–2023)
核心命题:如何利用互联网规模的视觉-语言模型(VLM)作为机器人的“大脑”?
代表工作:
RT-1:将机器人动作标记化(Tokenization),引入 Transformer 架构。
SayCan:首次将 LLM 的常识规划能力与机器人的底层技能(价值函数)结合。
RT-2 (VLA):视觉-语言-动作模型的里程碑,将 VLM 直接作为策略骨干网络,实现了惊人的语义泛化能力。
Open X-Embodiment:跨机构合作的大型跨具身数据集,证明了不同形态机器人之间的数据可以迁移。
时代三:全面规模化 (2024–)
核心命题:在 VLA 范式确立后,如何通过扩展模型容量、数据量和具身复杂性来达到通用性?
代表工作:
Gemini Robotics:利用 Gemini 2.0/2.5 系列模型,引入具身推理(ER)和推理时计算(Reasoning at inference time),提升空间感知和长程规划。
异构数据扩展:利用 Aloha、UMI 等硬件采集极高频率、高灵巧的数据;开始大规模利用第一人称视角(Ego)人类视频数据。
现状:处于“研究熵”爆发的探索期。世界模型、视频动作模型、以及 sim-to-real 技术的融合正在重塑领域。
二、 核心观点与技术洞察
1. 范式的切换:从“从头构建”到“全面吸收”
早期的机器人研究倾向于为机器人量身定制模型(如 RT-1 的设计)。
VLA 的成功证明了:直接把互联网训练的 VLM 当作黑盒,仅做最小的调整来适配动作空间,其效果远好于从头构建。
2. 数据是第一生产力
机器人学的进展往往是“研究债务”的偿还。
高质量的遥操作数据和多样化的人类视频数据是目前规模化(Scaling)的核心。
数据飞轮:未来成功的模型将依赖于在真实世界部署中产生的、具有长尾效应的真实分布数据。
3. 工业界与学术界的角色分化
工业界/创业公司:承担了大规模数据采集、硬件协同设计和性能压榨的任务(入场费极高)。
学术界:转向提供算法严谨性、基础性洞察和跨机构的数据协作。
三、 未来展望
技术领跑者:视频动作模型(Video-Action Models)和第一人称人类数据。
机器人的“GPT 时刻”:
技术上:不会是单一时刻,而是类似 GPT-3 到 Instruction Tuning 的一系列突破。
产品上:当出现一个通用的、能民主化地为大众生活增加价值的操作系统时,即为 GPT 时刻。
合并“大脑”与“小脑”:如何将擅长推理、操作的高层智能(大脑)与擅长移动、反应性的底层控制(小脑)整合,是尚未解决的重大开放问题。
关于本期与讲者
本文整理自 RoboPapers 第 78 期播客,主讲嘉宾 Ted Xiao曾经是Google DeepMind 资深研究员,现在是Project Prometheus的founding member,在机器人学习领域深耕超过八年。
他是 QT-Opt、SayCan、RT-1、RT-2、Gemini Robotics 等里程碑工作的核心贡献者。主持人 Michael Cho 与 Ted 相识于 2022 年 CoRL 会议。

Three Eras of Robot Learning — Ted Xiao, RoboPapers, 2026 年 4 月 9 日
时代一:Existence Proofs(2016-2021)
一切始于"机器人能不能像 Atari 和围棋一样被数据驱动地解决"。
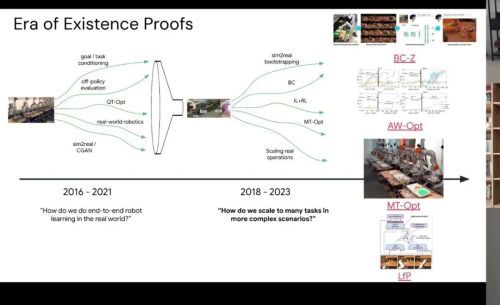
Era of Existence Proofs — 2016-2021 / 2018-2023 时间线,QT-Opt / BC-Z / AW-Opt / MT-Opt / LfP
回到最初,在 2015 年和 2016 年,有一些非常酷的论文出来了——DQN 和 AlphaGo,它们展示了应用数据驱动方法、使用深度强化学习来解决 Atari 电子游戏或者掌握围棋的强大力量。
在那个时候,这些方法能够从自身经验中改进的通用性是非凡的。然后就有了一个疯狂的想法:机器人是否也可以是一个环境,一个马尔可夫决策过程,可以通过同样的数据驱动方法来解决?
如果你看看当时世界的状态,已经有非常高性能的硬件系统了。斯坦福几十年前的视频展示了遥操作的双臂移动操作系统,能够由人类控制来完成各种家务。
问题变成了:如果我们把驱动解决电子游戏和围棋的那些算法,与这个真实世界系统结合起来会怎样?当时的瓶颈似乎完全在于必须远程控制这些系统的人类智能。
这基本上就是让我最初进入机器人领域的原因。当时在伯克利有很多优秀的合作者和研究组——Pieter Abbeel、Sergey 的实验室——一些想法还在形成中。
那时我第一次加入了当时的 Google Brain,加入了这个新的机器人团队,不到 20 个人,就是在尝试:如果我们就直接做呢?如果我们就试着在一个地方集中一个机械臂农场,10 个 Kuka 机器人,让它们全天候 24 小时抓取东西,我们就尝试做在线的真实世界强化学习,那会是什么样子?
QT-Opt:连续动作空间的大规模 RL
我们团队当时最著名的工作叫做 QT-Opt。机器人与标准围棋或电子游戏之间的区别在于,它是一个非常高维的、连续动作空间的系统。
图像观测以相对较高的频率传入,状态和动作空间的维度要大得多。QT-Opt 使用交叉熵方法(cross-entropy method)作为在贝尔曼更新中最大化 Q 值的近似,以此调整那些对 Atari 和围棋有效的基于价值的强化学习方法,使它们适用于大规模机器人学习。
当然,这不仅仅是一个算法创新。你还需要从头搭建一整套系统。如果你要做这种 24 小时机械臂农场数据收集的方式,你需要搭建好的评估系统,需要在真实世界中有好的规模化能力,需要一个好的控制栈。
其中一部分是思考我们如何从那种“想一想、暂停、观察”的模式——你把网络推理嵌入进去,世界暂停,然后你需要重新计算和重新运行推理,然后你再执行,再暂停——转向一个流畅和快速的世界。你实际上必须在行动的同时思考。这就是我们所说的并发强化学习。
在评估方面也有挑战。那是在过去的时代,也许我们还处于 Bullet 的早期阶段,在很多最新最好的 GPU 加速物理仿真出现之前,但我们仍然想利用仿真来做数据生成、联合训练或评估。
我们想要弥合域差距,这样无论策略是在类似的真实数据上训练的,都可以在一个看起来真实的世界中进行推理。所以我们训练了一个 CycleGAN,把模拟图像转换成逼真的图像。那是 GAN 和风格迁移作为最好的图像生成方法的时代。
从单任务到多任务:BC-Z、AW-Opt、MT-Opt、Learning from Play
那是一段有趣的四五年时间,真正让这些系统在规模上运行起来。然后结果就是,端到端学习的机器人学习算是可行了,接下来呢?接下来就是超越单一的任意抓取任务,进入我们能否真正做多任务学习、更复杂的场景。
QT-Opt 系统的框架已经很稳固了,然后你可以在上面尝试很多有趣的研究。
我们可以开始探索模仿学习,用 BC-Z——第一个大规模多任务语言条件模仿学习策略。当时有很多人对将模仿学习的优势与强化学习微调相结合感兴趣。你想要通过行为克隆从专家数据中获得引导启动,但你也想要强化学习的特性,即通过在线经验来改进。这方面有一整条研究线,就是 AW-Opt。
还有一个想法是,我们能否真正把多种技能能力塞进一组神经网络权重中,这就是 MT-Opt,QT-Opt 的多任务扩展。
还有一个想法是,如果真正扩展到一个真正无界的原语和行为集合会是什么样子。这是一项叫做 Learning from Play 的工作,我们采用了后见经验重标注(hindsight experience replay)、目标条件重标注的思想——你取一些轨迹展开,然后取最终实际发生的目标,假装你从一开始就打算这么做——我们用 play 数据把这个推到了极限。
人类专家只是收集任意有用的数据,没有任何明确的、细微的、短期目标在脑中。然后我们只是用潜在计划来重标注这些数据。
"Code Yellowish":从 RL 转向大规模模仿学习的关键决策
我认为事情真正聚焦是在我们退后一步,审视所有这些类似于分拣抓取的变体或不同的算法探索之后,我们真正在数据本身上下了大赌注。
我们大概暂停了一年半,在这期间我们投入了将近 10 台机器人的车队,10 个操作员在各种数百个不同任务中进行专家演示,就是收集这个离线数据集,为一个赌注做准备——训练能够真正在这个微型厨房环境中解决数千个任务的策略。
在这一年半里,我们没有在这个数据集上发表任何论文。我们只是在收集,算是放慢脚步以加速前进。
Q(Michael):回头看,你觉得那一年半所谓的放慢脚步以加速前进,是不是可以更早做,或者以更大的规模做?你会有什么不同的做法?
有几个因素让这件事变得有点复杂。首先当然是这个想法——你需要一个大型、多样化的数据集,数据质量足够高,你达到了离线数据集的临界质量,然后用大规模模仿学习来学习实际上是非常高效的。
我认为这在视觉或语言等领域可能更加显而易见。但在机器人学中,这还不清楚。这仍然是一个由强化学习主导的时代,在线的、on-policy 的反馈仍然被视为王道,从零开始的探索——很多工作在研究探索问题,很多工作试图把模仿学习不是作为完整的解决方案,而只是作为引导启动的方案。
我们当时看到了这样一种现象——行为克隆很有趣,但它只能让你到 70%,要从 70 到 80 到 90 到 95 到 99%,你需要强化学习。这基本上是我们当时的信念。
事实上,我第一次接触大量机器人学习是在伯克利的第一门机器人学习课程上,由 John Schulman、Sergey 和 Chelsea 教授的。行为克隆是第一节课,第一堂讲座。就像是,这是个不错的想法,让我们把在语言和视觉中有效的监督学习拿过来,如果你只是试着对行为轨迹这样做呢?
但你会得到累积误差,你会得到所有这些问题。这就是为什么行为克隆不是一个好主意。这是2016 年的信念。BC 被视为这种简单的玩具方法,只在玩具问题上有效,任何严肃的问题你都需要强化学习。
所以这就是为什么我们花了一些时间才从强化学习世界转向模仿学习世界。另一部分也是运营方面、硬件方面,搭建那个今天已经很标准的遥操作数据规模化技术栈,在当时并不显而易见。
把价值百万美元的机械臂放进一个房间里,然后就收集数据,雇人来管理它们,工程师和技工来维护它们。这就像是你在烧钱而看不到尽头。
甚至硬件也在变化,从 Kuka 转到与 Everyday Robotics 合作,那个单臂移动操作机器人的硬件形态每隔几个月就会变。硬件在变,控制系统、固件,一切都在变。所以要锁定方向、专注于高质量专家数据,并且相信它会对监督学习极其有用——这是非常不显而易见的。
Q(Michael):是什么给了负责人信念,让他们觉得真实世界强化学习探索可能行不通,为什么不干脆加倍投入遥操作数据?
有几个因素形成了完美风暴。我们看到了强化学习在哪些地方有效,但我们也看到了收益递减。
AW-Opt 图中蓝色的线是强化学习,总体趋势是曲线在往上走、往右走,更多经验,更好的提升,这也能迁移到真实世界的评估中。但问题是,当你管理这些分布式系统时,它太复杂了——一部分是仿真,一部分是真实的,然后策略的检查点可能会变得过时,你怎么混合数据、怎么追踪它,也许你的控制器里有某个 bug,你改了一下,突然数据就变得不太有用了。
强化学习是痛苦的。这些是持续活着的怪兽,你得花几周或几个月去训练和管理它们。然后模仿学习一直卡在 60%、70%、80%,就是上不去了。
所以我们进入了一个我们称之为"code yellowish"的时期。Code red 就是所有人放下手头一切,有个东西我们需要修复。Code yellow 就像是,也许不是生死存亡的问题,但有什么东西真的不对了,我们应该投入一些时间来偿还技术债务。这个有点像是让我们偿还一些研究债务。Carol,我团队的前经理,创造了这个术语。
行为克隆的世界上限卡在 80%,不太好。强化学习,极其痛苦和复杂。两者都不是答案。我们能不能找到一种方式,能够在离线数据集上训练,利用高质量的专家演示,同时又能达到我们需要的 80%、90%、95% 的性能?
在这个时期,我们退出了所有这些分支复杂性,当经过各种 bug 修复、重构、完全重写之后,一切都整合到了一起。我们的一位同事 Yao Lu,他是一个基础设施之神,他基本上从头重写了整个训练器。
然后突然间行为克隆就开始 work 了。它不再停滞在 60%、70%、80% 了。它达到了90%、95%。在那个时候,数据很清楚。我们退出了我们的 code yellowish——大规模模仿学习,我们达到了 90%、95%,而且我们随着更多数据在持续提升。
当然这是专家演示数据,不是自主收集的机器人数据,但它确实是更多的真实世界数据。所以它有 scaling 的特性,而且性能很好。这就是我们想要的。我们有了一个配方,模仿学习,开干。
Q(Jiafei):你有没有那种似曾相识的感觉?因为你给的那个并发 RL 的例子让我想到了更简单的方法,用冷启动控制、实时分块。这种想法似乎一遍又一遍地被重新发明。
绝对有。旧的就是新的,研究就是——历史不会重复,但会押韵。也许一个秘密是,机器人学社区是非常结果导向的。
不是说人们在真空中凭空想出一个新想法,虽然经常感觉像是这样。然后你意识到,实际上一些聪明人每一年都在尝试这个,过去十年里,字面意义上他们在尝试完全相同的想法,也许用不同的框架、不同的词汇,但只有当它开始 work 的时候才会变得流行。
我觉得这实际上是一个元评论——在机器学习社区里之前有很多分享负面结果的愿望。但这真的很难,因为一个想法失败的原因太多了,特别是在机器人学中,你的全栈从硬件一直到算法,有太多种方式可能出错。
可能是技术水平问题,可能是一个你控制不了的 bug。所以我们作为一个社区真正取得的进展只能通过成功的想法。某个东西成功的唯一方式是每一个环节都做对了。
我们基本上每年都在尝试同样的 10 个想法,有一些变化,有时候有一些阶跃式的变化。很多非常令人兴奋的想法——我们现在称之为机器人基础模型的东西,或者在更通用的数据分布上学习,使用互联网数据配合 VLA,使用 YouTube 数据,使用人类数据——这些不是今天才想到的想法。
这些是已经存在了几十年的想法,只是恰好今天,对于其中一些想法,也许时机终于对了。
我们有这个实习生项目,使用以自我为中心的人类数据,在 Ego4D 上训练,大概是2023 年的时候。实际上这个项目在四五个不同的实习生之间传递,他们基本上每人花三个月、六个月试图让这个东西 work,就是搞不定,换做别的事情,交接给下一个实习生继续接手。
都是非常聪明的研究者,像 Carl Pershing 和很多其他人,他们在 Google DeepMind 的战壕里付出了努力,试图让人类加机器人的学习 work 起来。也许 2026 年才是合适的时机,但这件事在 Google 过去三年里几乎一直在尝试,很多都没有成功。
太早了,数据不够。Ego4D 实际上并不是一个很好的机器人学习数据集——这现在算是公开的秘密了。但也许一些新的以自我为中心的数据,是在考虑机器人应用的前提下收集的,用了更好的硬件,更好的传感化人类采集。
Q(Jiafei):你觉得这个东西应该在什么时候停下来?在机器学习领域,人们会停下来,因为你开发了 Transformer,之后出现的任何东西都不会比它更好。但在机器人领域,我们还没有看到那样的时刻,你同意吗?
实际来说,机器学习和 AI 的进步是一阵一阵的。我们喜欢把自己看作研究者,但很多时候在 AI 领域,它真的是非常跨学科的,建立在整个社区的伟大工作和贡献之上,我们经常在探索和利用之间来回切换。
一旦有一个有效的配方——也许我们可以把它想象成一个漏斗。当 QT-Opt 效果很好的时候,它就成了一个可以做大量有趣研究的系统。当我们在 code yellowish 之后决定这种端到端的模仿学习是一个好配方时,我们就可以拿来用。后来 VLA 可能是一种你可以在其上进行利用的工具。
我认为证明一个新想法需要巨大的激活能量。但一旦这个想法被证明了,机器人领域的社区尤其会非常快地跳到有效的东西上,通过优化、以巧妙的方式使用它,迅速将性能翻倍、三倍、十倍。但那些大的阶跃式变化发生得更少。
经常有相似之处——使用扩散策略,用扩散作为技术来表示多模态动作分布,动作分块,Aloha 是一个很好的木偶操控系统,使用视频动作模型是一个新方向,以自我为中心的人类数据。
当有一个存在性证明的时候,就像四分钟一英里的故事,一旦有人跑出了四分钟一英里,然后一夜之间很多其他人也会跑出四分钟一英里,他们会找到进一步的优化。然后也许几个月后、一年后,会有另一个突破,人们可以很快地跟上,然后从那里分支出去。
我认为机器人和广义的 AI 就是这样一系列的探索,然后整合,然后再从那里探索。现在在机器人领域,我们绝对处于一个探索的世界,有很多非常有趣的想法正在被探索。可能我们会看到一些整合,可能在未来几年内。
时代二:Foundation Models(2020-2023)
外部基础模型的成熟与内部数据积累的碰撞,催生了机器人自己的基础模型。
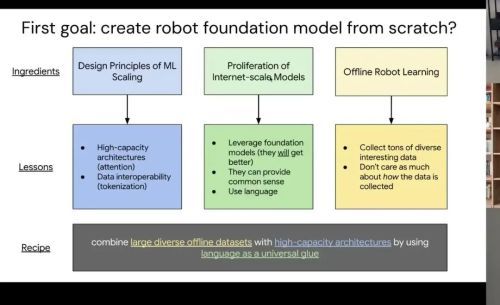
创建机器人基础模型的方法学:高容量架构 + 大规模离线数据 + 语言作为统一胶水
我认为这是一个完美风暴——外部的基础模型在机器人领域之外开始运作良好。ChatGPT 时刻,你开始看到语言模型比如 PaLM 或者 VLM 比如 PaLI 开始从 Google 真正运作良好,当然还有外部的其他模型。
从这里开始,你有了这种外星科技——这些在互联网上训练的语言模型展现出真正的通用性和涌现能力。你看到机器人现在从在线世界转向离线世界,从由策略收集的在线体验式真实世界经验,转向由人类收集大规模高质量离线数据集,然后使用监督学习。
这些世界正在越来越接近,让我们可以思考如何利用基础模型,以及如何构建我们自己的机器人基础模型。
广泛来说,至少对于 RT-1 来说,这是一个碰撞——让我们把机器人领域之外 ML 规模化中有效的东西拿过来,让我们把已经存在的模型、预训练表征、基础模型拿过来,我们可以把它们当作黑盒来用。
然后让我们把我们正在收集的大规模数据集拿过来,特别是在那一年半的减速加速期间,我们收集了大约87,000 条机器人操作轨迹。当我们把这些组合成一个配方时会发生什么。
RT-1:Robotics Transformer 1
第一个成果就是 RT-1,Robotics Transformer 1,我们使用了标记化、离散化,把机器人动作和语言都作为 token。一切都是 token,token 输入,token 输出。
当然,为了让这些 VLM 以3Hz运行,你需要做一些技巧——更高效的视觉编码器,某种 token 压缩。但归根结底,它是一个 Transformer,五百万参数,在当时算是相当大的,特别是跟 QT-Opt 相比。
我们看到了当你有这种标记化输入、标记化输出、以 3Hz 运行、在这个 87,000 条轨迹数据集上训练时会发生什么。结果证明它实际上相当通用,能做很多事情。它完全碾压了我们之前所有的基线,我们之前的行为克隆、ResNet-18 基线都被远远甩在后面。
SayCan:语言模型与机器人的第一次接触
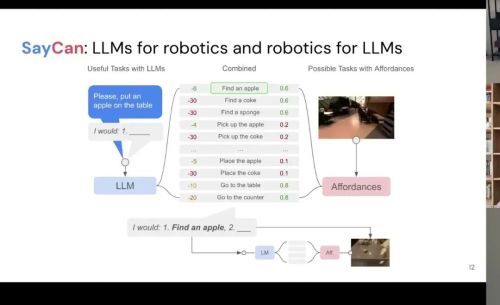
SayCan:LLMs for robotics and robotics for LLMs
我们不只是想从头创建一个新的基础模型,我们还想把它与当时已经存在的基础模型结合起来。SayCan 是我们团队最早真正非常受欢迎的工作之一,我们把语言模型作为规划器,然后把它们与它们擅长的东西融合在一起——也许是规划、常识推理——但我们确保能够将它们锚定在机器人实际能做的事情上。
我们把语言模型的预测——比如"你会怎么把苹果放到桌子上",我会用空白来做机器人规划——然后我们会把它与一个价值函数进行加权,这个价值函数代表了可供性(affordances),即机器人在给定情境下实际能做什么。
通过将语言模型认为正确的规划和推理,与机器人通过价值函数实际能做的事情进行加权,你就得到了一个既合理又可实现的计划。
这非常酷,因为这实际上在技术上比 RT-1 还早发布,所以这算是我们第一次分享了我们一年半投入到大规模模仿学习流水线中的成果。这是语言模型和机器人之间的第一次接触。
这是一篇闪亮的 Google 论文——我觉得这是我们发现 Fei 实际上是一位出色的摄影师的时候,他拍出了非常精良的制作品质。他确实做了很多来提高标准,对未来很多机器人领域的发布都有影响,现在每个项目都需要一个制作精良的炫酷视频。
这确实是一个爆款——闪亮的语言模型,一个非常高性能的操作系统。这是我们第一次发布这种微型厨房、多任务环境。它对每个人都有吸引力——有 AI 的前沿技术,有机器人技术,有向模仿学习设置的转变。
当这个登上了纽约时报头版的时候,我们都把它打印出来贴在办公室周围。那是一个非常酷的时刻——也许这个基础模型的东西,也许真的有点名堂。
这大概是 ChatGPT 出来前几个月,但很多当时的经验教训——比如一些来自 GPT-2 和 GPT-3 的初始缩放定律——都很有趣。就是在那个时间段前后,大语言模型真正变得足够好,可以做有趣的事情。
从 SayCan 到 RT-2:VLM 作为策略骨干网络
这只是我们可以将现成的语言模型用于机器人技术的一种方式,但还有很多其他方式。我们可以用它来做数据增强。
有一个叫 DIAL 的工作,我们在其中采用了用 VLM 进行合成数据生成的想法。它们会拿我们的 87,000 条轨迹数据集,然后使用视觉语言模型来重新标注它,有点像后见重标注(hindsight relabeling),但是在语言空间中重新标注成一个数百万条轨迹的数据集,然后我们可以在上面训练,突然之间我们就获得了更好的语言泛化能力。
RT-1 和 SayCan 的原始 87,000 条轨迹数据集只有500 个任务。当然,在现实中,你可能想要泛化到更多更多的任务。
但把这个想法推得更远,你可能会问,与其只是把 VLM 用作规划器或数据标注器,我们能不能直接把它用作骨干网络本身?
我觉得这在事后看来是显而易见的,但在当时人们觉得这些模型太大了,推理会太慢,不清楚这些互联网训练数据是否真的有用,我们真的应该限制 LLM 的角色——它们只是一个黑盒,我们会把它们拉进我们的系统,但不把它们用作策略本身。
所以当我们提出视觉语言动作模型(VLA)的想法时——我们会做联合训练,我们会把机器人动作预测变成一个 VQA 任务,然后看看会发生什么。我们在从5B 到 55B的模型上进行了训练,这当然比现在基于 PaliGemma 的开源 VLA 要大得多,但在当时这是一个有趣的概念验证。
我们看到了大量涌现的推理和泛化能力,再一次把 RT-1 远远甩在后面。
这也是开始关注合作的时代,因为一旦我们尝到了规模的甜头,就会上瘾——我们扩展了骨干网络,扩展了系统中的组件,扩展了内部收集的机器人数据。也许我们还应该扩展具身形态。
我们能不能在来自任意机器人具身形态的数据上训练?然后就有了现在相当著名的 Open X-Embodiment 项目,我们与34 个不同的研究机构合作——你们已经为自己的项目收集了数据,我们把它整合起来,放到一个统一的格式中,开源出来,然后任何人都可以使用。
我们最终在这个跨具身数据集上训练了 RT-2 和 RT-1 的骨干网络。结果发现,在一个机器人上收集的一些技能和行为实际上可以迁移到另一个机器人上,特别是与语言相关的东西,或者对"推到旁边"与"推到上面"与"推到里面"这类描述的理解。这些是我们做跨具身训练时开始涌现的东西。
动作表征的探索:MOO、RT-H、RT-Affordance、RT-Trajectory
机器人基础模型的动作表征家族:MOO / RT-H / RT-Affordance / RT-Trajectory
我们也能够开始研究一些研究问题了,因为现在我们有了这个很棒的工具——这个离线数据集,87,000 条轨迹数据集,有了像 RT-1 和 RT-2 这样的骨干网络。我们现在可以开始调整和优化这些设计决策。
我个人非常感兴趣的一个领域是动作表征,它可以帮助你泛化到分布外的场景。默认数据集有这种非常简单的合成式结构化文本——动词名词之类的非常简单的东西。但有没有办法扩展它?
我们研究了很多不同的方式来做这件事:用边界框或分割掩码(MOO),用那种思维链把长时间跨度的指令分解为策略内部更短时间跨度的指令(RT-H),研究可供性(RT-Affordance),研究轨迹——这些轨迹甚至可以通过自我中心位姿追踪来指定(RT-Trajectory)。
有很多非常有创意的想法,而且所有这些都因为你有了 RT-1 或 RT-2 这个初始骨干网络而加速了,你可以快速尝试新想法并观察涌现出的特性。
这真的突显了那种力量——什么时候某个东西才算真正有效?我认为当你有了那种临界质量的起点时,事情才真正开始有效。一旦你有了 RT-1 和 RT-2 这样非常好的基线,尝试一个新的创新想法并取得非常快的进展就变得很容易了。
Q(Michael):假设你看到了今天的所有进展,然后你回到那个基础模型的时代,你会改变什么?
我认为 VLA 是一个本可以至少提前一年发生的想法。我们已经花了很多时间从头创建 RT-1——所有的设计决策,FiLM 条件化和集合交叉注意力,在尝试了不同选项后选择 EfficientNet 作为视觉编码器,尝试 Token Learner 进行压缩。
很多这些我们都是从相邻领域从头构建所有这些组件,试图从一开始就为机器人技术创建这个弗兰肯斯坦式的组合。当然,在整个领域中,有很多趋势,比如让我们使用预训练的视觉表征,像 R3M 这样非常好的表征。但这是非常模块化的,你从其他领域只取你需要的最少部分,不多取。
而 VLA 的理念是,不,让我们把一切都拿过来。让我们去找他们。让我们拿过来训练栈、基础设施、预训练数据集、联合训练。让我们从视觉和语言领域的同行那里拿走一切,然后只做最小的 epsilon 级别的改动,让这些方法适用于机器人技术,而不是从头做这一切。
我认为在机器人技术领域,我们有一种倾向,试图从头做所有事情,因为那种感觉就像是我们要对机器人完成任务负责,如果你有完全的控制权,你在任何想要的地方取得进展都有更大的灵活性。
但 VLA 需要一种信仰的飞跃——你只是相信 VLM 是聪明的,而且一旦你把 VLM 当作黑盒子,有些东西你就不能再打开它去修改了。做出这个飞跃确实有点吓人,但我认为我们本可以提前一年做出这个飞跃。
但是,很多其他想法——比如切换到双臂或灵巧操作,或者思考机器人预训练和后训练——我认为在那时候还太早了。你还没有这些基础的基础模型。
这 87,000 条轨迹在单臂桌面操作设置上,在当时已经是疯狂的了。后来 Berkeley 的开源 Bridge 数据集跟进了,但这仍然不像我们今天所处的超大规模扩展时代,那个数字现在看起来很小。
如果你把 80,000 条轨迹转换成小时数,那大概是几百个小时,甚至还不到几千个小时。我们现在在机器人技术中的数据量比那时候多了两个、三个、四个数量级。
我真的很喜欢最近 Generalist 发布的 Gen 1,他们在5,000 小时的交互数据上进行预训练。很多那些特性在当时根本不可能实现。
为了获得信心和洞察力来收集那种高质量的传感器化数据——今天我们确实有了——我不认为在当时有可能直接跳到那一步。你需要经历硬件、运营、经验教训的共同发展,还要等待生态系统中的其他组件准备就绪,然后你才能真正做出那个飞跃。
所以最多,你可以把 VLA 加速一年,但其他组件,我不确定会有戏剧性的不同。
时代三:Scaling(2024-)
VLA 范式确立后,整个领域进入"什么都要扩"的阶段。

What's being scaled?— 模型通用性、模型性能、机器人数据量、机器人数据异构性、研究
在 VLA 之后,很明显 VLA 是一个非常强大的想法。如果我们受限于骨干网络或数据,那就两者都扩展。整个世界都在超大规模扩展——Physical Intelligence 成立了,Generalist 也是。有第一波大量机器人研究者在想,好的,现在是时候了,VLA 是一个范式,让我们扩展它。
我认为还有其他一些趋势。我们看到 Aloha 平台非常好——Aloha 1 当然是 Tony 在 Stanford 开发的,Aloha 2 是他在 Google DeepMind 待了一年期间开发的。
其中的洞察是真正高质量的数据可以让你获得非常高频率的控制,真正能把灵巧性发挥到极致。这个双臂系统非常快、非常直觉化,能做到你在单臂七自由度移动操作平台上永远无法想象的事情。
Gemini Robotics:骨干模型、数据与具身复杂性的全面规模化
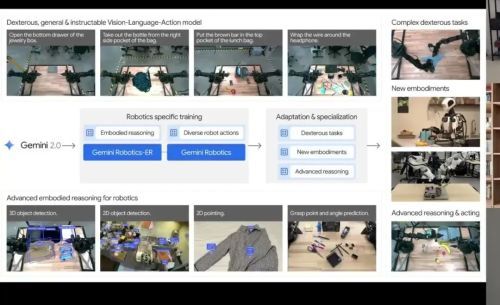
Gemini Robotics — 灵巧、通用、可指令的视觉-语言-动作模型
Gemini Robotics 这项工作于 2025 年 3 月首次发布,大概是在 RT-2 和我们刚才展示的第一批机器人基础模型之后一年到一年半。这是在具身复杂性方面的扩展——Aloha 和电子人形机器人要复杂得多。如果你掌握了这些平台,它们能做到的能力范围比单臂的 Everyday Robotics 机器人强得多。
骨干模型当然是Gemini 2.0,当时我们从 Gemini 分叉出 Gemini Robotics 的时候,它已经是一个非常强大的模型了。Gemini 一直是一个非常好的多模态模型——我觉得我们可以争论它在其他领域的表现,比如多轮对话或代码,但在多模态理解图像和视频方面,它一直是一个非常出色的模型。
数据的规模化方面,我们从未公布过我们在 Aloha 平台上有多少数据,但它比我们在一年半时间里收集的 87,000 条轨迹要大得多。
在 Gemini 2 上,有一件有趣的事情——之前我们基本上不去看 VLM 内部,我们只是把 PaLI 作为 RT-2 的骨干模型,觉得好吧,就按原样用它。
对于 Gemini,有趣的是我们很多人都对看看香肠工厂内部很感兴趣——我自己、Fei Xia、Jackie Liang,还有很多其他人——看看我们是如何训练像 Gemini 这样非常强大的通用视觉语言模型的,然后意识到机器人领域很多人的抱怨——VLM 会产生幻觉,它们没有物理常识,它们没有空间推理和时间推理的概念,我们不能依赖它们做的任何事情——在 Gemini 团队里,我们实际上有机会也有责任去改进这些问题。
我们做的就是 Gemini Robotics ER 模型,这个具身推理(Embodied Reasoning)团队研究了如何改进空间推理,改进这些 VLM 中缺乏的那种常识性物理直觉。
Gemini Robotics ER 是一个非常酷的 VLM,它能做 3D 物体检测、2D 指向和预测物体的抓取角度。然后我们利用它来训练 Gemini Robotics VLA,使其能够做更多灵巧操作,做更多之前的 VLA 所不具备的泛化能力。
Gemini Robotics 的下一个迭代版本在九月份 CoRL 之前发布了——Gemini Robotics 1.5,它同样有两个部分。VLM 部分 Gemini Robotics ER 1.5 这次是一个推理模型。
我们现在处于Gemini 2.5之后的推理时代,在 DeepSeek 之后,在 GPT O 系列之后,整个世界都意识到了这种后训练——使用思考和推理时计算扩展——对 VLM 来说真的很强大,我们能不能也用这个来改进具身推理?结果证明我们确实可以。
从那个模型出发,我们开发了 Gemini Robotics 1.5 VLA,我认为它有两个主要贡献。一个是就像思考帮助了 VLM 一样,思考也能帮助 VLA——用文本思考来规划下一步该做什么,把长时间跨度的动作分解成更短时间跨度的语言指令。
另一个是运动迁移——我们如何从不同的具身平台收集经验,并且不需要后训练,直接将这些运动迁移到其他具身平台。
同一个神经网络能够从非常不同的平台获取具身经验——从人形机器人、从 Franka、从 Aloha——然后在它们之间迁移运动。对比几年前的 Open X-Embodiment 工作,那些全都是单臂桌面机器人,具有可比较的动作空间。现在这些是三种完全不同的具身平台,具有非常不同的运动学特性,非常不同的操纵世界的方式,而现在我们看到了它们之间的迁移。
模型性能的规模化
Model Performance — Learning from Experience / Generalization / Scalable Evaluations
我认为有一些关键趋势正在发生。我们从 Pi 0.6 和其他方法中看到,这种机器人后训练范式——如何将一个相当好的通用策略从泛化能力适配到特定的长时间跨度、精度导向的任务,比如 Pi 在 NeurIPS 上展示的现场演示,那个非常长时间跨度的组装任务。
我们也看到了从 Skilled 和其他玩家那里,比如 GPU 组装,或者从 Dyna 那里,他们在不同的叠衣服任务上做后训练。
泛化能力的规模化对很多机器人基础模型公司来说非常重要——它们在新情况下的泛化能力,我们在指令、动作和视觉泛化方面看到的表现确实令人瞩目。
评估变得非常重要。当我们声称我们的模型能做所有事情时,我们必须用证据支撑。而在现实世界中在一个实验室里运行所有这些试验是非常困难的。
所以现在有一些方法尝试在仿真中用 real-to-sim 评估来做,有一些方法可以将这些评估分布到世界各地——比如 Carl 和其他人做的 Robo Arena——或者使用世界模型来做评估,比如 One X 展示的工作,或者我们在 Google 展示的工作。
机器人数据的规模化

Robot Data Scaling — UMI 式硬件 / 第一视角人类数据 / 真实世界部署数据
数据本身的规模化方面,有关于硬件、采集和模型协同设计的规模化思考。我对 Generalist 和 Sunday 从一开始就思考如何真正把类 UMI 硬件推到极限的工作印象非常深刻。
当然还有最近的自我中心数据工作。这是当下最酷的方向——如何规模化人类数据?来自 NVIDIA、来自不同地方、来自 PI、来自 Georgia Tech的工作。在自我中心人类数据规模化和能够消费这些数据的方法方面,正在发生真正惊人的事情。
还有产品——部署产品,获得那种 Tesla 数据飞轮,其中你的数据成本可能被这样一个事实所补贴:当你收集数据作为一种副作用时,你为某人的生活增加了价值。
无论是遥操作,无论是自主的,你都能获得那种真实世界的数据分布,然后你开始挖掘长尾中所有那些罕见的、在野外的情况,这些最终你都需要解决。
研究熵的规模化
我认为研究熵也在被规模化,也许这是我对机器人学习最兴奋的事情——我们现在处于一个阶段,我们不在一个收敛阶段,我们在一个探索阶段。
从来没有这么多观点的多样性,以及非常聪明的人带着很强的信念在各种方向上推进——无论是世界模型和视频动作模型,无论是用人类数据的无机器人数据,或者传感器化的人类数据,或者 UMI 数据,无论是利用我们在机器人领域之外的前沿实验室中看到的可验证奖励训练范式——我们如何把它引入机器人领域?
今天所有的讨论都是关于操作的,但移动(locomotion)也经历了类似的寒武纪大爆发,技术进步和成熟度也在提升。跳舞的、后空翻的、功夫机器人,现在几乎已经商品化了。
但整条技术路线都是用 sim-to-real 全身控制完成的,方法非常不同——那完全是零样本的 sim-to-real,那是 on-policy 的强化学习,在线强化学习,在非常小的网络上。
很有意思的是,很多人把操作领域比作模拟人脑中发生的事情——用一种非常智能的第一性视角,从演示中学习,从专家数据中学习,监督学习——而移动领域发生的很多事情更接近于小脑,或者说来自下脊髓的那种反应性或本能性的东西。
问题是我们如何合并这两个世界,以及我们如何把操作的世界与推理的世界合并——比如你在下棋,也许两者兼有。这些都是非常有趣的开放问题。我很确定无论我们看到什么样的突破,都将再次彻底改变这个领域。
对话尾声
Q(Michael):学术研究在机器人学习中的角色是如何转变的?今天在机器人学习领域做学术研究还会有意义吗?
有不同形式的影响力。这几乎是在说明这个领域的成熟度——实际商业化这些想法的潜力现在甚至变得可能了。
有些事情在工业界做起来确实容易得多。我会把这种有主见的数据规模化,这种硬件-数据-模型协同设计,看作是只有在创业公司中、从一开始就有坚定信念才可能做到的事情。Generalist 和 Sunday 也花了一年、一年半的时间埋头苦干才达到看到非常出色性能的临界质量。
我觉得当学术界在能力上竞争时,跨机构合作将非常关键,因为我们处在一个演示很好但结果和能力更重要的世界里。一个在排行榜上名列前茅的模型会来自学术界吗,我不太确定。
计算需求、数据需求、运营需求——现在要迭代模型设计,很多就是在机器人旁边流血流汗流泪,要有接触一个机器人车队的机会。很多这些入场费相当高。
我确实认为学术界的角色在变化——在能力方面、在性能方面、在应用和商业化方面,学术界比以前离这些更远了。以前你可能直接把学术界的想法商业化为产品。
现在这个角色被工业界承担了——工业界是那个中间人,把东西规模化,在机器人能有多好的最前沿尝试各种想法。学术界提供洞察、严谨性,提供基础性的想法,但要验证这些想法,需要在工业界发生。
这也是为什么很多在机器人领域非常强的学者,他们很多人在工业界或创业公司有兼职角色,或者很多人在休假做自己的创业公司。
Q(Michael):你怎么看开源在机器人领域的角色?
我觉得有点遗憾的是,如果现在所有的创业公司和工业界把他们拥有的一切都开源了,我们可能会有多一个、两个、三个数量级的数据,可能就能解决整个问题了。
这是科学得以推进的方式。我们现在显然处于一个研究的时代,所有这些疯狂的想法——如果这是几年前,我们会取得非常快速的进展。但现在我们处于一个每个人都在自己的孤岛里的时代。
如果你在大量押注视频动作模型,或者你在大量押注第一人称视角数据,也许以前我们理论上可以更快地回答其中一些问题,如果我们一直在分享的话。
对于那些在分享的人来说,所有的协作努力加起来就像一个 Pi 的量级或更少。当然很难去要求——嘿 Pi,嘿 Skilled,嘿 Generalist,就把你们所有的知识产权都发布给全世界——那花了他们一年半和非常艰苦的工作才做出来的。
这有点像这种奇怪的结构——也许我们对人类来说不是全局最优的,但我们对每个玩家来说是局部最优的。我只是有时候会怀念过去的好日子,那时候一切默认都是发表的,每个人都在分享最新的工作。
Q(Michael):有没有什么旧的想法你觉得也许是时候重新拿出来了?
我觉得也许有一件事——这种从玩耍中学习(Learning from Play)的设定,你真正去覆盖状态空间,你只是在做有用的任务,但不是带着一个目标。
然后你就允许人类的好奇心去探索整个搜索空间,然后使用后见目标重标注来从中回溯。在当时,这非常困难,因为数据规模太小,在真实世界中做 play 数据收集是非常困难的。
当然其他人,比如 Freiburg 的 Oier Mees 当时建立了这种从玩耍中学习的设定。但从那以后就没有被真正认真地尝试过。
但现在在 Generalist 的 50 万小时的时代,或者我们可能已经在用一些第一人称视角数据创业公司达到百万小时的数据集了,也许这实际上已经足够了,我们正在充分覆盖全局状态空间,使得恢复这种类似玩耍的探索实际上是可行的。
因为以前,我们从来没有充分覆盖过,我们必须非常有策略地决定在哪里花费我们的真实世界预算。但也许现在我们实际上可以做到了。
Q(Jiafei):你觉得什么时候你会被说服这确实是机器人的 GPT 时刻?你需要看到什么?
对于这个问题,我总是把它解耦成两个部分。第一个问题是,什么技术研究突破是 ChatGPT 时刻?是 Transformer 吗?是 GPT-2 吗?是 GPT-3 吗?Scaling laws?是 GPT-3.5 的 instruction tuning?
我认为有很多这些东西共同构成了技术层面的突破。ChatGPT 本身在大概22 年 12 月,我认为那是一个用户体验的事情——就像一个周末项目,有人说让我们把这个变成一个多轮聊天机器人然后发布出去,然后它就火了。
部分原因是产品形态。我们称之为 ChatGPT 时刻是因为人们喜欢它——它足够好,以至于来自世界各地、拥有不同经验和技术背景的人都能使用它并从中获得价值,而且这是一种令人愉悦的体验。
产品部分对我来说更容易回答。机器人领域的 ChatGPT 时刻将会是当出现某种通用操作系统,它触及社会的一大批人,而不仅仅是一小部分——当它变得如此易用,如此令人愉悦,当它以一种非常民主化的方式为人们的生活增加价值。
我不确定我们是否会在接下来一两年内看到这种面向社会的 GPT 消费者时刻。我真的希望如此。我在所有的等待名单上,一旦消费者版本发布我就交了定金。
可能我们正处于一个十年的早期阶段,就像自动驾驶从第一次自动驾驶爆发到 Waymo、Tesla 和 Cruise 在旧金山到处跑所经历的那个十年一样。
在技术层面,也很难归因。即使对于语言模型来说,也没有一个单一的病毒式传播时刻让一切突然就通了。对于机器人技术来说,同样会是多个部分的组合,所有这些结合在一起达到了实用性的最低门槛。
我们是否已经到了那个阶段,我不确定。很多公司确实这么认为,认为我们处于执行模式。我也认为很多非常聪明的研究人员认为我们还需要另一个突破。
如果今天我们必须在这些想法中押注,我认为必须是视频动作模型和第一人称视角数据——它们是领跑者。在产品方面,如果有一个产品在接下来一两年内成功,我认为必须是 Generalist 或者 Sunday。他们一直非常专注于端到端用户体验是什么样子。
在消费者方面,我看好那种为家庭定制共同设计的产品;在研究想法方面,我看好视频动作模型或人类数据。