作者:彭堃方
编辑:吕鑫燚
出品:具身研习社
VLA正在长出下一代“大脑”。
世界模型概念升温过程中,行业开始反复提及同一个问题:VLA时代是不是已经结束了?
这种论调,不仅不懂技术演进的基本逻辑,也没有看透具身智能模型发展的本质。
模型究竟该怎么走,归根结底还是对任务的拆解。机器人进入真实场景,始终绕不开三件事:看见环境、理解指令、完成动作。只要这三件事还成立,视觉、语言、行动这组基本结构就不会凭空消失,真正变化的,只会是它们如何被组织、如何被增强,以及如何从“能动起来”继续走向“动得更稳、更快、更像一个真正的智能体”。
4 月 23 日,在 2026 POWER Robot 未来大会主论坛上,智平方创始人兼 CEO 郭彦东给出的判断很明确:VLA 没有终结,反而正在持续变得更强,它仍是通往物理世界智能的最强主航道。在现场,郭彦东第一次把智平方对 VLA 演进路径的理解完整摆到台前:过去是统一感知、理解与行动的端到端 VLA,现在是融合世界模型能力的增强型 VLA,未来则会进一步迈向类脑机制的全新阶段。

这次表态真正重要的地方,不只是为 VLA 站队,而是把行业里那种“VLA 与世界模型二选一”的讨论,重新拉回到更真实的技术演进逻辑里:世界模型不该是宣告 VLA 失效,而是在补足 VLA;而类脑机制也不是另起炉灶的平行路线,它将是下一代 VLA 的结构方向。
顺着这条逻辑看,智平方这次同步对外披露的类脑架构 VLA 具身大模型 NeuroVLA,以及一站式具身智能模型开源社区 AlphaBrain Platform,就不再是两个彼此独立的动作,它可以看作同一个判断的两面:一面指向下一代“机器人大脑”会如何演进,另一面则指向这套能力将如何被开放、被复用、被快速带进整个行业。

虽然郭彦东认为VLA一直站在主航道上,但过去一段时间行业内关于世界模型的讨论甚嚣尘上,以至于出现“VLA已经走到头”的武断之词。
从技术的第一性原理出发,方能感受到该论调的偏见。在智平方看来,早期VLA解决的是“听懂并动起来”的问题。世界模型的加入,则让系统多了一步,在执行之前,先在“脑子里跑一遍”。
更重要的是,智平方对世界模型的理解并不是把它作为VLA之外的外接模块。早在2023年下半年,智平方便率先提出,世界模型不应悬浮在VLA之外,而应深度内生于模型之中。顺着这一判断,智平方自研的大模型AlphaBrain在2025年11月吸纳了新一代架构Video2Act的最新成果,实现了“先预测、后执行”。在第三方评测中,相较于硅谷同类标杆模型,AlphaBrain取得了超过30%的性能领先,也证明了环境理解与动作执行一体化路线的优势。
所以换种思考,业内这波世界模型的热度,与其说在替代VLA,不如说是在把VLA往前推了一步。模型从一个偏执行的系统,慢慢长出预测和规划能力。
但当机器人真正进入真实环境之后,很快会遇到另一类问题:很多困难并不发生在“理解错了任务”,而是发生在动作细节上。比如动作有没有抖、节奏稳不稳、碰到干扰能不能立刻调整,这些问题更偏向“身体层面”。
于是,智平方更进一步提出了“类脑模型”。
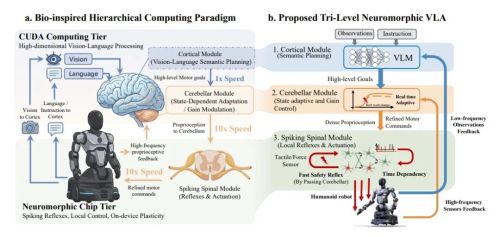
在NeuroVLA论文中,团队提到一个很关键的观察:现有VLA在动态场景、节奏任务和精细操作上,和人类还有明显差距,一个重要原因在于系统长期依赖低频视觉反馈,缺少高频本体感觉、短时运动记忆和实时调整机制。
换个更直观的说法,机器人一直在长“大脑”,但本能式反应的“小脑”和“脊髓”这部分长期缺失。这里需要解释一下,智平方所说的“小脑”“脊髓”业内过去仅拿来做locomotion,但很少有融入到manipulation(操作)之中的。
NeuroVLA做的事情,就是把这部分补上。它采用类似“大脑—小脑—脊髓”的分层结构:上层负责语义理解和规划,中间层处理高频反馈和动作修正,底层负责快速执行和反射。而这套结构带来的变化,指向三个过去机器人长期难以补齐的能力:动态稳定性、超快反射和极低能耗。
比如,在执行精细操作时,机器人不再只是依赖低频视觉反馈慢慢纠偏,而是可以通过高频本体感觉持续修正动作;当外部碰撞突然发生时,安全反射可以在20毫秒以内触发,而20ms什么概念?人类眨眼速度最快是100ms;更关键的是,底层“脊髓”层依靠事件驱动的神经形态计算,执行任务时平均功耗仅0.4瓦,相当于你未插手机的充电器保持待机的功率。
这意味着,机器人开始从靠大脑想明白再行动,走向了身体自己也会反应的新阶段。过去我们讨论机器人大脑,更多关心它能不能理解指令、拆解任务、规划步骤;但进入真实物理世界后,很多能力其实发生在更低层:手臂稳不稳、碰撞能不能缩回、动作能不能省电、能不能长时间部署。NeuroVLA的意义就在这里,它让VLA开始长出类似生物的本能反应。
从这个角度看,NeuroVLA更像是VLA的一次结构升级。它把系统从“理解+执行”,推进到“理解+预测+控制+纠偏+反射”的完整链条。

如果说NeuroVLA代表了智平方对下一代机器人大脑的判断,那么AlphaBrain Platform则代表了另一层更现实的产业意图:这套能力不能只停留在少数头部团队手里,而要变成整个行业可调用、可验证、可迭代的基础能力。
这次智平方没有把最前沿的类脑模型藏起来,而是把NeuroVLA同步纳入AlphaBrain Platform。按照郭彦东在大会上的介绍,AlphaBrain Platform不是传统意义上只开源一个模型或一段代码,而是打通“数据—训练—模型—评测”的完整链路,试图提供一个一站式、开箱即用的具身智能模型开源社区。

它真正有辨识度的地方,主要体现在三条线上。
第一条,是NeuroVLA,对应类脑路线。它把高频本体感觉、短时运动记忆、实时运动调整和安全反射纳入VLA体系,在机器人“想”之外,把“做”进化为某种生物本能。
第二条,是RL Token,对应“强化学习+VLA”的低门槛落地。它解决的是一个长期悬而未决的问题:大模型能理解,但很难真正把动作做到位。过去强化学习能提升动作表现,但成本高、门槛高,还容易把原有能力“练没了”,很难成为规模化路径。
RL Token的意义在于,把强化学习嵌入到VLA体系中,变成一种可以持续调用的能力。模型先具备通用理解,再围绕具体场景做后训练微调,让动作在真实环境里一点点变得更稳、更准。这种路径更接近工程现实:不推倒重来,而是在已有能力上持续打磨。更关键的是,它把成本和复杂度压了下来。通过冻结VLA主体,只训练轻量模块,强化学习从“重资产实验”变成“可复用工具”。这一步让大模型开始真正接近落地,而不是停留在演示效果。
第三条,是可插拔世界模型架构,对应世界模型的工程化。行业对世界模型的讨论已经很多,但真正难的部分是如何用起来。不同路线之间难以对比、难以集成,也很难放进同一套任务系统里验证。可插拔架构把这个问题拆开处理。不同世界模型可以在同一任务中直接切换、测试和复现,开发者可以清楚看到每一条路线的差异,而不需要反复搭环境、改系统。

这一步的意义,在于把世界模型从研究能力,变成基础设施。机器人在行动前的“预演能力”开始进入工程系统,同时也让模型路线的竞争第一次有了统一的比较坐标。
所以,AlphaBrain Platform开源的不是一个单点模型,而是一整套“机器人大脑”的生产方式。它把数据、训练、模型、评测这些原本分散在不同团队、不同系统里的能力重新组织起来,让行业可以在同一套框架下比较模型、复现实验、迭代能力。

为什么这件事由智平方来做,其实并不算意外。
行业里常说它是“最像特斯拉的中国机器人公司”,这不是标签,而是对路线契合的精准提炼。
一方面是他们的开源精神,AlphaBrain Platform社区是鲜明的例证。特斯拉开源Optimus 硬件,尤其是前段时间开源了新一代灵巧手专利,助力硬件端的最难卡点释放。而智平方则是开源了软件端最难的具身大模型。二者遥相呼应,在这一意义上“中国特斯拉”无可厚非。
但如果往深一点看,这个类比更多是在指一种结构:模型、硬件、场景三位一体。
特斯拉在自动驾驶和机器人上的路径,很少把模型、硬件或场景单独看,而是放在一个系统里不断循环。机器人行业也正在往这个方向走。这个行业最终比拼的也不会只是模型参数、单机性能或某一个场景的订单,那些能让模型在硬件上跑起来,在场景里用起来,再通过真实数据持续长出来的智能才有可能得到延承。
智平方这几年的路径,也比较一致。
在模型上,从早期VLA,到快慢系统,再到世界模型融合,直到这次NeuroVLA,智平方的技术路线始终具有连续性。它没有追逐概念,而是在VLA这条主航道上不断补能力、补结构、补闭环。
在硬件上,智平方也并没有把机器人本体看成模型的附属品,而是坚持用大模型正向定义机器人本体。据了解,其核心零部件无故障运行时间超过5万小时,并通过自建产线保障量产交付。
在场景上,智平方已经落地汽车、半导体显示、生物科技、公共服务、新零售等十余个高价值场景,尤其是智慧店员舱体“智魔方”推出不到半年,已经在中国十余个省市实现常态化运营。

这也是AlphaBrain Platform值得关注的原因。一个只有模型的团队开源模型,更多是技术交流;一个同时拥有模型、硬件和场景验证的团队开源“机器人大脑工具箱”,则更像是在开放一套经过真实世界检验的生产方法。
具身智能产业已经走到一个新阶段。过去,大家需要证明机器人能动起来;现在,大家要证明机器人能在真实场景里稳定工作;再往后,机器人还要在工作中持续学习、持续纠偏、持续进化。
VLA没有终结,它正在融合世界模型,“长出”小脑和脊髓,长出更接近身体智能的下一代结构。
而机器人大脑的竞争,也将从单纯的模型能力之争,走向体系能力、开源生态和真实场景闭环之争。真正的智能,终究不是停留在屏幕里的推理能力,而是进入世界之后,仍然能够稳定、敏捷、安全地改变世界。
最终能留下来的,不会只是“最聪明”的模型,那些在真实世界里,既能理解、又能行动,还能长期稳定运行的系统会更有生命力。