过去一年,随着世界模型、物理模型等概念持续升温,行业中出现了一种颇具争议的声音——VLA(视觉-语言-行动)时代正在走向终结。甚至有人断言:世界模型将取代VLA。
4月23日,在2026 POWER Robot未来大会主论坛的开场演讲上,智平方创始人兼CEO郭彦东博士用一场题为《AGI迈进物理世界:通用智能机器人开启第四代智能终端时代》的演讲,正面回应了这一说法。
这位横跨微软、OPPO、小鹏汽车,如今又投身具身智能创业的“AI+智能终端”代表人物,以其一贯的技术前瞻与产业视野,给出了一个清晰定调:VLA时代没有结束,它正在持续变得更强!并且依然是通往物理世界智能的最强主航道。
郭彦东博士的这个定调,直接为这场阶段性的争议画上了句号。
01.
VLA时代没有终结,而是正在持续变得更强!世界模型不是颠覆者,而是加持者
针对“VLA是否过时”的行业争论,郭彦东博士从第一性原理出发重新定义了这一问题。他指出,任何能够在真实世界中执行任务的智能系统,都必须具备三项核心能力:对世界的感知、对逻辑的推理以及对行为的控制——这三个要素(视觉、语言、行动)是永远存在的,变化的只是它们的组织方式。
因此,所谓范式之争,本质上并非替代关系,而是组织方式的持续演进。世界模型、类脑模型等新技术,并不是对VLA的颠覆,而是对其能力的增强与补全。“VLA不会消失,它会被不断加持,变得越来越聪明,它是通往物理世界智能的最强主航道。”郭彦东博士在现场强调。
基于这一底层认知,智平方将VLA的发展划分为清晰的三阶段路径:从过去最初实现感知、理解与行动统一建模的端到端VLA,到现在融合世界模型实现“行动前预测”的增强型VLA,再到未来迈向类脑机制的全新阶段。

尤其是在最新阶段中,VLA不再只是一个单一模型,而是演进为具备分层结构的智能系统——类似人类大脑、小脑与脊髓的协同机制,从而实现更高效的推理、更快速的响应以及更稳定的控制。这一方向,也被郭彦东博士认定为未来具身智能最关键的技术演进路径。
在具体实践层面,郭彦东博士首次系统披露了智平方在具身大模型领域的连续突破,其自主研发的 AlphaBrain,致力于为通用智能机器人提供“最强大脑”。
早在2024年6月,智平方就推出了AlphaBrain的初期版本,这也是全球创业公司中首个VLA大模型,在模型规模仅为谷歌同类模型1/20的情况下,性能提升超过80%。2025年6月,智平方推出了快慢系统深度融合的新一代VLA架构,成为业内首个“异构输入+异步频率”的双系统VLA模型,性能直接超越国际标杆Pi0达30%。
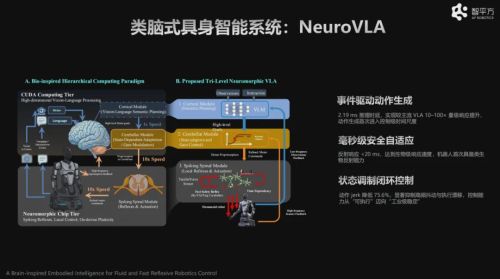
2025年11月,智平方发表融合世界模型的VLA具身大模型,实现“先预测、后执行”。本次大会,智平方正式对外披露了全球首个类脑架构VLA具身大模型(NeuroVLA),再次引领突破。
在最新的类脑VLA中,智平方通过引入生物启发的分层计算结构,首次提出将小脑和脊髓的部分融入操作当中,实现模型毫秒级自适应控制与接近生物反射速度的响应能力,使机器人首次具备类似“肌肉记忆”的持续进化能力。这一突破,标志着机器人从“执行指令的工具”,向“在任务中不断优化自身的智能体”迈出关键一步。
持续领先、代际碾压,智平方在短短三年内完成了从范式验证到体系化创新的跃迁,成为其模型能力的真实写照。

02.
AlphaBrain Platform:全球首个一站式、开箱即用的具身模型开源社区
如果说类脑VLA代表了未来方向,那么与之同步发布的AlphaBrain Platform,则体现了智平方推动行业整体跃迁的另一重战略布局。
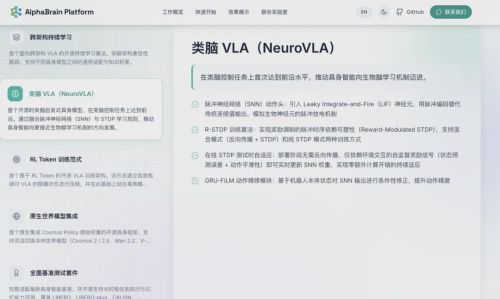
郭彦东博士在演讲中宣布,AlphaBrain Platform作为全球首个一站式、开箱即用的具身智能模型开源社区,已正式向全行业开放。与传统仅开放单一模型或代码的开源方式不同,AlphaBrain Platform直接打通了“数据—训练—模型—评测”的完整链路,“以全家桶式的贴心服务”,将原本只有少数团队具备的复杂系统能力,转化为整个行业可共享的公共能力。

开源地址:https://www.alphabrain-platform.com/
AlphaBrain Platform一次性开源了当前具身智能领域最前沿的三条技术路线:全球首个开源类脑VLA模型、全球首个基于RL Token的开源VLA训练架构、全球首个可插拔世界模型工具链。
以前,这些技术只存在于顶尖实验室和顶会论文里。现在,全部开放,任你取用。
03.
类脑模型:让机器人拥有"肌肉记忆"
类脑模型被公认为VLA(Vision-Language-Action)的未来方向,传统VLA模型"训练完成即固定",无法在部署后继续学习。智平方开源的NeuroVLA,首次在类脑控制任务上达到前沿水平。它引入脉冲神经网络动作头与R-STDP训练算法,支持部署阶段的在线自适应,使用前向传递方式,让机器人具有肌肉记忆能力。
这意味着机器人第一次从"执行指令的工具"转向"在任务中不断进化的主体"。它不只是完成任务,而是在过程中变得更熟练、更稳定。一个工人在流水线上重复同一个动作,第一天可能需要5秒,一个月后可能只需要3秒——这就是肌肉记忆。现在,机器人也有了。
04.
RL Token:用一张4090就能做强化学习
RL Token是"强化学习+VLA"的黄金组合,也是让大模型真正可落地的场景化利器。它将大模型的通用认知与强化学习的特定场景优化能力深度融合,让大模型从"纸上谈兵"的对话工具,真正转变为能在工厂、家庭、仓库等具体场景中完成实际物理任务的自主系统。
但长期以来,对VLA做强化学习面临着算力门槛高、容易灾难性遗忘等难题。所谓灾难性遗忘,就是模型学了新技能,把老技能忘了。
智平方率先在LIBERO环境上完成验证,提出信息瓶颈编码器与两阶段训练策略,使VLA主体在RL微调过程中完全冻结。所需训练参数从39亿降至约1.37亿,其中RL梯度更新仅涉及130万参数,仅需单张4090显卡即可进行强化学习后训练。
这个门槛的降低,对于高校实验室和小型团队而言,意义是革命性的。以前做强化学习需要数张A100,现在一张消费级显卡就够了。
05.
世界模型:让机器人学会"预演未来"
世界模型是当前最火的"想象力引擎",让机器人在行动前预演未来,做出更优决策。人类在做复杂决策时,会在脑海中模拟不同的可能性,这就是世界模型的本质。
然而,世界模型的研究长期停留在论文阶段,不同模型之间难以对比、难以集成。智平方首次实现世界模型的可插拔化。平台原生集成NVIDIA Cosmos Policy原始权重,同时支持Cosmos、Wan、V-JEPA三大世界模型Backbone一键切换,共享统一动作解码器。
这意味着机器人可以在行动前"预演"多种可能路径,选择最优解。开发者可以自由对比不同世界模型的表现,极大降低研究门槛。这一长期停留在论文中的能力,终于成为人人可用的工具。
06.
开源不是终点,好用才是
过去几年,具身智能领域不缺模型,也不缺论文。但一个尴尬的现实是:开源模型很多,真正"好用"的很少。
很多开源项目停留在"能跑通"的阶段。开发者想做真正的创新,往往要从数据处理开始,一路搭建训练流程、对接不同模型、手动完成评测验证。不同项目之间数据格式不统一、接口不兼容,大量时间消耗在重复的工程工作中。
AlphaBrain Platform改变的正是这一点。它不是简单开源一个模型,而是把"数据—训练—模型—评测"整条链路全部打通,从而在五个维度上构建起完整的技术壁垒。
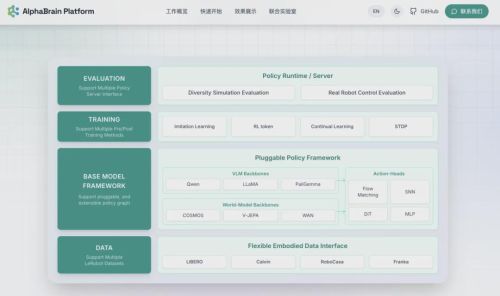
在技术深度上,平台集成了世界模型、类脑模型等最前沿的技术路线,开发者无需从零复现论文;在覆盖广度上,它同时支持RL、世界模型、传统VLA、类脑模型,是业内唯一覆盖所有主流技术方向的平台。更重要的是,不同架构与训练范式可以自由组合,跨领域的"化学反应"只需修改几行配置即可触发。评测层面同样如此,统一的数据格式、评估环境与测试标准,覆盖LIBERO、RoboCasa、CALVIN、BEHAVIOR-1K等8大主流Benchmark,一键完成评测,好模型不再靠"嘴强"。而在生态建设上,平台汇聚了全球顶尖机构的开源力量,横跨学术界与产业界,共同构建具身智能的开放生态。
如果说以前开源一个模型是给你一个工具,那AlphaBrain Platform直接给你的是一套"顶配全家桶"——最前沿的模型、最趁手的工具、最标准的评测,一次配齐,开箱即用。
Physical Intelligence(Pi)公司的Pi0模型开源,是业内单模型开源的标杆。但Pi做的是"单模型开源",智平方做的是"生态平台"。
AlphaBrain Platform不仅开源自己达到世界前沿水平的三个"全球首个"(类脑、RL+VLA、世界模型),更开放地集成了其他头部模型,让开发者可以在同一平台上自由选择、组合、对比。
平台统一了数据格式和评测基准,覆盖8大主流标准。这意味着,在这个平台上发布的模型,都需要在同一套评测体系下接受检验,模型之间的对比终于有了公平的基础。
与Pi等公司的单模型开源相比,AlphaBrain Platform更像一套完整的"全栈工具链"。前者给你一个可以用的模型,后者给你一整套可以创新的环境。对于整个产业而言,后者的价值更大,它让资源有限的团队不必再重复搭建底座,可以直接把精力投入到真正有价值的算法创新上。