具身智能训练的四种数据来源:遥操作是否足够?
针对同一个机器人模型,如果通过使用另一批训练数据进行训练,那么其行为表现可能从稳定地抓取杯子,转变为稳定地将杯子推翻。
这一现象在具身智能领域并不值得惊讶。一个模型的最终表现,虽然根本上受其内在架构、参数规模与训练方法所限定,但同时高度依赖于所使用数据的质量——即数据是否纯净、标注是否与任务对齐,以及是否全面覆盖了真实场景中的任务分布。在工程实践中,常有“垃圾进,垃圾出”的告诫,其含义在于,如果输入模型的是包含错误标注、缺失标注、质量低下或与目标机器人特性不匹配的数据,那么它所输出的行为指令便难以保持稳定与可靠。
问题在于,获取用于训练机器人的高质量具身数据成本十分高昂。以一个简单的机械臂将杯子推至指定位置的任务为例,其过程在视频中或许仅持续数秒;然而,在为模型准备训练数据时,则需要同步记录相机捕捉的环境画面、机械臂各关节的运动状态、夹爪的开合动作以及与物体的接触结果,最好还能包含失败案例的样本。当任务进展到与物体发生真实物理接触的瞬间,环境还会引入打滑、视觉遮挡、传感器标定误差以及物体姿态的动态变化等一系列复杂细节。由此,一个关键问题便浮现出来:在模型的训练过程中,哪些基础能力可以借助成本较低的模拟数据或大规模网络数据进行预训练,而哪些高阶或精细的操作能力,则必须依赖于成本高昂、采集困难的真实世界数据进行专门校准与学习。
机器人数据最可靠,也最贵
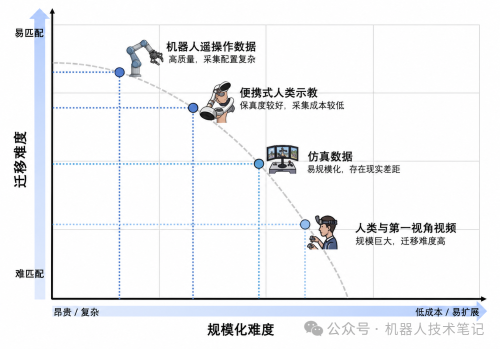
在各类用于机器人学习的数据中,可靠性最高的一类通常被认为是遥操作采集的数据。这类数据的生成过程如下:操作人员借助手柄、示教器、VR设备或其他人机接口来直接操纵机器人,与此同时,系统会同步采集并记录下相机画面、各关节状态、末端执行器的位姿、夹爪的开合动作、力觉或触觉信号,以及最终执行的运动指令。其价值体现得非常直接:每一帧感知数据之后都对应着真实机器人能够执行的具体动作,而这些动作指令发出后,外部物理世界所发生的变化也被完整地记录了下来。
这对于视觉-语言-动作模型(VLA)以及世界动作模型(WAM)都具有关键意义。前者需要学习从观察与语言指令到动作之间的映射关系,后者则还需要进一步预测执行动作之后所产生的未来状态变化。如果没有这类严格配对的数据作为支撑,模型虽然能够理解画面当中所呈现的内容,但却无法得知机器人具体应当执行怎样的动作指令。
RT-1、Open X-Embodiment 以及 DROID 均可被视为这一技术路线上的代表性工作。其中,Open X-Embodiment 将来自多个机器人平台的数据进行了统一整合,根据论文中的统计,该数据集涵盖了超过 100 万条轨迹,涉及 22 种不同的机器人类型;DROID 则聚焦于真实家庭及办公环境中的机械臂操作任务,相关统计显示其包含 7.6 万条轨迹数据,覆盖 564 个不同的操作环境。[2][3][4]
相应的代价也同样十分明显:成本高昂、实施周期较长,且高度依赖硬件条件。高质量的遥操作数据采集工作需要配备机器人本体、相机标定流程、采集软件系统、安全机制以及失败样本管理等一系列基础设施。一旦更换机器人、夹爪或应用场景,所采集的数据往往需要经历重新校准的过程。这类数据虽然适合用于解决动作落地的实际问题,却很难仅凭此类数据来独立完成开放世界中的泛化任务。
RT-1、Open X-Embodiment以及DROID均可被视作这条技术路线上的代表性工作。其中,Open X-Embodiment将来自多个机器人平台的数据进行了统一整合,相关统计显示,该数据集涵盖了超过100万条轨迹,涉及22种不同的机器人类型;DROID则聚焦于真实家庭及办公环境中的机械臂操作任务,其数据规模包含7.6万条轨迹,覆盖了564个不同的操作环境。[2][3][4]
然而,遥操作数据采集方案所伴随的代价也十分显著:成本高昂、实施周期较长,并且高度依赖于硬件条件。一次高质量的数据采集工作需要配备机器人本体、相机标定流程、专用的采集软件系统、安全防护机制以及针对失败样本的管理方案等一系列基础设施。这意味着,一旦更换机器人本体、末端夹爪或应用场景,之前所采集的数据往往就需要经历重新校准的过程。尽管这类数据非常适合用于解决动作执行层面的实际问题,但若仅仅依赖它,模型却很难独立完成面向开放世界的泛化任务。
第二类数据,是便携式人类示教方法,其代表性系统为通用操作接口(Universal Manipulation Interface, UMI)。[5] 与需要使用者持续进行远程控制的遥操作不同,该方法允许使用者手持一个轻量化的夹爪装置,在真实的生活场景中演示目标任务。系统随后借助摄像头、位姿跟踪技术,对使用者的手部动作以及夹爪的开合状态进行同步记录,再经过一系列后处理步骤,将记录下来的人类操作轨迹,转换为可供机器人学习的标准化示教数据。
该方法旨在解决一个实际存在的矛盾:机器人遥操作采集的数据虽然质量很高,但其采集场景被限定在特定的机器人和实验室环境内;虽然普通的人类视频数据覆盖的场景更为广泛,但却缺乏机器人动作的对应标签。便携式示教方法恰好处于这两者之间,它相较于遥操作更为廉价和灵活,同时相比于普通视频又增加了对操作意图和动作的约束。例如,若要教会机器人打开抽屉,若使用遥操作方式,则需要搬运机器人本体、调整相机位置并进行坐标系标定;而借助便携式示教,用户则可以直接手持采集设备在不同的房间内进行演示。
其主要风险在于,人类手部与机器人夹爪之间存在本质差异。由于人类手腕具有较高的柔顺性,且手指自由度丰富,而机器人夹爪通常仅具备开合动作。因此,在进行轨迹重定向时,会面临可达性范围、夹爪几何形状、力控制精度以及碰撞空间等方面的显著差异。所以,这种方法适合用来补充真实场景的数据并增加任务多样性,但仍然需要依赖机器人数据来进行落地的校准工作。
仿真数据:成本虽低,其局限性同样十分清晰
第三类数据是仿真数据。这类数据的吸引力十分明显:具有成本低廉、参数可控以及易于规模化扩展的优势。在真实物理世界当中,如果杯子不慎被推倒,那么需要人工将其扶起;而在仿真环境里,则可以通过一键操作便将场景恢复到初始状态。真实相机通常无法观察到被遮挡的背面信息;仿真环境则可以直接提供包括深度图、语义分割、6D位姿、碰撞边界以及多视角状态在内的丰富数据。对于世界动作模型(WAM)而言,这类监督信号显得尤为宝贵,因为该模型所要学习的目标并不仅仅是预测下一帧的画面内容,更在于理解三维物理世界如何随机器人的动作而发生动态变化。
MimicGen、ManiSkill2、RoboCasa、RoboTwin 均可被视为这条技术路线上的代表性工作。其中,MimicGen 通过借助少量人类示教数据,以程序化的方式对任务轨迹进行扩增;ManiSkill2 则提供了一套可泛化的操作技能 benchmark,其中包含了深度图、点云以及本体状态等多模态信息。[6][7]
仿真尤其适合用于训练空间理解能力以及接触前的运动关系规划。在机械臂执行伸展动作之前,模型需要识别物体所处的位置、桌面所处的位置,并据此判断从哪个方向进行接近更为合理。而在真实数据当中,这些信息往往会被遮挡现象与传感器噪声交织在一起;仿真环境则可以将这些答案完整地暴露给模型。
真正的边界也十分清晰,那便是仿真到真实世界的迁移鸿沟(sim-to-real gap)。视觉外观上的差异仅仅是表面现象;真正的难点在于物理接触与交互的模拟。诸如软体物体的变形、线缆的拖曳、液体的晃动以及透明物体表面的反光等复杂现象,在仿真环境中都存在显著的模拟难度。因此,仿真环境更适合用于开展大规模的预训练以及提供空间关系上的监督信号,但并不适合作为模型能够在真实世界中稳定部署的充分条件或保证。
人类视频与第一视角视频:规模最为庞大,在动作对齐方面所面临的难度也最高
第四类数据是互联网视频、人类活动视频以及第一视角视频。这类数据所具备的优势主要体现在规模方面。Ego4D 涵盖了数千小时的日常活动视频;HowTo100M 以及 Kinetics 等网络视频数据集则覆盖了大量的动作类型与语义场景。[1][8] 对于 WAM 而言,这些视频所提供的是关于世界如何运转的基础常识。
当杯子被推向桌边时便会掉落,当抽屉被拉开后其内部空间就会显露,当手靠近物体时通常会产生接触。这类常识并不一定需要依赖机器人动作标签来进行学习。模型能够借助海量视频数据,学习到物体连续性、材质变化、遮挡恢复以及事件发生的先后顺序。
这也是世界动作模型相较于传统视觉-语言-动作模型(VLA)更具发展潜力的地方。传统的VLA通常依赖于观察与动作严格配对的数据进行学习;而世界动作模型的核心任务是对未来状态进行建模,因此其具备了吸收一部分不含机器人动作标签的视频数据的可能性,借此学习视觉层面的物理规律,再与包含机器人动作的数据进行混合训练。
然而,这类数据在本质上离实现机器人闭环控制最为遥远。这些数据虽然包含了人类手部动作的视觉记录,却完全缺失了直接驱动机器人关节所必需的电机控制指令;这些画面虽然捕捉到了物理交互的外在形态,但通常未能同步记录下接触力的大小与方向、夹爪的精确状态以及各关节的实时位姿。因此,这类数据更适用于为模型提供关于物理世界如何运作的基础认知与常识性先验知识,而要将其转化为可直接驱动机器人的执行策略,其间还需跨越一道关键的动作接口转换环节。
对于同一个机器人模型,使用另一批训练数据进行训练后,其行为表现可能从稳定地抓取杯子,转变为稳定地将杯子推翻。这一现象在具身智能领域并不令人惊讶。模型的最终行为虽根本上取决于其架构、参数规模与训练方法,但也高度依赖于训练数据的质量——即数据是否纯净、标注是否与任务对齐,以及是否全面覆盖了真实场景中的任务分布。工程实践中常有“垃圾进,垃圾出”的告诫,意指若输入模型的是包含错误标注、缺失信息、质量低下或与目标机器人特性不匹配的数据,其输出的行为指令便难以保持稳定可靠。
问题在于,获取用于机器人训练的高质量具身数据成本高昂。以一个简单的机械臂将杯子推至指定位置的任务为例,其过程在视频中可能仅持续数秒。然而,在准备训练数据时,需同步记录相机捕捉的环境画面、机械臂各关节运动状态、夹爪开合动作以及与物体的接触结果,并最好包含失败案例的样本。当任务进展到与物体发生真实物理接触时,环境还会引入打滑、视觉遮挡、传感器标定误差及物体姿态动态变化等一系列复杂细节。由此产生一个关键问题:在模型训练中,哪些基础能力可以借助成本较低的模拟数据或大规模网络数据进行预训练,而哪些高阶或精细的操作能力,则必须依赖于成本高昂、采集困难的真实世界数据进行专门校准与学习。
在各类用于机器人学习的数据中,可靠性最高的一类通常被认为是遥操作采集的数据。其生成过程如下:操作人员借助手柄、示教器、VR设备或其他人机接口直接操纵机器人,同时系统同步采集并记录相机画面、各关节状态、末端执行器位姿、夹爪开合动作、力觉或触觉信号,以及最终执行的运动指令。其价值体现直接:每一帧感知数据后都对应着真实机器人能够执行的具体动作,而这些动作指令发出后,外部物理世界所发生的变化也被完整记录。[2]
这对于视觉-语言-动作模型以及世界动作模型都具有关键意义。前者需学习从观察与语言指令到动作的映射关系,后者还需进一步预测执行动作之后所产生的未来状态变化。如果没有这类严格配对的数据作为支撑,模型虽能理解画面内容,却无法得知机器人具体应当执行怎样的动作指令。[3]
相应的代价也十分明显:成本高昂、实施周期较长,且高度依赖硬件条件。一次高质量的遥操作数据采集工作需配备机器人本体、相机标定流程、专用采集软件系统、安全防护机制以及针对失败样本的管理方案等一系列基础设施。这意味着,一旦更换机器人本体、末端夹爪或应用场景,之前所采集的数据往往就需要经历重新校准的过程。这类数据虽适合解决动作执行层面的实际问题,但若仅仅依赖它,模型却很难独立完成面向开放世界的泛化任务。[4]
第二类数据是便携式人类示教方法,其代表性系统为通用操作接口。与需要使用者持续进行远程控制的遥操作不同,该方法允许使用者手持一个轻量化的夹爪装置,在真实生活场景中演示目标任务。系统随后借助摄像头与位姿跟踪技术,对使用者的手部动作以及夹爪的开合状态进行同步记录,再经过一系列后处理步骤,将记录下来的人类操作轨迹转换为可供机器人学习的标准化示教数据。[5]
该方法旨在解决一个实际存在的矛盾:机器人遥操作采集的数据质量很高,但采集场景被限定在特定机器人和实验室环境内;普通人类视频数据覆盖的场景更为广泛,但却缺乏机器人动作的对应标签。便携式示教方法恰好处于这两者之间,它相较于遥操作更为廉价和灵活,相比于普通视频又增加了对操作意图和动作的约束。例如,若要教会机器人打开抽屉,使用遥操作方式则需要搬运机器人本体、调整相机位置并进行坐标系标定;而借助便携式示教,用户则可以直接手持采集设备在不同房间内进行演示。
其主要风险在于,人类手部与机器人夹爪之间存在本质差异。由于人类手腕具有较高的柔顺性且手指自由度丰富,而机器人夹爪通常仅具备开合动作,因此在进行轨迹重定向时,会面临可达性范围、夹爪几何形状、力控制精度以及碰撞空间等方面的显著差异。所以,这种方法适合用来补充真实场景的数据并增加任务多样性,但仍然需要依赖机器人数据来进行落地的校准工作。
第三类数据是仿真数据。这类数据的吸引力十分明显:具有成本低廉、参数可控以及易于规模化扩展的优势。在真实物理世界中,如果杯子不慎被推倒,需要人工将其扶起;而在仿真环境中,则可以通过一键操作便将场景恢复到初始状态。真实相机通常无法观察到被遮挡的背面信息;仿真环境则可以直接提供包括深度图、语义分割、6D位姿、碰撞边界以及多视角状态在内的丰富数据。对于世界动作模型而言,这类监督信号显得尤为宝贵,因为该模型所要学习的目标并不仅仅是预测下一帧的画面内容,更在于理解三维物理世界如何随机器人的动作而发生动态变化。[6]
真正的边界也十分清晰,那便是仿真到真实世界的迁移鸿沟。视觉外观上的差异仅仅是表面现象;真正的难点在于物理接触与交互的模拟,诸如软体物体的变形、线缆的拖曳、液体的晃动以及透明物体表面的反光等复杂现象,在仿真环境中都存在显著的模拟难度。因此,仿真环境更适合用于开展大规模的预训练以及提供空间关系上的监督信号,但并不适合作为模型能够在真实世界中稳定部署的充分条件或保证。[7]

第四类数据是互联网视频、人类活动视频以及第一视角视频。这类数据所具备的优势主要体现在规模方面。例如,Ego4D涵盖数千小时的日常活动视频;HowTo100M以及Kinetics等网络视频数据集则覆盖了大量的动作类型与语义场景。[1][8] 对于世界动作模型而言,这些视频所提供的是关于世界如何运转的基础常识。
当杯子被推向桌边时便会掉落,当抽屉被拉开后其内部空间就会显露,当手靠近物体时通常会产生接触。这类常识并不一定需要依赖机器人动作标签来进行学习。模型能够借助海量视频数据,学习到物体连续性、材质变化、遮挡恢复以及事件发生的先后顺序。
这也是世界动作模型相较于传统视觉-语言-动作模型更具发展潜力的地方。传统的视觉-语言-动作模型通常依赖于观察与动作严格配对的数据进行学习;而世界动作模型的核心任务是对未来状态进行建模,因此其具备了吸收一部分不含机器人动作标签的视频数据的可能性,借此学习视觉层面的物理规律,再与包含机器人动作的数据进行混合训练。
然而,这类数据在本质上离实现机器人闭环控制最为遥远。这些数据虽然包含了人类手部动作的视觉记录,却完全缺失了直接驱动机器人关节所必需的电机控制指令;这些画面虽然捕捉到了物理交互的外在形态,但通常未能同步记录下接触力的大小与方向、夹爪的精确状态以及各关节的实时位姿。因此,这类数据更适用于为模型提供关于物理世界如何运作的基础认知与常识性先验知识,而要将其转化为可直接驱动机器人的执行策略,其间还需跨越一道关键的动作接口转换环节。
该图表的核心价值在于,它为评估机器人学习数据提供了一个清晰的双维度分析框架:即数据获取的规模化难度与在机器人任务上的迁移难度。通过将数据类型置于这一坐标系中进行审视,我们可以系统地辨识其内在特性。机器人遥操作数据靠近高质量、低迁移难度的一端,但其采集过程复杂且成本高昂;人类视频与第一视角数据则靠近低成本、大规模的一端,然而其信息与机器人动作空间存在显著距离;仿真数据易于规模化生成,但必须额外处理其与现实世界的差距;便携式人类示教数据则位于两者之间,作为一种折中方案。深刻理解这一图表所揭示的分布规律,便基本把握了具身智能领域在数据选择上的核心权衡逻辑。
预训练管见识,后训练管上手
预训练本质上是为模型提供关于现实世界运作方式的先验知识。该阶段的数据处理需具备大规模与广泛覆盖的特征,其来源可以涵盖机器人轨迹数据、仿真环境生成的视频、人类第一视角拍摄的视频、来自互联网的视频片段,以及各类多模态数据。在这个阶段,训练数据并非要求每一条都包含精确的机器人动作标签,其核心目标在于使模型学习并理解物体运动的基本规律、物体间接触后产生的后果,以及哪些物理变化是合理且符合常识的。因此,该阶段旨在回答世界动态变化的基本规律。
后训练更接近于将这种关于世界运作的经验,接入到一台具体的机器人硬件上。它所依赖的数据需要更加纯净、与目标任务高度对齐,并且更加贴近最终的部署环境。例如,这些数据应当包括从目标机器人本身采集而得的遥操作轨迹、任务失败时的样本、用于行为纠正的数据、特定的任务偏好设定,以及在实际采用的控制频率下所记录的“观察-动作-结果”三元组。尽管此阶段所需的数据规模可以相对较小,但其质量要求却极高,因为它直接决定了机器人能否将所习得的预测能力稳定转化为实际的动作执行。
在工程实践中,可以将其理解为两本性质不同的账目。预训练这本账更侧重于数据的广泛覆盖,倾向于让模型接触尽可能多的物体、场景、视角与事件类型;而后训练这本账则更关注于动作的可执行性,宁愿数据规模有所收缩,也必须确保动作标签的准确性、时间戳的同步性、传感器状态的完整性以及与目标机器人硬件的高度一致性。前者旨在解决模型“见识”不足的问题,后者则致力于解决策略“上手”执行的稳定性。具身智能领域中“垃圾进,垃圾出”的原则,在后训练这一阶段体现得尤为显著。
未来的数据配方,大概率是混合的
仅仅从模型发布这一角度来观察,具身智能这一领域很容易被理解为一个纯粹的大模型问题。然而,当转向训练数据的视角进行审视时,它则更接近于一个复杂的系统工程问题。一个能够实际部署的解决方案,通常不会仅仅依赖于单一类型的数据来源:机器人遥操作数据负责向模型传达哪些动作是真实可执行的;便携式人类示教方法则为模型引入了现实世界中的任务多样性;仿真环境提供了成本低廉、参数可控且包含空间真值信息的训练场所;而人类视频与第一视角视频则用以补充开放世界中的常识性知识。
问题的核心并不在于数据是否被混合在一起,而是在于这些不同类型的数据应当以何种比例与方式进行混合。如果在训练所使用的大规模数据集当中,来自真实机器人采集的轨迹数据所占比例过低,那么模型或许能够对视频内容进行预测,但在将预测出的动作转化为可供机器人硬件执行的底层控制指令时,可能会面临困难。反之,如果数据集完全由机器人轨迹构成,那么模型虽然在实验室环境的常规任务上能够保持稳定的表现,但却可能因此缺乏对于那些发生概率较低、形态多样的长尾场景的经验积累。另外,如果来自仿真环境生成的模拟数据权重设置得过高,则有可能在与真实物体发生物理接触时,暴露出仿真环境与真实世界在摩擦系数、物体柔顺性以及传感器噪声等方面存在的显著差异。
VLA与WAM这类技术路线的意义,在于将这些异构数据整合至同一套训练框架当中。该框架既能够借助包含动作标签的三元组,也就是当前观察、动作指令与下一状态,来学习可控的物理状态变化;也可以借助不带动作标签的视频数据,学习更为宽泛的视觉物理规律。其技术路径并非直接将视频转化为机器人控制指令,而是首先赋予模型对世界状态进行预测的能力,随后再通过真实动作数据将这种能力接入执行环节。
来源:遥操作就够了吗?拆解具身智能训练的四种数据来源 | 具身研习社