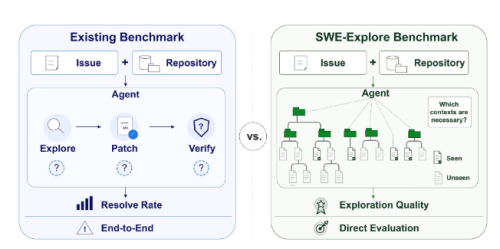
一个由上海交通大学参与的国际研究团队今日正式推出全新基准测试工具 SWE-Explore,该工具通过将代码搜索与实际修复阶段进行解耦评估,首次量化揭示了当前 AI 编码智能体在“行级精度”上的重大技术短板。这一研究打破了以往仅依赖“最终修复率”的单一评估模式,为智能体上游搜索质量的直接衡量提供了全新标准,正推动 AI 软件工程评测向深水区演进。
传统的 SWE-bench 等基准测试因仅关注端到端的结果,往往掩盖了智能体在代码阅读与理解阶段的真实缺陷。为此,研究团队基于 GPT-5.4、Gemini3Pro、Claude Sonnet4.6及 Kimi K2.6等主流大模型的成功运行轨迹,提取出多条独立解路径交汇的共识代码段作为参考值,构建了包含10种编程语言、203个开源项目的848个缺陷任务数据集。

评测结果显示,尽管 Claude Code、OpenHands 等通用编码智能体在“文件级”定位上表现卓越,但在聚焦到具体的“代码行”时,其核心区域覆盖率骤降至14% 到19% 之间。消融实验进一步证实了“最小上下文阈值”效应的存在:当关键核心区域的可见比例低于50% 时,模型修复基本宣告失败;而一旦跨越50% 至75% 的阈值,修复成功率才会出现断崖式回升。
这一研究成果表明,当前 AI 智能体的瓶颈并非完全在于补丁编写能力,而在于对关键上下文的精准过滤与捕捉。在当前行业内诸如项目经理拒绝半数自动化采纳方案的现实背景下,SWE-Explore 提出的“少过滤、多阅读”技术导向,不仅为下一代专门化代码定位系统(如 CoSIL 等)的架构优化指明了方向,也将加速自动化软件工程从“暴力生成”向“精准检索”的范式转变。