出品:具身释界
很多时候,我们会觉得机器人操作物体,最重要的是“看得准”。
比如机器人要抓一个杯子,只要摄像头看到杯子在哪里,机械臂移动过去,然后夹起来,任务似乎就完成了。
但如果任务稍微复杂一点,事情就没有这么简单了。
想象一下,人类在擦桌子、削黄瓜、切菜、插 USB、拧瓶盖的时候,其实并不是只靠眼睛。很多关键细节,都是靠“手感”完成的。
比如擦桌子的时候,我们会感觉抹布有没有贴住桌面;削皮的时候,会感觉刀有没有真正贴住食材表面;插 USB 的时候,会通过手上的阻力判断有没有对准;抓葡萄、蓝莓这类易碎物体的时候,也会根据手指的压力判断有没有夹太紧。
这些信息,光靠视觉很难判断。
因为摄像头只能看到外部画面,但接触力、摩擦、滑动、卡住、对齐、松动这些变化,很多时候都发生在物体和手指接触的地方。特别是机器人自己的夹爪经常会挡住物体,视觉看到的画面并不完整。
这篇论文 OmniVTA: Visuo-Tactile World Modeling for Contact-Rich Robotic Manipulation 关注的正是这个问题:
机器人能不能不只是“看到物体在哪里”,而是像人一样,提前预测接下来会发生什么接触,并且在接触出问题时快速修正动作?
换句话说,这篇论文想让机器人真正学会“摸着操作”。
一、为什么接触密集型操作这么难?
在机器人操作任务里,有一类任务叫 contact-rich manipulation,也就是“接触密集型操作”。
这类任务的特点是,机器人和物体之间不是简单地碰一下,而是需要持续、稳定、精细地接触。
比如:
擦拭,需要保持合适的压力,不能太轻,也不能太重。
削皮,需要刀具持续贴住食材表面,同时沿着表面滑动。
切割,需要逐渐增加向下的力,并判断什么时候切断。
装配,需要感知插入过程中的阻力和对齐状态。
手内调整,需要判断物体有没有滑动、有没有转到目标姿态。
这些任务的难点不只是“空间位置”,而是“接触状态”。
机器人需要知道:
现在有没有碰到?
碰得够不够?
是不是太用力了?
有没有打滑?
有没有偏离目标接触位置?
接触状态接下来会怎么变化?
如果只靠视觉,这些问题很难回答。
因为视觉看到的是物体表面,而触觉感受到的是物理交互本身。对于接触密集型任务来说,触觉不是一个可有可无的补充,而是决定任务能不能稳定完成的关键。
过去也有一些工作把触觉加入机器人策略中,但很多方法只是把触觉当作额外输入。也就是说,模型看到图像,再读到触觉信号,然后直接输出动作。
这当然有帮助,但还不够。
因为真正稳定的操作,不只是“感知当前触觉”,还需要“预测未来触觉”,并且根据真实触觉和预测触觉之间的差异,快速调整动作。
这就是 OmniVTA 的核心出发点。
二、这篇论文做了什么?
简单来说,这篇论文主要做了两件事。
第一,作者构建了一个大规模视触觉操作数据集,叫 OmniViTac。
这个数据集包含 21,879 条操作轨迹,覆盖 86 个任务和 100 多个物体。数据里不仅有视觉信息,还有触觉信息和机器人动作信息,并且这些信息在时间上做了同步。
更重要的是,作者没有简单按照“任务名称”来组织数据,而是按照物理接触模式,把任务分成六大类:
擦拭 Wiping
剥皮 Peeling
切割 Cutting
抓取 Grasping
装配 Assembly
手内调整 Adjustment
这六类任务代表了不同的接触机制,比如法向力、剪切力、摩擦、滑动、对齐、插入、扭转等。
第二,作者提出了一个机器人操作框架,叫 OmniVTA。
它的核心不是简单地“视觉 + 触觉 → 动作”,而是:
先根据当前视觉和触觉,预测未来短时间内的接触状态;
再根据预测的触觉状态生成动作;
执行过程中不断比较“预测触觉”和“真实触觉”;
如果发现真实接触状态偏离预期,就用高频触觉反馈快速修正动作。
可以把它理解为一个会“提前想象手感”、又会“根据手感临时调整动作”的机器人策略。
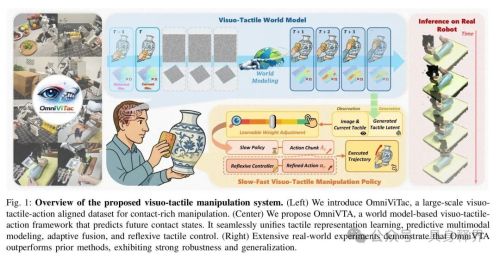
三、先看总览图:OmniVTA 的整体思路

Figure 1 是整篇论文的总览图,可以从左到右来看。
左边是 OmniViTac 数据集。它包含大量真实接触操作数据,里面有图像、触觉和动作轨迹。
中间是 OmniVTA 的方法框架。这里最关键的是一个 Visuo-Tactile World Model,也就是视触觉世界模型。它会根据当前和历史观察,预测未来的接触状态。
右边是机器人真实执行实验。论文展示了模型在真实机器人上的效果,说明这种“预测触觉 + 高频修正”的方式可以提升接触密集型任务的稳定性。
这张图里最值得注意的是中间部分:
模型不是直接从当前图像输出动作,而是会先生成未来的触觉 latent,也就是未来接触状态的压缩表示。然后策略会利用这些预测结果来生成动作。
同时,机器人执行动作时还有一个 reflexive controller,可以理解成“触觉反射控制器”。它会不断检查当前真实触觉和预测触觉是否一致。如果不一致,就给动作加一个修正量。
这和人类操作物体很像。
比如我们擦桌子时,如果手突然感觉抹布离开桌面了,就会下意识往下压一点;如果感觉太用力了,就会稍微放轻一点。这个修正不是慢慢思考出来的,而是快速的触觉反馈。
OmniVTA 也在模仿这种机制。
四、OmniViTac:为什么作者要先做一个大数据集?

Figure 2 展示了 OmniViTac 数据集的整体设计。
这张图可以分成几个部分来看。
左边是数据采集平台。论文使用了两种采集方式:一种是真实机器人 xArm,另一种是 TacUMI 手持式采集设备。两者使用类似的末端夹爪和触觉传感器,这样可以减少不同采集方式之间的差异。
中间是六类视触觉操作模式,包括擦拭、剥皮、切割、抓取、装配和调整。
右上角是数据规模对比。OmniViTac 有 21,879 条轨迹,在视触觉操作数据集里规模比较大。
右下角是数据处理流程,包括时间戳对齐、可视化检查和人工验证。因为触觉信号频率比视觉高,如果不同模态之间时间对不齐,模型学到的就可能是错误的对应关系。比如图像里机器人还没碰到物体,但触觉里已经出现接触信号,这样训练出来的模型就会混乱。
所以这篇论文很强调“对齐”的重要性。
这也很好理解。触觉变化通常发生得很快,尤其是滑动、接触丢失、突然卡住这种情况。如果数据同步不准,模型就很难学到真正的接触动态。
五、六类接触任务:不是按名字分类,而是按物理机制分类

Figure 3 展示了数据集里的六类任务,每个任务都配有第三人称视角、末端执行器轨迹和对应的触觉图。
这张图很适合用来解释为什么触觉对机器人重要。
Assembly:装配
装配任务看起来像是“把一个东西插进去”,但真正难的是对齐和接触判断。
比如插 USB 或插接头时,视觉只能告诉机器人大概位置,但最后几毫米是否对齐,往往要靠触觉判断。如果插入时感觉到异常阻力,说明可能偏了;如果阻力变化变得稳定,可能说明已经进入正确位置。
Cutting:切割
切割任务主要依赖法向力,也就是向下压的力。
切黄瓜、香蕉、辣椒时,机器人需要知道有没有真正切进去,以及什么时候切断。如果只看图像,可能很难判断刀刃内部发生了什么。但触觉可以感受到阻力变化。切断的瞬间,力的变化会很明显。
Adjustment:手内调整
手内调整涉及滑动、旋转和重新定位。
比如夹住一个物体后,让它在夹爪中转到某个角度。这个过程中,触觉能帮助机器人判断物体有没有滑动、滑动方向是什么、是否已经到达稳定姿态。
Peeling:剥皮
剥皮需要持续保持工具和物体表面的接触。
如果刀离开表面,就剥不到皮;如果压得太深,又可能切到里面。这是一个非常典型的“视觉不够,必须靠触觉”的任务。
Wiping:擦拭
擦拭任务需要控制压力和摩擦。
太轻,擦不干净;太重,可能卡住或者损坏传感器。机器人必须持续感知接触是否稳定。
Grasping:抓取
抓取听起来很基础,但触觉依然很重要。
尤其是透明物体、易碎水果、形状复杂的物体,视觉判断可能不可靠。触觉可以告诉机器人是否真的夹住了、是否夹得太紧、有没有滑落风险。
这六类任务覆盖了接触密集型操作中很典型的物理过程。作者这样分类的好处是,模型不只是学“怎么擦一个花瓶”或者“怎么切一根黄瓜”,而是学不同接触模式背后的物理规律。
六、数据分析:触觉信号真的有结构吗?

Figure 4 是数据集分析图,里面包含接触面积分布、力强度分布、任务分布、有效接触比例和触觉 latent 的 t-SNE 可视化。
这张图想说明一个关键问题:
OmniViTac 里的触觉信号不是杂乱无章的,而是和不同任务的物理接触模式高度相关。
比如装配、抓取、手内调整这类任务,通常接触面积比较小,更依赖局部、精细的触觉反馈。它们往往只需要指尖某个区域感受到接触变化。
而擦拭、剥皮、切割这类任务,接触面积更大,通常需要传感器表面更大范围参与接触。特别是擦拭和剥皮,会出现持续的摩擦和剪切力。
图里的 t-SNE 可视化也很有意思。不同任务的触觉特征在 latent space 里形成了比较清晰的聚类。擦拭和剥皮因为都涉及连续摩擦,所以分布比较接近;装配因为更依赖局部几何接触,所以形成了更独立的区域;抓取则比较分散,因为抓取本身包含很多不同物体和不同力模式。
这说明触觉信号确实携带了丰富的任务信息,而且这种信息和物理接触机制有关。
所以这篇论文不是简单地说“加触觉会更好”,而是进一步证明:触觉本身有结构,可以被建模,可以被预测,也可以用于控制。
七、OmniVTA 的核心:慢速规划 + 快速反射

Figure 5 展示了 OmniVTA 的整体系统结构。
这个系统可以理解成两个层次:
上层是 Slow Policy,频率较低,负责规划一段动作。
下层是 Fast Policy,频率更高,负责根据实时触觉反馈修正动作。
这和人类动作控制很像。
比如我们削黄瓜的时候,大脑可能决定“沿着黄瓜表面往前削”。这是一个较慢的计划。但在真正削的过程中,手会根据刀和黄瓜之间的接触不断微调角度和力度。这个调整非常快,并不需要每次都重新做完整规划。
OmniVTA 也是这样。
Slow Policy 主要包括两个部分:
第一个是 Visuo-Tactile World Model,用来预测未来触觉状态。
第二个是 Adaptive Visuo-Tactile Fusion Policy,用来融合视觉、触觉和机器人状态,并生成 action chunk。
Fast Policy 则是 Reflexive Latent Tactile Controller,简称 RLTC。它以 60Hz 的频率运行,根据当前真实触觉和预测触觉之间的差异输出修正动作。
最终执行的动作不是单纯来自上层规划,也不是单纯来自下层修正,而是两者的组合:
慢速策略给出主要动作方向;
快速控制器根据触觉反馈进行细粒度补偿。
这种设计特别适合接触密集型任务,因为接触变化往往很快。如果模型只依赖低频规划,等它发现接触已经偏了,可能已经来不及了。
八、第一步:TactileVAE,把复杂触觉压缩成可用表示

触觉传感器输出的信息通常很复杂。
以光学触觉传感器为例,它可以记录接触引起的表面形变。原始触觉图像分辨率可能比较高,而且频率也比视觉更高。如果直接把这些高维触觉数据输入策略模型,计算开销会很大,也不利于模型学习稳定的表示。
所以论文提出了 TactileVAE,用来把触觉信号压缩成低维 latent。
可以简单理解为:
原始触觉信号是一张很复杂的“手感地图”;
TactileVAE 把这张地图压缩成一个更小、更抽象的表示;
后面的 world model 和 policy 就不需要处理原始触觉图,而是处理这个压缩后的触觉表示。
Figure 6 中,TactileVAE 包含一个时空编码器和一个隐式解码器。
编码器负责把一段触觉变化压缩成 latent feature。
解码器负责根据 latent 和空间坐标,重建连续的触觉形变场。
这里比较有意思的是,作者没有把触觉当成普通图片来重建,而是把它看作一个连续的表面形变场。因为触觉传感器感受到的,本质上是接触导致的弹性表面形变,而不是普通 RGB 图像。
这样设计的好处是,模型能更自然地学习局部接触和连续形变。
九、第二步:Visuo-Tactile World Model,预测未来接触状态

这篇论文最核心的地方,是它把 world model 引入了视触觉操作。
这里的 world model 不是简单预测未来图像,而是重点预测未来的触觉状态。
为什么要预测未来触觉?
因为机器人在接触密集型操作中,真正关心的是:
如果我继续这样动,接下来会不会接触?
接触会不会变强?
会不会打滑?
是不是快要失去接触?
是不是会产生过大的力?
比如擦拭的时候,机器人当前可能还贴着物体,但如果继续沿着当前方向移动,下一秒可能会滑出表面。模型如果能提前预测未来触觉变化,就可以提前调整动作,而不是等失败发生后再补救。
论文里的 Visuo-Tactile World Model 采用双流结构。
一条流建模视觉,一条流建模触觉。视觉 latent 和触觉 latent 分别进入对应的时空扩散 Transformer,但它们共享一个多模态条件,包括历史视觉、历史触觉和动作信息。
这相当于让模型同时学习:
视觉世界怎么变化;
触觉世界怎么变化;
动作如何影响视觉和触觉变化;
视觉和触觉之间如何互相对应。
不过在实际推理时,作者主要使用未来触觉预测,而不是未来视觉预测。原因也很好理解:当前图像已经提供了足够的全局空间信息,而触觉预测更直接反映未来接触动态。同时,生成未来视觉会增加计算开销,降低推理速度。
所以这篇论文真正关心的是:
让机器人提前“想象”未来的手感。
十、第三步:Adaptive Fusion,什么时候相信视觉,什么时候相信触觉?

视觉和触觉都重要,但它们的重要性不是固定的。
在机器人还没接触物体之前,触觉基本没有信息。这个时候更应该相信视觉,因为视觉可以告诉机器人物体在哪里。
但一旦进入接触阶段,触觉就变得非常关键。比如刀是否贴住表面、夹爪是否抓稳、插头是否对齐,这些都需要触觉判断。
所以 OmniVTA 设计了一个 Adaptive Visuo-Tactile Fusion Policy,也就是自适应视触觉融合策略。
它会根据预测的接触状态,动态调整视觉和触觉的权重。
论文里有一个很关键的模块,叫 LTD Encoder,Latent Tactile Differential Encoder。
它做的事情很直观:
拿当前触觉 latent;
拿 world model 预测的未来触觉 latent;
计算两者之间的关系和差异。
这个差异很重要。
如果预测的未来触觉和当前触觉差别很大,可能说明接触状态即将发生变化。比如将要接触、将要脱离、将要滑动、将要受力变大。
然后模型会基于这些信息预测未来接触概率,并通过 gating mechanism 动态决定视觉和触觉的权重。
可以这样理解:
还没碰到物体时,视觉权重大;
开始接触后,触觉权重上升;
接触状态变化明显时,触觉对动作生成的影响更大。
这比简单拼接视觉和触觉更合理。
简单拼接的问题是,模型自己要从一大堆特征里判断什么时候用视觉、什么时候用触觉。但 OmniVTA 显式加入了接触概率和 gating 机制,让融合过程更符合接触任务的规律。
十一、第四步:RLTC,让机器人有“触觉反射”

在很多 diffusion policy 或 action chunking 方法里,模型会一次性生成一段未来动作,然后机器人按这段动作执行。
这种方式效率高,但问题是,它通常比较 open-loop。
也就是说,一旦动作开始执行,中间如果发生接触变化,比如物体突然移动、刀具偏离表面、夹爪压力变化,模型不一定能立刻修正。
OmniVTA 为了解决这个问题,加入了 RLTC,也就是 Reflexive Latent Tactile Controller。
它的作用可以理解成机器人的“触觉反射”。
RLTC 的输入包括:
当前真实触觉反馈;
world model 预测的触觉特征;
机器人最近的状态变化。
它会比较真实触觉和预测触觉之间的差异,然后输出一个细粒度修正动作。
比如模型原本预测应该保持稳定接触,但真实触觉突然变弱,说明可能快要离开表面。RLTC 就可以让机器人稍微压回去。
如果真实触觉突然变得过强,说明可能用力过大。RLTC 就可以让机器人减小压力,避免损坏传感器或物体。
这个模块以 60Hz 的频率运行,比慢速策略更快。因此它可以处理快速接触变化。
这也是 OmniVTA 和很多传统方法的关键区别:
它不只是“预测动作”,而是把预测和实时反馈结合起来,让机器人可以边做边修正。
十二、实验:OmniVTA 真的更好吗?

论文在真实机器人上评估了六类任务,包括擦拭、剥皮、切割、装配、抓取和调整。
评估重点有三个:
第一,物体多样性。也就是同一类任务中,换不同物体,模型是否还能成功。
第二,泛化能力。比如换不同高度,或者在切割任务里换一把没见过的刀。
第三,扰动鲁棒性。比如任务执行过程中突然把目标物体上下移动,打破当前接触状态,看模型能不能恢复。
论文比较了多种 baseline,包括 Diffusion Policy、加入触觉的 Diffusion Policy、KineDex、ForceMimic、RDP,以及去掉 RLTC 的 OmniVTA。
实验结果显示,OmniVTA 在六类任务中整体表现最好。
尤其是在接触强、扰动多的任务中,比如擦拭、剥皮、切割,OmniVTA 的优势更明显。
这说明它不是简单依赖视觉记住轨迹,而是真的利用触觉反馈来调节接触。
十三、实验结果怎么看?

Figure 10 和 Table III 展示了真实机器人实验结果。
这里可以重点看几个结论。
首先,OmniVTA 在 object diversity 评估中表现最好。也就是说,在不同物体上,它比其他方法更稳定。
这说明模型不是只记住某一个物体的轨迹,而是学到了一些可迁移的接触规律。
其次,在 unseen height 评估中,很多 baseline 表现下降明显。因为物体高度变化后,原来学到的视觉-动作对应关系可能不再准确。
但 OmniVTA 依然表现较好,说明触觉预测和闭环修正让它对几何变化更鲁棒。
第三,在切割任务中,论文换了一把训练时没见过的小刀。OmniVTA 仍然能保持较好的性能。这说明它并不是简单记住“用某把刀怎么切”,而是利用接触反馈判断切割过程。
第四,在扰动实验中,OmniVTA 的闭环控制器作用非常明显。当物体突然移动、接触状态被打破时,RLTC 可以帮助机器人重新建立稳定接触。
这对真实机器人操作非常重要。因为真实环境不可能永远静止、完美、没有干扰。物体可能滑动,人可能碰到桌子,工具可能位置稍微偏移。如果机器人不能实时修正,就很容易失败。
十四、消融实验:到底是哪部分有用?

论文还做了很多消融实验,用来回答一个问题:
OmniVTA 的提升到底来自哪里?
TactileVAE 有用吗?

作者比较了不同触觉编码方式,发现带隐式解码器的 TactileVAE 重建效果最好。
这说明把触觉建模成连续形变场是有效的。它能更好地保留局部接触结构,而不是把触觉粗暴压缩成一个普通向量。
未来触觉预测有用吗?

论文比较了多种触觉预测方式,OmniVTA 的 world model 在短期和长期预测上都更好。
这说明双流视触觉 world model 确实能学习视觉、动作和触觉之间的动态关系。
更重要的是,后续实验也说明,触觉预测越准确,策略成功率越高。如果触觉预测变差,模型对未来接触概率的判断也会变差,最终动作也更容易失败。
LTD 和 gating 有用吗?

作者逐步加入未来触觉预测、LTD Encoder 和 gating mechanism,成功率逐渐提升。
这说明不是“随便预测一点触觉”就够了。关键是要用合理的方式把预测触觉转化成策略信息。
LTD 让模型关注当前触觉和未来触觉之间的差异;gating 让模型根据接触状态动态调整视觉和触觉权重。
这两个模块共同帮助策略更好地理解“接下来接触会发生什么”。
RLTC 有用吗?
Figure 15 展示了扰动实验。
当接触被突然破坏时,OmniVTA 可以通过 RLTC 重新恢复接触。这说明 RLTC 不只是锦上添花,而是在真实接触环境中非常关键。
如果没有这个模块,模型执行 action chunk 时更像是在按计划走,一旦环境变化,恢复能力就弱。
而加上 RLTC 后,机器人可以根据实时触觉反馈快速修正。
十五、这篇论文最值得关注的点
我觉得这篇论文最重要的价值,不只是“用了触觉传感器”,而是它重新定义了触觉在机器人操作中的角色。
过去很多方法里,触觉只是一个额外 observation。
就像给模型多加了一个传感器,让它知道当前有没有碰到。
但 OmniVTA 进一步提出:
触觉不应该只是被动观察,而应该被预测、被比较、被用于闭环控制。
这就把触觉从“输入信息”变成了“动态模型的一部分”。
可以用一句话概括:
普通视触觉策略是: 看到 + 摸到 → 输出动作。
OmniVTA 是: 看到 + 摸到 → 预测接下来会摸到什么 → 执行动作 → 检查真实触觉是否符合预测 → 不符合就快速修正。
这个逻辑明显更接近人类操作物体的方式。
我们在操作物体时,也不是只根据当前一瞬间的触觉做反应,而是会形成某种预期。比如削皮时,我们预期刀应该持续贴着表面;插 USB 时,我们预期轻微阻力之后应该顺利进入;擦桌子时,我们预期抹布应该持续和桌面接触。
一旦真实手感和预期不一致,我们马上调整动作。
OmniVTA 就是在机器人系统里实现了类似机制。
十六、这篇论文和 world model 有什么关系?
现在很多机器人论文都在讲 world model,但不同论文里的 world model 含义不完全一样。
有些 world model 关注未来图像生成,希望模型预测执行某个动作后画面会变成什么样。
有些 world model 关注长时序任务规划,希望模型在脑中模拟未来很多步。
OmniVTA 的 world model 更偏向 contact dynamics model,也就是接触动态模型。
它不是重点生成一个漂亮的未来视频,而是重点预测未来触觉状态。
这点很重要。
因为在接触密集型操作里,未来图像不一定是最关键的。比如削皮时,画面变化可能很小,但触觉变化非常关键。机器人真正需要知道的是刀具和物体之间的接触是不是稳定、力是不是合适、有没有滑动。
所以 OmniVTA 的 world model 可以理解成:
不是让机器人“看见未来”,而是让机器人“预感未来的手感”。
这也是它和很多纯视觉 world model 的区别。
十七、这篇论文有什么局限?
当然,这篇论文也不是解决了所有问题。
首先,它主要使用的是平行夹爪和指尖触觉传感器,而不是复杂的五指灵巧手。平行夹爪的接触形式相对简单,如果迁移到灵巧手,触觉分布会更复杂,动作空间也会更高维。
其次,方法比较依赖高质量触觉传感器和稳定的时间同步。触觉数据频率高、变化快,如果传感器噪声大或者同步不准,world model 的预测可能会受影响。
第三,OmniVTA 的 world model 主要预测短期触觉变化,而不是长时序任务级别的世界模型。它更适合解决“接下来这段接触怎么变化”,而不是负责完整的高级任务规划。
第四,数据集虽然规模已经很大,但仍然集中在特定硬件和传感器配置上。未来如果要推广到更多机器人本体、更多传感器、更多家庭场景,还需要更大规模的数据和跨平台适配。
十八、对机器人学习有什么启发?
这篇论文给我的一个很重要的启发是:
未来的机器人操作模型,可能不能只追求更强的视觉理解,也不能只把触觉当作一个额外模态简单拼接进去。
真正有价值的是让模型理解不同模态在物理交互中的作用。
视觉适合提供全局空间信息,比如物体在哪里、目标在哪里、环境结构是什么。
触觉适合提供局部接触信息,比如有没有碰到、压力多大、有没有滑动、摩擦状态如何。
动作则连接视觉和触觉,决定接触状态如何随时间变化。
如果把视觉、触觉和动作放在一个动态模型里,机器人就不只是被动感知环境,而是可以预测自己动作带来的物理后果。
这对 contact-rich manipulation 非常关键。
尤其是未来如果要做灵巧手、全身人形机器人、家务机器人、工具使用机器人,触觉预测和高频触觉反馈可能会变得越来越重要。
因为越是接近真实世界,越会遇到视觉看不清、物体会滑动、接触状态不稳定的问题。
十九、总结
OmniVTA 这篇论文可以用一句话总结:
它让机器人不只是“看着操作”,而是能够“预测接触、感知偏差、快速修正”,从而更稳定地完成擦拭、剥皮、切割、装配、抓取和手内调整等接触密集型任务。
它的核心贡献包括:
构建了大规模视触觉操作数据集 OmniViTac;
把接触任务按照物理接触模式分成六大类;
提出了 TactileVAE,用于学习紧凑的触觉表示;
提出了 Visuo-Tactile World Model,用于预测未来触觉状态;
设计了自适应视触觉融合策略,根据接触状态动态调整视觉和触觉权重;
加入了 60Hz 的 RLTC 触觉反射控制器,实现高频闭环修正。
这篇论文最值得学习的地方,是它没有把触觉当成一个简单附加输入,而是把触觉放进了“预测—执行—反馈—修正”的闭环里。
对于机器人来说,真正困难的不是在静态画面里识别物体,而是在真实物理世界里稳定地和物体发生接触。
而 OmniVTA 走出的这一步,就是让机器人开始学会:
不只用眼睛看世界,也用“手感”理解世界。