人形机器人正在以肉眼可见的速度进入公众视野,春晚舞台、工厂流水线、家庭场景的讨论接连出现。外界的目光大多聚焦在机器人本体的灵巧程度、模型的泛化能力,以及哪家公司的演示视频更令人惊艳。然而在这场热闹的竞赛背后,有一个层面长期处于公众视野的盲区:支撑具身智能模型高速迭代的AI基础设施,正在经历一场同样深刻的技术重构。

百度智能云主任架构师应茹近日在第三届中国具身智能与人形机器人产业大会上发表了《百度百舸全栈AI Infra助力具身智能模型加速迭代》的主题分享,并在会后接受机器人大讲堂专访,从云端AI Infra的视角,系统梳理了当前具身智能研发的技术现状与工程痛点。
01.
具身智能模型技术路线尚未收敛
理解具身智能的当前处境,需要先厘清它的技术分层。应茹将云上客户的具身研发归为两大方向:操控类模型与运动控制策略。前者面向长程的精细操作任务,如家务、拆快递、折衣服;后者面向平衡控制与敏捷反应,如舞蹈动作、武术套路等高难度全身协同运动。两个方向在技术路线、训练规模、工程需求上差异显著,但都在近期迎来了各自的范式转折点。
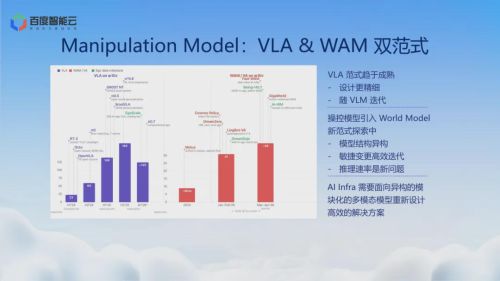
操控类模型目前存在两条主流范式并行推进。一条是 VLA(视觉-语言-动作)路线,常见的架构是双系统分层结构和单体结构。以双系统分层架构为例:上层通过极大规模参数量(如大于200B的 MoE结构)的视觉语言模型(VLM)构建“通用大脑”,进行高层语义推理与长程任务拆解;下层通过高频策略进行实时动作映射。而单体结构中的 VLM backbone 相对较小,通常在 10B 以内。另一条则是引入世界模型(World Model)的路线。它旨在让模型于内部建立对物理规律的理解,赋予机器人内在的“物理直觉”,使其不仅能感知当前的世界,更能在脑海中预演动作交互后的环境变化。
从公开论文成果的统计趋势来看,两条路线目前都在快速推进。特别是 WAM方向,最近4、5个月内出现的云端大规模训练需求,整体处于快速试错与范式探索阶段。这意味着具身智能模型尚未完成底层技术路线的收敛,各家头部企业仍在用真金白银的研发算力,多路径押注不同的通向 AGI 之道。
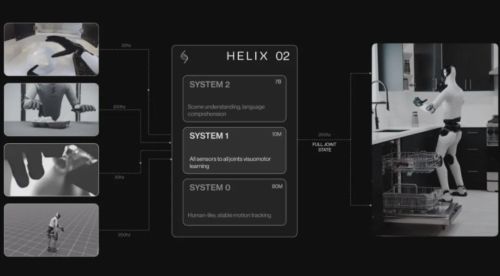
运动控制策略的范式转移也值得关注。过去,运控策略的主流做法是为每一套动作单独设计训练所需的奖励函数,彼此割裂,无法做规模化扩展。但近期,英伟达开源的Sonic项目用大量人类动捕数据替代手工设计reward,将运动策略从1M参数量扩展到40多M,实现了统一的全身控制策略。Figure AI的Helix02在发布时也明确提出了“System 0”概念,指向同一个方向:用统一全身控制底座取代碎片化的独立reward范式。

学术界与工业界在这一点上思路非常一致:运控策略正在走向统一化与规模化。这个判断的工程含义是直接的——原来两台服务器就能搞定的训练任务,现在需要扩展到128卡、几十台机器的集群化部署。训练规模的跃升,推动了运控方向大规模上云的需求。
02.
数据瓶颈仍是核心卡点
技术路线的方向已经清晰,但支撑这些路线持续迭代的燃料——数据,却面临严重的工程化瓶颈。
在具身智能的研发链条中,算力往往是最容易被量化、最容易被讨论的资源。但应茹明确指出,当前行业最迫切却尚未被很好解决的痛点之一,是规模化Ego数据的处理能力滞后。
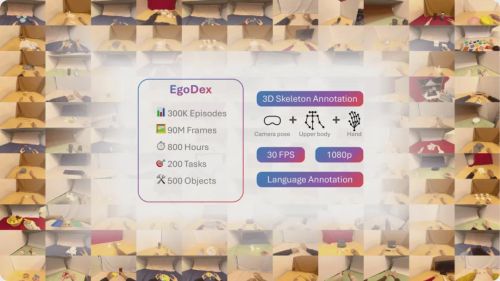
Ego数据,即第一人称视角视频数据,正在成为具身大模型规模化训练的核心数据来源。这一趋势在最近一年明显加速:Apple发布EgoDex数据集,验证了第一视角视频用于机器人训练的潜力;Tesla明确将Optimus的训练策略从遥操作全面转向人类视频采集;NVIDIA推出EgoScale,基于超两万小时第一视角视频进一步验证了Ego数据的缩放定律——数据规模越大,机器人的智能操作能力越能持续提升。
这一趋势的背后逻辑并不复杂:传统遥操作数据的采集成本高、规模化瓶颈明显,难以支撑模型持续泛化迭代;而人类日常操作的第一视角视频,天然具备高扩展性,且更贴近真实的人机操作逻辑。
然而,从原始Ego视频到可直接用于模型训练的标准数据集之间,存在一条尚未被系统性打通的工程鸿沟:大量的清洗、标注、结构化后处理工作,目前缺乏规模化、标准化的处理管线。这不纯粹是算法问题,也包含大量工程问题,它实实在在地卡住了模型迭代的速度。
这个观察揭示了具身智能产业的一个结构性矛盾:研发力量高度集中在模型架构和训练范式的创新上,但支撑这些创新所需的数据工程基础设施,建设进度明显滞后。模型再先进,如果喂不进去足够质量和规模的数据,迭代速度就会受制于数据供给端的瓶颈。
03.
模型范式仍未收敛情况下的算力选型困境
数据问题之外,算力的适配性同样是一道关键命题。具身智能领域有一个容易被忽视的现实:当前主流的VLA或WAM 模型,其参数量级多集中在 5B 至 20B 之间,而非千亿规模的极限参数。这种中等规模的模型特性,决定了其对算力的需求并非简单的“暴力堆叠”,而是更看重各维度硬件资源的极致平衡。这便引出了一个核心思考:在当前的算力背景下,什么样的算力配置,才是具身智能规模化落地的“最优解”?
应茹引用了DeepSeek V4技术报告中的一个论点:卡间或机器间每GB互联带宽所能支撑的模型算力存在一个合理值,如果模型尺寸没有达到这个算力值,超配的带宽就是浪费。这个逻辑的实践含义是:对于20B量级以下的VLA或WAM模型,盲目堆砌最高端的硬件配置,不仅不会带来等比例的性能提升,反而会造成显存、带宽、算力等多个维度的资源错配,推高研发成本。百度百舸面向这个阶段的具身模型,专门提供了高性价比的算力配置以及配套的多机并行加速套件,在合理成本下实现最高效的训练产出,让每一算力单元都能精准服务于模型的快速迭代。
与此同时,多模态架构中还存在另一个隐性浪费:视觉编码器ViT与语言大模型LLM天然异构,极易出现算力负载失衡。百度百舸开源了全模态训练框架 LoongForge,专为多模态模型训练提供高效解决方案。LoongForge引入模型异构并行、DP负载均衡等多模态专属优化技术,将多模态模型训练性能整体提升15%至45%。这个数字背后,同样是对“隐性浪费”的系统性清理。
从更宏观的视角看,这背后折射出具身智能产业的一个现实约束:大多数具身企业并非资金无限的科技巨头,研发预算有限,算力成本的控制直接影响迭代速度和生存周期。如何在有限预算内最大化模型迭代效率,是这个行业大多数参与者面临的真实问题,而不是一个可以用“买更好的卡”来简单回答的问题。
04.
灵活性与性能的两难是工程化的核心矛盾
解决了数据和算力配置的问题,还有一个更深层的工程矛盾横亘在研发团队面前:开源框架灵活,支持底层代码的快速变更,但性能优化程度有限;高度优化的框架性能极致,但往往不支持敏捷变更。
这个矛盾在具身智能领域尤为突出。当前具身模型的架构仍处于快速演化期,VLA引入World Model作为backbone的方式在持续迭代,训练范式也在频繁调整。对于研发团队而言,今天跑通的训练流程,明天可能就需要做底层修改。如果底层框架不够灵活,每一次架构调整都意味着巨大的工程成本;但如果为了灵活性牺牲性能,训练效率的损失同样难以承受。
应茹将百度百舸的应对策略描述为:在开源的、相对灵活的框架上提供加速套件,让研发团队能够在灵活性和效率之间找到平衡点。这不是一个听起来很炫的技术方案,但它直接对应了研发团队的真实痛点。

World Model的引入带来了一个新的具体问题:World Model本身通常采用扩散结构,在推理端存在明显的效率瓶颈,实时性不足。百度百舸针对WMA、WAM、VA等主流开源世界模型做了一轮工程化加速,推理延迟最低可降至原有水平的四分之一。这个加速效果的实现路径,并非依赖某种神秘的算法突破,而是建立在对底层硬件的深度理解之上,精准拆解模型的资源占用特征,结合对芯片缓冲区大小、指令周期、硬件并行度等底层参数的深度理解,做针对性适配优化。
这种“沉淀复用”的能力,是云端AI Infra提供商相对于单一企业自建基础设施的核心优势之一。单个具身企业很难为了优化一个推理框架投入专门的底层工程团队,但云端平台可以将这种优化能力摊薄到所有客户身上。
05.
基础设施的价值,在产业加速期才真正显现
将上述四个维度的问题串联起来,可以得出一个整体判断:具身智能产业目前所处的阶段,与大语言模型爆发前夕有几分相似,技术路线尚未收敛,多种范式并行竞争,工程化程度参差不齐,大量研发资源消耗在重复建设基础设施上。

在这个阶段,基础设施的价值往往被低估。具身智能的产业迭代闭环,涵盖数据处理、模型训练、仿真评测、部署推理的全链路工作流,任一环节的效率滞后都会拖累整体进度。对于大多数具身企业而言,核心竞争力在于模型架构的创新和场景的深度理解,而不在于自己搭建和维护一套完整的AI基础设施。将基础设施外包给专业平台,让自己的工程资源聚焦在真正有差异化价值的地方,是一个理性的资源配置选择。
值得注意的是,应茹特别强调了国产芯片的适配问题。通过LoongForge框架实现一套代码同时兼容通用GPU与昆仑芯XPU,这在当前的地缘政治背景下具有超出纯技术层面的意义。具身智能的产业化进程,不可能脱离算力供给的现实约束。如何在国产算力底座上实现与国际主流平台相当的训练效率,是整个行业必须面对的工程课题,而不是一个可以回避的选项。
当然,这种判断也有其边界条件。对于少数具备足够规模和技术深度的头部企业,自建基础设施可能仍然是更优选择,因为定制化程度和数据安全的考量会超过外包的效率收益。但对于产业中的大多数参与者,尤其是处于快速迭代期、需要在有限资源内最大化研发效率的中小型具身企业,成熟的云端AI Infra平台提供的不只是算力,而是一套经过大规模验证的工程方法论。
从这个角度看,百度百舸在具身智能方向的布局,既是一个商业决策,也是一个产业基础设施建设的组成部分。具身智能能否在中国实现真正的产业化落地,不仅取决于模型算法的突破,也取决于支撑这些突破的工程基础设施是否足够完善、足够高效、足够可及。