

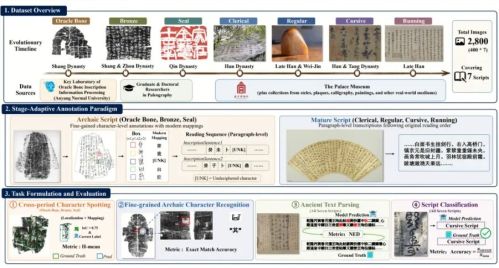
顶尖的人工智能不仅要能看懂屏幕上跳动的现代代码,也需要读懂三千年前龟甲上的刻痕。据OSCHINA报道,腾讯混元大模型、SSV数字文化实验室等机构联合多所高校与故宫博物院,正式推出了“Chronicles-OCR”。这是业界首个完整覆盖汉字“七体之变”演化轨迹的中国古文字感知评测基准。

为了真实反映大模型的识别能力,该数据集由领域专家进行了多层级交叉标注,包含 2800 张严格平衡的高质量图像。针对甲骨文、金文、篆书等古早字体,团队采用了单字级的精细标注;而对于隶、楷、行、草等成熟字体,则采用了保留原始阅读顺序的序列级转写。
主流视觉模型全军覆没
项目团队基于该基准设计了四个层层递进的核心任务,严格将大模型的“视觉感知”与“语义推理”解耦开来。在对包括GPT-5、Gemini 3.1 Pro、Claude Opus 4. 7 在内的 28 个主流多模态大语言模型进行评测后,结果却令人大跌眼镜。
在面对缺乏现代版式先验的古早字体时,主流大模型在端到端检测任务中全军覆没,细粒度识别的最高准确率也仅有27.1%。令人意外的是,实验表明此时开启大模型的推理(Reasoning)模式,反而会放大感知的不确定性,导致识别表现进一步下降。
揭示微观笔画识别短板
评测还发现,在进行字体分类时,目前的视觉大模型更容易去识别载体的纹理材质,而不是去判别微观的笔画风格。这意味着今天最顶尖的AI模型,在面对中国传统古文字时,依然还远远没有做到真正的“读懂”。
汉字从殷墟甲骨一路演化至今,每一笔一画都承载着文明的连续性。Chronicles-OCR的开源不回避这一技术现实,它通过清晰可见的差距,为未来视觉大模型从简单的“识字”走向深度“读史”提供了明确的优化方向。












