AI行业有个规律,关键数据的开放,往往比模型突破更能引爆产业。
一如当年李飞飞开源ImageNet,就加速了计算机视觉的跃迁,随后催生出整条数据标注产业链。
具身智能正站在同样的节点上。当堆参数、堆算力的Scaling Law在物理世界撞上天花板,大家开始发现,提升大脑能力,除了模型,更缺的是数据。
因此,如今,行业共识开始转向,训练场这个全新赛道开始浮现,或者说,具身数据的规模化生产模式开始盛行。
而这一次,答案不再是堆GPU,而是建训练场。本质上看,训练场不是“训练机器人”,而是在给大脑修一条高速公路。

01.
跟不上小脑的大脑
具身智能圈有个共识,本体的脚越来越稳,大脑的手却伸不出来。
近几年,人形机器人硬件进展神速。从踉跄原型机到春晚翻跟头,再到工厂稳定搬运的量产机型,“会走会跑会做基础动作”的小脑能力已经成熟。但远远大脑不够。
人形机器人走进真实环境,光照变了、物体没见过、力反馈超出预期,就很难进行真正的任务,这些都不是算法问题,是数据饥荒。
这就好比教孩子骑车,看一百遍视频,不如路上摔一跤。仿真能教“套路”,教不会“手感”。物理世界的摩擦、形变、机械不一致性,仿真永远无法穷举。
单个基座模型预估需要5000万小时数据,行业真机存量却可能只有数万小时。千倍缺口,正是训练场被集中投注的底层逻辑。

02.
重修一条数据高速公路
当然,从乐聚等头部企业的行业实践来看,这条路能否跑通,关键在三个环节:本体一致性、采集效率和交付闭环。
本体一致性是前提。如果每台机器人的机械结构、空间标定、时间同步都不一样,采出来的数据就无法复用。
例如乐聚的做法是通过车规级MVT制造验证测试,确保每台出厂机器人的一致性;再配合机械、模型、光学联合标定,把静态误差和动态误差都控制在可复用范围内。
有了本体一致性,才能谈采集效率。
例如乐聚训练场初期,一个遥操员一天只产出1小时有效数据;通过管理流程优化,现在极限能做到8到10小时。针对不同任务类型,采集方案也做了分级,并且能根据任务精度匹配对应的采集方式。

当然,数据采完只是开始,交付闭环才是工业化。类似乐聚的链路是打通了任务评估→遥操采集→上传汇总→标注审核→格式转换→云端或硬盘交付→模型在训练场内评测的闭环,这套飞轮才最终把单轮迭代从7到10天压缩到2到3天,部署成功率从不足60%拉到90%以上。
在Kuavo 4 Pro实测中,使用乐聚LET真机数据训练的模型,一次成功搬起率100%(15/15),同场景Pi0.5只有33.33%,意味着乐聚数据已经实现质变。
03.
谁在付“高速费”?
回顾其2023年提出来的生态计划,一条“基础设施层—核心技术层—场景应用层”的全链条生态架构已经成型。基础设施层是乐聚制造和数据的基础设施,包括两座工厂加训练场,工厂造身体,训练场建大脑;核心技术层是核心零部件供应链,包括一体化关节、电机、灵巧手、数据平台、具身大脑、操作系统等上下游企业;场景应用层则聚集了一汽、海晨物流、华为、腾讯、阿里云、南方电网、海信等40余家场景伙伴,横跨工业、商服、科研、家庭四大领域。
那么,到底谁在为训练场买单?目前来看,训练场的场景大多从企业实践中来。例如乐聚训练场的场景设计走两条线。
一部分来自真实工业客户的搬箱子、拆垛、上下料、分拣等产线上真实在跑的任务,海晨物流、一汽、兆丰等企业已经在这些场景中跑通了数据落地。
另一部分直接来自基模和数据客户的需求订单。客户提出商超、家居等泛化场景需求,训练场按需集中设计、定向采集。从摆好货架等客上门,到客户拿需求单来定向采集,这是训练场从“概念”到“产品”最硬的证明。
在这一趋势下,数据也正在成为独立产品。
从乐聚的数据情况来看,三类客户清晰。第一类,训基座模型的大厂,缺真机数据完成“最后一公里”收敛。第二类,高校和实验室,花几十万买高质量数据远比自建团队划算。第三类,场景落地的后训练团队,这也是未来最大增量。
客户特性也使得乐聚训练场内的数据还呈现典型“金字塔”结构。
其底层是互联网数据,量大便宜,主要用于让模型“理解世界”;中层仿真和ego无本体数据,成本较低,主要做预训练和RL冷启动;顶层真机数据,质量最高成本最高,用于后训练微调,直接决定任务成功率。
目前,即便是仿真路线最坚定的支持者,在后训练阶段仍需采集少量真机数据做快速对齐。400条高质量真机数据的训练效果,能超过1300条低质量数据。
这也构成了乐聚这类训练场模式的生态护城河:行业里有人倾向多用便宜的ego数据做预训练,策略上没问题,但那更像“国道”,走得通,但路程更远,最终仍需上“高速”才能更快抵达终点。

04.
先把飞轮转起来
训练场的故事,本质是“把基建先搭起来”。
大模型、世界模型等技术路线都没完全跑通,当下唯一在工厂真正跑通的,就是真机训练场这条路。
从乐聚的迭代节奏来看,路径也很清晰:1.0解决“让机器人动起来”的基本采集;2.0升级为多模态、分场景、分构型的精细化数据产品;未来3.0要让遥操精度向真人逼近,从平面轮式走向斜坡、台阶、草地等复杂地形。
先修路,再通车。让高质量数据稳定流进模型,通过生态让飞轮更快转起来。就像智能驾驶在数据推动下进入高速发展期,如今具身智能缺的不是更好的算法,而同样是足够多、足够好、能稳定交付的真机数据。
训练场这条高速公路,正是要把这个缺块补上。

05.
从“修路”到“建生态”
但乐聚训练场的布局从不止是卖数据,生态或许才是其想要实现的真正目的。
与此同时,乐聚还与哈工大、北京大学、苏州大学等高校持续联合攻关,打通产学研闭环。
现在这条路乐聚正在一步一步实现。
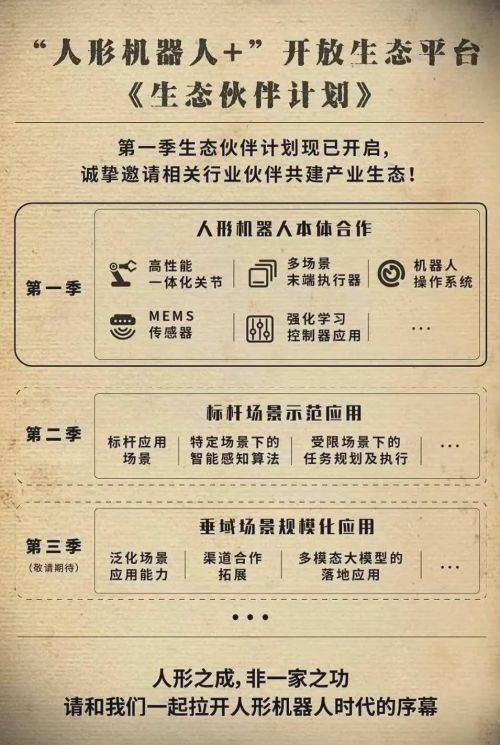
乐聚在拥有“本体—数据—大小脑—应用场景”全栈资源后,乐聚生态计划开启了第三阶段,正式招募二次开发合作伙伴。 这意味着,开发者不需要自建本体、自采数据、自搭训练场,基于乐聚的全套基础设施就能做场景微调和应用开发。
这是把最难、最苦、最重的活先干了。举个更形象的例子,乐聚这是把路基铺好了,收费站拆掉了,谁都可以上来跑。对于开发者而言,过去做具身智能应用,要自己搞定本体、自己搭训练环境、自己采数据、自己去找场景,每一个环节都是高门槛。
现在有了现成的高速公路,开发者只需要聚焦在自己的场景里,把应用做深、做好。这意味着,商业化的速度将不再被基础设施拖累。就像李飞飞用ImageNet加速了AI视觉时代,具身智能今天缺的不是更好的算法,而是足够多、足够好、能稳定交付的真机数据。
当数据这条高速公路建成通车,谁能在这条路上跑出最快的商业化速度,答案正在被书写。