


从科幻电影中的全能管家,到现实工业中的自动化臂膀,我们对“通用机器人”的想象与探索从未停止。近年来,随着人工智能领域大型语言模型(LLM)和视觉基础模型的巨大成功,一个自然而然的问题摆在了机器人学界面前:我们能否为机器人也打造一个“基础模型”,让它像人类一样,能够理解多样的指令,并灵活完成各种从未见过的任务?

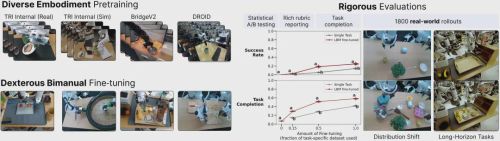
这个问题的答案,或许就藏在刚刚登上国际顶级期刊《科学·机器人学》(Science Robotics)最新一期封面的研究中。来自丰田研究院(TRI)等机构的研究团队,通过一项重磅实验为我们揭示了大型行为模型(Large Behavior Models, LBMs)的真实能力。这项研究并非停留在理论或简单的模拟,而是基于约1700小时的机器人演示数据,在模拟和真实世界中进行了超过47000次的严苛测试,最终为通往通用机器人的道路提供了坚实的经验证据和洞见。
01.
“大海捞针”式的预训练:从海量数据中学习通用技能
要让机器人变得“通用”,传统的“专才”培养模式显然行不通。过去,研究者们通常会为一个特定任务(比如“拿起苹果”)训练一个专门的模型。这种模型在特定场景下表现优异,但一旦任务或环境稍有变化(比如苹果换成梨,或者光线变暗),它就可能“罢工”。这种脆弱性,是通往通用机器人之路的最大障碍之一。
受AI领域“大力出奇迹”的启发,研究者们提出了大型行为模型(LBM)这一新范式。其核心思想很简单:不再为每个任务单独训练模型,而是用一个庞大而统一的模型,去学习成百上千种不同任务的解决方式。就像人类通过观察和实践学会各种技能一样,LBM的目标是从海量、多样化的数据中,自主提炼出关于物理世界和机器人操作的通用知识。
为了实现这一目标,研究团队构建了一个名为“Ramen”的庞大预训练数据集。这个数据集包含了约1700小时的机器人操作演示,涵盖了超过500个内部收集的高多样性任务以及大量公开的机器人数据。这些任务五花八门,从简单的“把杯子放到杯垫旁”,到复杂的“整理早餐托盘”,再到需要精细操作的“给苹果去核”。这些数据不仅有真实的机器人操作录像,也包含了模拟环境中的数据,形成了一个虚实结合的庞大知识库。
有了数据,还需要一个足够聪明的“大脑”来学习。研究团队采用了一种名为“扩散策略(Diffusion Policy)”的生成模型。简单来说,这个模型能够接收来自多个摄像头的RGB图像、描述任务的文本指令(例如“将猕猴桃放到桌子中央”)以及机器人自身的状态信息作为输入,然后像AI绘画一样,“生成”一系列精准的、连续的机器人动作指令。其内部核心是一个强大的Transformer架构(DiT),使其能够高效地处理和整合不同来源的信息,做出最终决策。
02.
严格的“大考”:LBM与单一任务模型的正面交锋
模型训练好了,但它真的比传统方法更好吗?为了回答这个问题,研究团队设计了一套严苛的评估流程,旨在以最客观、最严格的方式检验LBM的真实能力。
这次“大考”的核心是“盲测”和“随机A/B测试”。在真实机器人评估环节,操作员在测试时完全不知道自己正在运行的是哪个模型——是经过预训练和微调的LBM,还是从零开始训练的单一任务基线模型。模型的测试顺序也是完全随机的,从而排除了因环境变化(如光线改变)或人为偏好带来的任何潜在偏见。这种双盲测试在临床医学中是黄金标准,但在机器人学研究中却因其复杂性而鲜有应用。
整个实验的物理平台、评估环境和任务多样性共同构成了这次严苛的考验,其规模和复杂性见下图,涵盖了从简单的放置到需要精细双臂协调的复杂长序列任务。
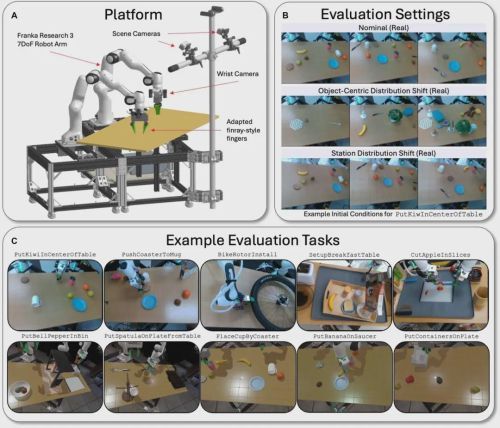
团队在真实世界中进行了1800次这样的盲测,同时在模拟环境中进行了超过47000次的自动化测试。评估分为两大类:“已见任务(Seen Tasks)”和“未见任务(Unseen Tasks)”。
对于模型在预训练数据中已经“见过”的任务,结果显示,经过微调的LBM在性能上全面优于单一任务基线模型。尤其是在引入“分布偏移”(Distribution Shift,即测试环境与训练环境有细微差别,例如物体初始位置稍有变动)后,LBM的优势更加明显。这表明,从海量数据中学习到的通用知识,让LBM变得更加稳健(robust),对环境变化的适应能力更强。
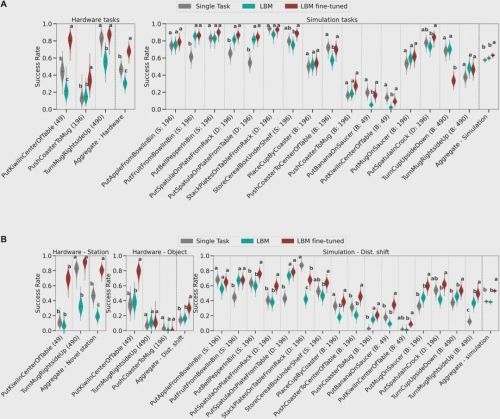
然而,真正的考验在于“未见任务”——那些LBM在预训练阶段从未接触过的全新挑战。这直接关系到模型是否具备“举一反三”的泛化能力。在这里,LBM展现了其最惊人的价值:数据效率(Data Efficiency)。
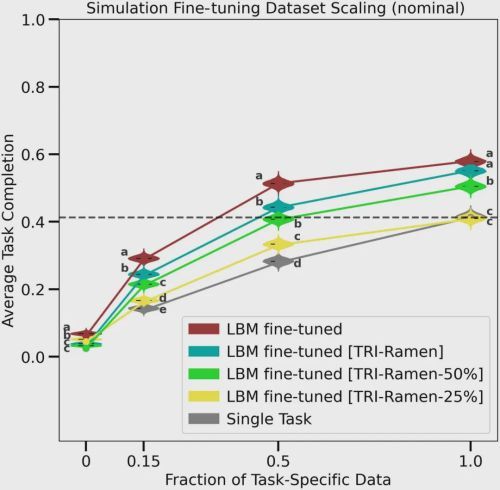
研究结果清晰地表明,要在一个新任务上达到与单一任务模型相当的性能,经过预训练的LBM仅需要一小部分(a fraction of)的训练数据。在模拟实验中,研究团队发现,LBM平均只需要不到30%的数据,就能追平甚至超越在100%数据上训练的单一任务模型。
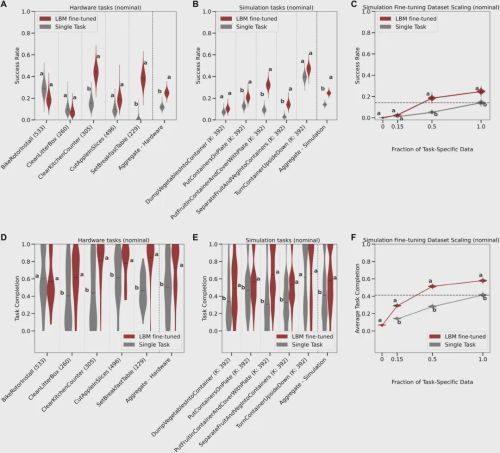
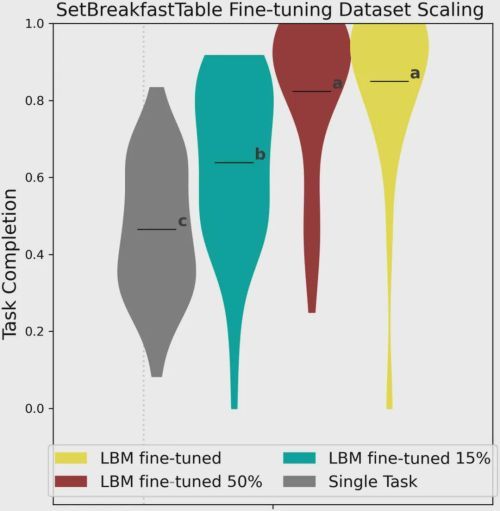
这个结论在真实世界实验中得到了更有力的印证。以“摆放早餐桌(SetBreakfastTable)”这个复杂的长序列任务为例,它从未出现在预训练数据中。
研究团队发现,仅使用了15%的专属任务数据进行微调的LBM,其任务完成度的表现就已经在统计上显著优于使用了全部100%数据从零开始训练的单一任务模型!LBM仅需不到五分之一的数据就能超越传统模型,学习效率提升超过5倍。这意味着,预训练赋予了LBM一个极高的“起点”,使其能够以数倍于传统方法的效率快速学习和掌握新技能。这对于降低机器人学习新任务的成本和时间至关重要,是LBM最具吸引力的优势之一。
03.
从量变到质变?通往通用机器人之路的启示
这项规模宏大的研究,为机器人领域关于大型行为模型(LBM)的讨论,从众说纷纭的猜想推向了坚实的实证科学。它清晰地回答了核心问题:在当前技术水平下,基于大规模、多样化数据进行多任务预训练,是一条切实有效且充满希望的技术路径。
研究团队进一步探索了“规模效应(Scaling Laws)”。他们发现,随着预训练数据集规模的扩大,LBM在未见任务上的最终性能也随之平滑提升。这意味着,至少在当前的数据和模型规模下,我们还远未触及性能的天花板。“更多的数据,更好的模型”这一在AI领域被反复验证的规律,在机器人学中同样适用。这无疑为未来的研究指明了方向:继续扩大数据的多样性和规模,有望催生出能力更强的机器人基础模型。
当然,这项研究也保持了科学的严谨和审慎。研究者们指出,虽然前景光明,但LBM并非“银弹”。例如,未经任务专属数据微调的“零样本”LBM,其表现并不稳定,有时甚至无法正确理解任务指令。这表明,“预训练+微调”的范式在现阶段仍然是不可或缺的。此外,研究还强调了严格统计分析的重要性,警示领域内许多研究可能因样本量不足而得出不可靠的结论,为未来的机器人学研究设立了更高的实验标准。








