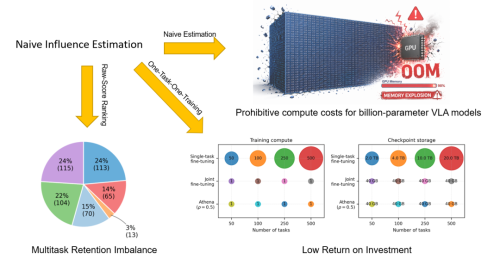
DexHoldem:机器人打德州扑克的真正挑战是维护游戏秩序
让机器人去打德州扑克,这件事听起来更像是一个带着几分趣味性的 demo。
但这篇论文真正想要研究的,并不是机器人是否会进行算牌,也不是它能否像人类玩家那样进行 bluff。论文所关心的,其实是一个更为底层、也更贴近现实的具身智能问题:
机器人是否能够在真实的桌面环境当中,准确理解当前的状态,进而选取合适的动作,借助灵巧手完成相应操作,并使桌面状态仍然能够继续支撑下一步任务的开展?
这就是论文 DexHoldem: Playing Texas Hold'em with Dexterous Embodied System 想做的事情。
简单来说,DexHoldem 将德州扑克桌面转化成了一个面向真实世界灵巧操作的 benchmark。机器人不仅需要对扑克牌与筹码进行操作,还需要理解当前的牌局状态,并且要在真实物理环境当中持续完成感知、决策以及执行。
它并不是让机器人仅仅完成一次“抓起物体”的短时任务,而是要求机器人在一个持续变化的桌面环境当中不断开展操作。

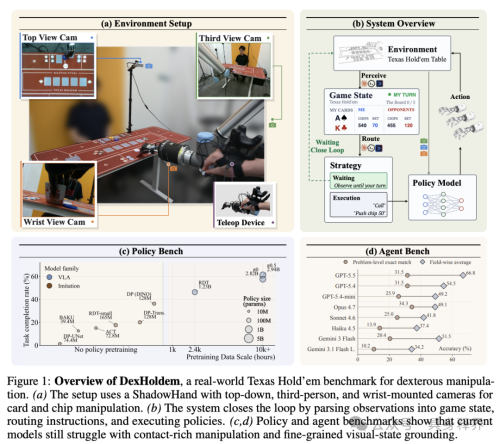
论文中的Figure 1很适合作为开篇图。该图完整展示了DexHoldem的整体设定:真实硬件由ShadowHand与UR机械臂构成,输入来自俯视相机、第三人称相机以及腕部相机;系统需要先对桌面状态进行感知,再开展路由决策,最后调用低层policy来执行具体动作。Figure 1还展示了policy benchmark以及agent benchmark的整体结果,可以让读者一眼看出,这并不是一个单纯的扑克游戏,而是一个面向真实灵巧操作系统的benchmark。
为什么选择德州扑克?
德州扑克这项任务表面上看起来并不复杂:桌面之上无非只有扑克牌以及筹码。
但对于机器人而言,这实际上构成了一个相当“刁钻”的场景。
首先,扑克牌本身十分轻薄。机器人需要把一张牌从桌面上拾取起来,再将其放回到指定位置,相较于让普通夹爪抓取一个方块,这项操作的难度显然更高。灵巧手需要对手指接触、摩擦、角度、力度以及微小误差进行处理。
其次,筹码同样并不容易操作。机器人既需要完成对筹码的推动与回拉,还要依据不同面额对筹码进行移动;而动作只要稍有偏差,就可能把旁侧的扑克牌或其他筹码碰乱。
更关键的一点在于,德州扑克并不是一个静态不变的任务,牌桌的整体状态会伴随每一步动作的推进而持续发生变化。机器人不仅需要准确知道当前轮到哪一方行动、现有公共牌的具体情况、当前下注的数额、自己所剩筹码的数量以及对手所剩筹码的数量,还需要进一步判断在此时此刻究竟应当看牌、下注、跟注、亮牌,还是继续等待。
因此,这篇论文之所以选取德州扑克,并不是因为“扑克”这一对象本身具有多么关键的意义,而是因为它将许多真实具身系统所面临的难点,压缩进了一个可控的桌面场景之中:
精细操作、视觉理解、状态记忆、动作选择以及闭环执行。
这也正是DexHoldem与许多传统机器人benchmark存在差异的地方。许多benchmark往往只关注机器人能否完成某一个动作,而DexHoldem则会进一步追问:
机器人在完成这一动作之后,当前桌面状态是否仍然能够继续支撑后续操作?
DexHoldem所评测的并不是某一个单独的模型,而是由多个环节共同构成的一整套系统
DexHoldem 可以分成三个层次来看。
第一层是 Dexterous Hand Policy Bench ,评测低层灵巧操作能力。
第二层是Agentic Perception Bench,用于评测agent是否能够准确理解当前牌桌的状态。
第三层是System-Level Evaluation,用于评测完整闭环系统是否真的能够运行起来。
这三个层次,恰好对应着真实具身系统当中的三个关键问题:
手部系统能不能完成操作?视觉系统能不能看懂状态?决策系统能不能把流程串联起来?
第一层是低层policy,所关注的问题在于灵巧手是否能够完成原子动作?
DexHoldem 围绕德州扑克场景设计了 14 个相关的原子操作 primitive。
这些动作包括:
拿起左边或右边的手牌;
放下左边或右边的手牌;
展示左边或右边的手牌;
推不同面额的筹码;
拉回不同面额的筹码。
论文总共采集了1,470条真实世界的遥操作demonstration。14个primitive各自对应105条演示数据,其中100条被用于训练,另外5条被用于验证。
机器人硬件由UR10e机械臂以及Shadow Dexterous Hand构成。也就是说,它并不是普通的二指夹爪,而是一套具备多自由度的灵巧手系统。
policy 的输入由三个 RGB-D 视角构成,分别是俯视视角、第三人称视角以及腕部相机视角,同时还包括机器人自身的关节状态。输出则对应机器人在下一阶段需要执行的关节位置 action chunk。
论文 Figure 4 很适合放在这里。它展示了 view cards、show cards、push chip、pull chip 等操作的成功案例以及失败案例。这里可以重点强调一个直观感受:这些动作在人看来虽然很简单,但对灵巧手来说却并不简单。拿牌、亮牌、推筹码以及拉筹码,都涉及非常细致的接触控制。机器人并不是“碰到物体”就算完成任务,而是要在不破坏桌面状态的前提下把动作完成。
一个非常关键的指标在于:任务虽然成功完成了,但当前桌面状态是否仍然能够继续支撑后续操作?
这篇论文一个很有意思的地方在于,它并没有仅仅选用常规的success rate。
作者将每一次物理执行的结果划分为四种类型:
SP:Scene-Preserving Success 表示任务已经完成,并且桌面状态仍然保持整洁,因此可以继续开展后续操作。
DC:Disruptive Completion 表示任务虽然已经完成,但桌面状态受到了扰乱,因此后续流程可能无法继续开展。
TF:Task Failure 表示任务未能完成,但桌面状态仍相对稳定,因此还可以继续重试。
DF:Disruptive Failure 表示任务未能完成,而且环境已经受到破坏,因此需要进行重置。
这个划分非常重要。

因为在真实机器人系统当中,完成当前动作并不等同于真正取得成功。
例如,机器人虽然成功把筹码推入了下注区,却同时把手牌碰翻,或者将其他筹码扰乱。从单步目标来看,这一动作似乎已经完成;但从完整系统来看,它实际上已经使后续流程无法继续开展。
所以 DexHoldem 引入了两个指标:
其一是 TCR,也就是 task completion rate。只要任务已经完成,那么就会被计为完成。
另一个指标是 SPSR,也就是 scene-preserving success rate。只有在任务已经完成、并且桌面状态仍然能够继续使用的情况下,才会被视为真正干净的成功。
这一指标实际上比常规的success rate更贴近真实部署场景当中的需求。
因为真实机器人并不是为了拍出一段成功视频,而是需要连续、稳定且可恢复地把任务持续完成。

实验结果:最好的 policy 也远远不稳
在低层policy benchmark当中,论文对多个模型开展了比较,其中包括π0.5、π0、RDT、DP、ACT以及BAKU等。
结果显示,π0.5 的 TCR 最高,达到 61.2%。这意味着,如果仅从任务是否已经完成这一点来看,π0.5 的整体表现最好。
但如果转而考察更为严格的SPSR,也就是既完成了任务、又没有破坏桌面状态这一指标,那么π0.5以及π0都达到了47.5%。

这里建议插入论文 Table 1。这个表格之所以十分关键,是因为它能够清楚地展示不同policy对应的SP、DC、TF、DF,以及最终得到的SPSR和TCR。
可以看到,π0.5 的 TCR 达到 61.2%,但 SPSR 仅有 47.5%。这说明其中有相当一部分动作虽然已经完成,但会对桌面状态造成扰乱。RDT 同样呈现出类似情况,TCR 为 46.2%,但 SPSR 仅有 30.0%。
这正是 DexHoldem 想强调的问题:
机器人并不是只要“做到了”就可以,更关键的是还要“做得干净”。
对于长程任务而言,一次不够干净的动作,往往会使后续的感知、决策以及执行环节全部变得更加困难。
预训练虽然能够带来帮助,但并不能直接解决灵巧操作问题
论文还进一步分析了一个问题:
对于 DexHoldem 这类真实灵巧手任务而言,大规模预训练 policy 的确能够带来帮助,但这种帮助并不会直接转化为对任务难点的彻底解决。
从结果来看,π0.5以及π0这类经过预训练的VLA policy,确实显著领先于许多从零开始训练或者规模相对更小的imitation policy。这说明,大规模机器人预训练对于真实桌面操作而言,的确能够带来帮助。
论文 Figure 5 很适合用来说明这一结论。横轴对应的是 policy pretraining data scale,纵轴对应的是 task completion rate,而点的大小则表示 policy 的参数量。可以看到,π0 以及 π0.5 位于右上区域,这说明更大规模的预训练数据以及更大的模型规模,确实带来了更好的物理执行效果。
但这个图也说明了另一个问题:
预训练不是万能的。
即使是当前表现最好的 π0.5,其 TCR 也仅为 61.2%,而 SPSR 也仅为 47.5%。这意味着,大规模预训练虽然能够把整体性能进一步推高,但仍然没有让真实灵巧手操作达到可稳定部署的水平。
论文还借助RDT开展了一项关于fine-tuning数据规模的scaling study,用来比较随机初始化以及gripper-pretrained initialization在不同数据量条件下各自的表现。
Figure 3 展示了一个很有意思的结果:随着 DexHoldem-specific 数据量的增加,validation loss 会持续下降;但 gripper-pretrained 初始化并没有在低数据量条件下带来质变。也就是说,gripper 场景中的预训练对于 ShadowHand 这类灵巧手任务能够提供一定的初始化帮助,但并不能直接解决少样本灵巧操作问题。
这也很符合直觉。
尽管二指夹爪和多指灵巧手都属于机器人操作范畴,但二者在接触模式、动作空间以及控制难度方面存在很大差异。要把在 gripper 上学到的能力迁移到 ShadowHand 之上,并不是一件会自然发生的事情。
第二层:agent 看得懂牌桌吗?
低层 policy 解决的是“手怎么动”的问题。
但对于一个完整的 embodied agent 而言,仍然需要进一步解决另一个问题:
它能不能看懂当前牌桌状态?

DexHoldem 进一步设计了一个 agentic perception benchmark,其中共包含 36 个来自真实部署过程的牌桌状态问题。模型需要依赖当前图像以及此前的历史状态,进而恢复出结构化的游戏状态。
这些状态字段包括:
当前流程阶段;
现在轮到谁;
大小盲位置;
公共牌;
当前下注;
机器人筹码状态;
对手筹码状态;

摊牌结果。
这部分和普通 VQA 不太一样。
常规 VQA 往往只会提出诸如“图中有几张牌?”或者“筹码呈现出什么颜色?”之类的问题。
但 DexHoldem 真正关心的问题在于:模型是否能够把视觉信息进一步转化为后续机器人决策所真正需要的状态变量。
例如,如果模型对当前下注金额产生了误判,那么 agent 就可能进一步作出错误的 call 或 raise 决策。
如果模型对对手的筹码状态产生误读,系统就可能持续处于等待状态,或者对当前所处的游戏阶段作出错误判断。
如果模型错误识别了当前究竟轮到哪一方行动,那么机器人就可能在本不应当执行动作的时候发生误操作。
因此,这里所考察的并不是“看图说话”式的识别能力,而是视觉状态恢复这一环节是否能够真正支撑后续的动作路由。
Frontier VLM 也会在完整状态恢复上出错
论文测试了多个前沿多模态模型。

结果相当有意思:GPT 5.5 在平均 field-wise accuracy 这一指标上的表现最高,达到了 66.8%;但如果进一步要求同一问题当中的所有相关字段都完全正确,那么 Opus 4.7 在 strict problem-level accuracy 这一指标上的表现最高,不过也仅有 34.3%。
这里建议插入论文 Table 2。这个表格很适合用来说明“单字段准确”以及“完整状态恢复”这两类指标之间所存在的差距。
可以看到,模型在某些字段上的表现仍然相对不错,例如blind information这类较为显眼的信息,许多模型都能够达到较高的准确率。但在current bet chips、robot chip inventory以及opponent chip inventory这类更细粒度的筹码状态方面,模型的表现则明显更差。
这说明当前的VLM并不是完全无法理解牌桌状态,而是在某些关键字段的判断上很容易出现错误。
对于普通的图像问答任务而言,某一个字段出现错误,可能只是意味着答案还不够完整;但对于真实机器人的闭环系统来说,只要有一个字段发生误判,就可能进一步导致后续的动作选择出现错误。
这也是 DexHoldem 很有价值的地方:
它并不是停留在“模型是否能够描述图片”这一层面,而是进一步追问:
这种视觉理解结果,是否能够真正支撑机器人继续开展后续操作?
第三层:完整系统怎么闭环运行?
在具备低层policy以及高层感知能力之后,DexHoldem还进一步搭建起了一个完整的系统级闭环。
这个系统可以简单理解为:
系统在运行过程当中,会先对当前桌面进行拍摄,随后解析出结构化状态,并对游戏记忆进行更新;在此基础之上,由router判断当前应当执行什么操作,接着调用对应的低层policy,由机器人完成执行,最后再次对桌面开展观察。
论文 Figure 2 是理解系统闭环的关键图。
它展示了 agent 在单次决策过程当中的具体工作方式:系统会先对桌面状态进行感知,随后加载并更新 game-state memory,再借助 reasoning checks 对当前状态作出判断,最后在场景保持稳定且确实需要执行 primitive 的情况下,调用 dexterous policy。
Figure 2 当中的例子对应的是 view left card。系统在发现左侧手牌仍然未知、机器人处于 idle 状态且桌面保持稳定之后,便会选择 “View Left Card”。随后,这一高层动作会被进一步转化为一组低层动作序列:
pick_up_left 会先对左侧目标开展感知,随后再将其放回左侧位置。
也就是说,agent所作出的一个高层决策,实际上会被进一步拆解成多个低层灵巧操作。
这一设计之所以十分关键,是因为 DexHoldem 并不是让某一个大模型以端到端的方式直接输出机器人的关节动作,而是选用了模块化的闭环架构:
高层 agent 负责理解和决策;
router 负责流程控制和安全判断;
低层 policy 负责真实物理执行。
这种系统设计与真实机器人的部署形态十分接近。在真实世界当中,机器人不仅需要知道“应该做什么”,还需要知道在什么情况下不应动作、在什么情况下应当等待、在什么情况下需要重试,以及在什么情况下应当请求人类提供帮助。
系统级评估:真正的困难在于错误的持续累积
论文还进一步开展了三个完整的 hand-level case study,也就是让整套系统在真实牌桌环境当中运行完整流程。
需要指出的是,作者也明确说明,这些结果属于case study,并不构成具有大规模统计意义的完整成功率评估。它们的主要价值,在于把真实闭环部署过程当中可能出现的问题具体展示出来。
这里可以插入论文 Table 3。该表对三个系统级轨迹当中的captured states、agent primitives、dexterous-policy primitives、wait-branch events、human-help requests以及recovery dispatches开展了统计。
这些数字实际上揭示了一个非常真实的问题:
完整系统并不是“完成一个动作就宣告结束”,而是需要在持续的等待、验证、推进、恢复以及重试过程中不断运行。
来源:DexHoldem:让机器人打德州扑克,真正难的不是赢牌,而是别把桌子搞乱 | 具身研习社