

出品:机器人技术笔记
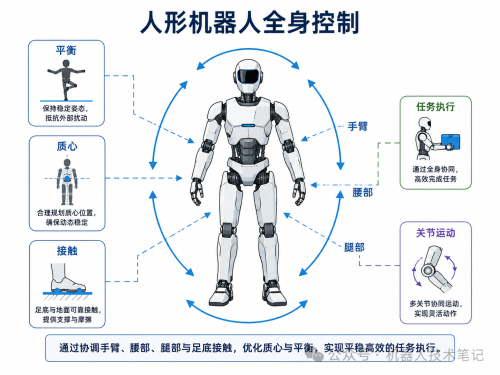
人形机器人做一个搬箱子的动作,看起来只是弯腰、伸手、抓住、起身。但对控制系统来说,这不是一个简单的机械臂轨迹问题。机器人一弯腰,身体重心会变;手臂一伸出去,脚底受力会变;箱子一拿起来,整机质量分布又变了。腿、腰、手臂、脚底接触、电机力矩和身体姿态,都在同一时刻互相影响。
所以人形机器人动作从僵硬到丝滑,本质上不是单个关节轨迹变平滑了,而是机器人越来越会协调全身。
这就是全身控制(Whole-Body Control, WBC)要解决的问题:把机器人当成一个完整身体,而不是一堆分开的电机和连杆。

从技术路线看,人形机器人全身控制大致经历了几个重要阶段:ZMP 先解决稳定行走,HQP 进一步把全身动力学和任务优先级纳入求解,强化学习用神经网络策略替代大量手工调参,而最新趋势则是走向运动基础模型与可组合全身控制。
一、ZMP:先让机器人稳稳站住
人形机器人最早面对的问题很朴素:走路时不要倒。
ZMP(Zero Moment Point,零力矩点)就是围绕这个问题发展出来的经典概念。简单理解,机器人脚踩在地面上时,地面对机器人会产生支撑力。这个支撑力等效作用的位置,如果一直落在脚底支撑区域内,机器人就更容易保持稳定;如果跑到脚外面,就有翻倒风险。
这有点像人在走路时判断重心有没有压出脚底范围。只不过机器人不能靠本能调整,它需要把这个稳定边界明确算出来。
在早期人形机器人里,ZMP 的作用很大。控制器会先规划脚步、重心轨迹和身体姿态,再检查 ZMP 是否落在安全区域内。只要步子别迈太大、身体别晃太猛、重心变化别太激进,机器人就能比较稳定地走起来。

从控制思想上看,ZMP 更接近一种准静态或者简化动力学下的稳定性求解。
它并不是完全不考虑动态效应,而是会把复杂的人形机器人运动问题简化成更容易处理的模型,比如倒立摆模型、质心轨迹和脚底支撑区域。这样做的好处是工程上更清楚,计算也更可控。机器人为什么不稳,往往可以从重心轨迹、脚底支撑区域和 ZMP 位置里找到原因。
但这种方法的限制也很明显。
它更适合平地、低速、接触状态明确的行走任务。机器人如果要快速转身、跑跳、上下台阶,或者上半身做大幅度操作,单靠 ZMP 就会显得保守。为了稳定,机器人常常会走得小心翼翼,动作像在按剧本移动。
所以 ZMP 阶段解决的是全身控制的第一层问题:先让机器人别摔倒。
但只是不摔,还谈不上丝滑。
二、HQP:从准静态稳定走向动态全身求解
当人形机器人不只是走路,而是要边走边操作,控制问题就变复杂了。
比如机器人要把桌上的箱子搬起来,它同时要满足很多目标:身体不能倒,手要够到箱子,关节不能超过限位,电机力矩不能超出能力范围。更麻烦的是,这些目标之间可能互相冲突。
这时候就需要 HQP(Hierarchical Quadratic Programming,层级二次规划)。
如果说 ZMP 更像是在简化模型下判断稳定边界,那么 HQP 更进一步,它通常会把机器人全身的加速度、接触力、关节力矩和任务目标放进同一个优化问题里求解。
这就是从准静态思路走向动态求解。
机器人不再只是关心重心在哪里,它开始进一步关心:在当前接触状态、关节状态和动力学约束下,我的全身关节加速度应该怎么分配?脚底接触力应该怎么分配?哪些任务必须优先满足?哪些任务可以在不影响安全的前提下尽量完成?
HQP 的核心思想不是让所有任务平等竞争,而是把任务分层。最高优先级通常是物理和安全约束,比如接触不能滑、关节不能超限、力矩不能超限;中间层是平衡、质心和身体姿态;更低层才是手部轨迹、冗余姿态和动作美观。
它很像一个工程调度系统。
如果所有目标都能满足,那当然最好;如果不能同时满足,就先保证机器人安全,再保证平衡,再尽量完成操作任务,最后才考虑姿态是不是好看。

HQP 的价值在于,它让机器人真正开始进行全身协作。
机械臂够不到目标时,腰可以自然前倾一点;上半身转动时,腿部可以补偿身体姿态;手在操作物体时,脚底接触力也可以一起被纳入优化。很多人形机器人从僵硬变得有整体感,背后就离不开这类模型驱动的全身优化控制。
但 HQP 的工程代价也很明显。
它依赖比较准确的机器人模型,包括质量、惯量、关节限制、接触状态和执行器能力。模型不准时,优化器算出来的动作在仿真里很好,真机上可能会出现抖动、延迟或者接触异常。
更麻烦的是复杂任务下的调参工作量。HQP 不是把任务写进去就自动变丝滑。每一层任务的权重、优先级、约束松弛、滤波参数、接触切换逻辑,都需要工程师反复调。走路是一套参数,搬运可能又是一套参数;平地可用,上台阶可能还要改;空手动作稳定,拿了重物以后又要重新检查接触力和力矩限制。
所以 HQP 阶段解决的是第二层问题:机器人不仅要站稳,还要在动力学约束下协调全身。
但它仍然高度依赖工程师对任务的建模、分层和调参。
三、强化学习:让机器人从仿真中学会动态调整
到了更复杂的场景与动作,很多细节就很难完全靠人工写规则。
脚底轻微打滑时怎么补偿?被人推一下后怎么恢复?落地瞬间膝盖应该怎样吸收冲击?高速转身时,手臂和腰部应该怎么配合?这些问题如果全部写成规则,会非常复杂,而且很容易只适用于某一种场景。
强化学习(Reinforcement Learning, RL)就是在这个背景下变得越来越重要。它的思路是让机器人在仿真环境里大量试错。控制器观察机器人状态,比如关节角、关节速度、身体姿态、足底接触和目标指令,然后输出动作。训练时,奖励函数会鼓励机器人完成任务、保持平衡、减少能耗、动作平滑,并避免摔倒。
更关键的是,强化学习用神经网络拟合控制策略,替代了过去大量依赖人工设置规则的部分。
工程师不再直接写出每一个状态下机器人应该怎么动,而是设计训练环境、动作空间和奖励函数,让神经网络自己去拟合状态到动作的映射。这个策略网络学到的不是某一个固定轨迹,而是一种条件反射式的控制能力:看到当前身体状态和目标指令,直接输出下一步应该怎么动。

这让机器人可以做的动作范围大大增加。
过去很难手写的跑、跳、快速转身、抗推扰动、复杂地形行走,现在可以通过仿真训练探索出来。尤其在人形机器人上,很多看起来更自然、更有弹性的动作,并不是靠工程师逐帧设计出来的,而是策略在大量试错中学出来的。
传统控制器通常会为了安全变得保守,像是在小心翼翼地走。强化学习策略如果训练得好,可以更充分地利用机器人的动力学特性。它不是每一瞬间都追求静态安全,而是在动态过程中不断恢复平衡。
但强化学习也不是一招解决所有问题。
首先是奖励函数难调。你奖励速度,机器人可能学出奇怪姿态;你奖励平滑,它可能变得太慢;你奖励节能,它可能不愿意完成任务。奖励函数本质上是在告诉机器人什么是好动作,但这个好字很难一次写对。
其次是 sim-to-real。仿真里的摩擦、关节延迟、电机饱和、结构弹性,很难和真实机器人完全一致。策略在仿真里跑得很漂亮,不代表上真机一定稳定。
还有一个更大的问题是泛化。
很多强化学习策略在一个任务上很强,但换一个任务就要重新设计奖励、重新训练、重新调参。会走路,不代表自然会搬箱子;会搬箱子,不代表会开门;会开门,也不代表会一边走一边开门。
所以强化学习阶段解决的是第三层问题:用学习出来的策略替代大量手写控制逻辑,让机器人具备更强的动态适应能力,也让可实现的动作空间明显变大。
但如果每个任务都要单独训练,机器人仍然很难真正走向通用。
四、运动基础模型与可组合全身控制:不再每个任务从零开始
最近一个很重要的趋势,是人形机器人控制开始从单任务策略,走向运动基础模型与可组合全身控制。
所谓运动基础模型,可以理解成给机器人训练一个运动底座。这个底座不是只会一个动作,而是从大量人类动作、机器人动作、仿真数据和真实数据中,学习一套可复用的全身运动能力。
过去的控制器更像一个个专用技能包:走路一个策略,跳跃一个策略,避障一个策略,搬箱子一个策略。每加一个任务,都要重新调奖励、重新训练、重新验证真机安全性。
而运动基础模型想做的是:先让机器人学会身体如何运动,再让上层任务去调用这些运动能力。
比如机器人已经学会了前进、转身、下蹲、伸手、保持平衡、避障这些基础能力。新任务来了以后,不一定要从零训练,而是把已有能力组合起来。搬箱子时,它可以组合行走、下蹲、伸手、抓取和起身;开门时,它可以组合靠近、转身、伸手、保持身体稳定和拉门动作。
这就是可组合全身控制的核心。
机器人不再只是执行一条固定轨迹,而是在已有运动能力中选择、调整和组合。上层告诉它要做什么,底层负责生成物理上可执行的全身动作。

BeyondMimic 就是这个方向的代表之一。它不只是让机器人模仿一段人类动作,而是希望从大量人类运动中学习更通用、更自然的人形控制能力。它强调的一个关键点,就是不要为每个任务都单独训练和调参,而是通过统一策略和测试时的任务引导,把已有运动能力复用到不同任务中。
这个趋势很重要。
因为强化学习虽然已经减少了很多手工控制逻辑,但如果每个任务都要重新设计奖励、重新训练策略、重新调 sim-to-real 参数,那工程成本依然很高。运动基础模型想进一步解决的是复用问题:让机器人把过去学过的运动经验沉淀下来,面对新任务时可以组合已有能力,而不是从零开始。
这也是动作越来越丝滑的更深层原因。
丝滑不是简单给轨迹加滤波,也不是把关节曲线画得更圆滑。真正的丝滑,是机器人知道什么时候该用脚补偿,什么时候该转腰,什么时候该降低重心,什么时候手臂要慢一点,什么时候又可以利用身体惯性。
它看起来像动作自然,本质上是全身协调能力更强。
丝滑的背后,是机器人越来越像一个完整身体
人形机器人全身控制的发展,其实是在不断回答同一个问题:机器人怎样才能像一个完整身体一样运动?
ZMP 先用准静态或者简化模型的方式,把稳定性问题变得可计算,让机器人能够稳稳走起来。
HQP 进一步进入动态全身求解,把加速度、接触力、关节力矩和任务优先级放到同一个优化框架里,让腿、腰、手臂和脚底接触能够协同工作。
强化学习则用神经网络策略拟合复杂的状态到动作映射,减少过去大量手工调参和规则设计,让机器人可以学会更复杂、更有弹性的动作。
运动基础模型与可组合全身控制,则在回答更长期的问题:机器人能不能把学过的运动能力复用起来,面对新任务时不再从零开始?

从这个角度看,所谓丝滑,并不只是动作好看。
它背后代表的是机器人控制从准静态稳定走向动态优化,从手工调参走向学习策略,从单任务训练走向可复用运动能力。











