5月11日,面壁智能联合清华大学及 OpenBMB 开源社区,正式发布新一代端侧多模态大模型 MiniCPM-V4.6。这款仅拥有1.3B 参数的“轻量级”模型,凭借极致的智能密度与跨平台适配能力,成功挑战了更大参数模型的性能天花板,为端侧 AI 的落地应用按下了“加速键”。

一、性能巅峰:1.3B 参数下的“越级表现”
MiniCPM-V4.6推出了 Instruct 与 Thinking 两个版本,在多项评测中展现出同量级模型难以企及的推理与理解能力:
-
全球领跑: 在 Artificial Analysis(AA)榜单中,MiniCPM-V4.6以 13分 的优异成绩,不仅大幅领先同尺寸竞品(如阿里 Qwen3.5-0.8B 和谷歌 Gemma4-E2B-it),性能更直逼更大参数的 Qwen3.5-2B,成为1B 级模型中的性能标杆。
-
高阶能力: 无论是通用图文理解、复杂的 STEM 数理推理,还是极具挑战的文档 OCR 与视频时序理解,模型表现均表现出极高的智能水准。特别是在多图像推理与幻觉抑制方面,Thinking 版表现尤为出色。
二、效率革命:极致的端侧“智能密度”
为了解决端侧部署“内存焦虑”,MiniCPM-V4.6在推理速度与资源占用上进行了深度优化:
-
极速门槛: 运行内存需求被压缩至 6GB,使得主流智能手机、PC 及智能家居设备均能流畅运行。
-
推理效率: 基于 vLLM 的推理吞吐量达到竞品的1.5倍;在端侧处理3136² 超高清大图时,首响延迟仅 75.7ms,较竞品快出2.2倍。
-
吞吐能力: 单卡即可实现7013token/s 的文本生成能力,以及54.79张/秒的1344² 图片处理能力,效率表现惊人。
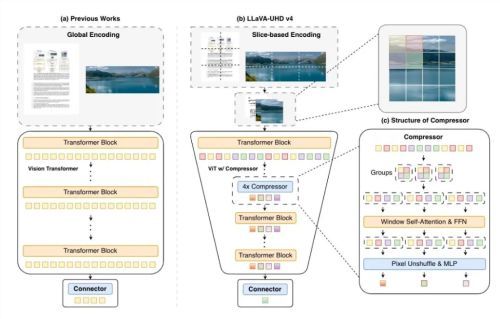
三、技术硬核:LLaVA-UHD v4带来的开销缩减
模型之所以能“轻装上阵”,离不开面壁智能与清华大学联合研发的 LLaVA-UHD v4 技术:
-
编码重构: 通过重构 ViT 图像编码与浅层压缩模块,图像编码开销降低了 50%,高分辨率浮点运算减少 55.8%。
-
混合压缩机制: 创新支持4倍/16倍混合 Token 压缩,支持模型在“性能优先”与“速度优先”之间灵活切换,该技术此前已在快手的推荐大模型 OneRec 中经过验证,支撑了海量流量请求。
四、生态落地:从实验室走向产业一线
MiniCPM-V4.6的开源不仅是技术的胜利,更是生态的胜利:
-
开发便捷: 深度适配 ms-swift、LLaMA-Factory 等微调框架,开发者单张 RTX4090显卡即可实现全量微调。
-
全平台兼容: 支持 vLLM、Ollama 等主流框架,并提供覆盖 iOS、Android、HarmonyOS 的测试版本,让 AI 触达更多形态的硬件终端。
-
落地赋能: 目前该系列已在汽车、PC、智能家居及工业检测等多领域落地,合作伙伴涵盖联想、吉利、上汽大众、小米、OPPO 等行业头部企业。
随着 MiniCPM-V4.6的全面开源,端侧多模态大模型的门槛已被彻底拉平。未来,AI 将不再仅仅依赖云端算力,而是真正融入每一个智能终端,成为个人日常生活中不可或缺的“智慧大脑”。