出品:深蓝具身智能
今年2月,我们曾盘点过国内具身智能企业估值Top 10。
仅仅过去两个月,赛道热度再上台阶,企业估值与榜单位次也发生了明显变化,百亿俱乐部持续扩容,同时头部阵营愈发稳固。
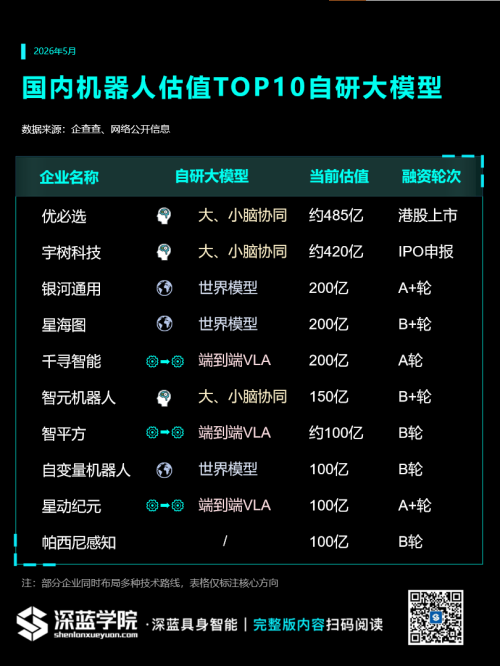
据今年 Q1 最新数据来看,赛道价值持续抬升,已有 7 家企业估值跻身百亿门槛。资本加码的同时,也反向倒逼各家加快技术落地,融资节奏与大模型、具身模型的迭代进度深度绑定、步调趋同。
为此,我们基于截至4月的估值情况,对Top 10企业进行重新梳理,并首次系统拆解它们各自的“大脑”选型:
是采用「大小脑协同」的分层架构,由LLM负责高层推理与规划、传统控制系统执行底层动作?还是走向「端到端VLA」模型,让视觉-语言-动作一体输出?抑或押注「世界模型」,试图让机器人在物理仿真中自我演化决策?
估值排位洗牌的背后,本质是各家技术路线与模型架构的实力比拼。这三条路径,Top 10各自落子在何处?我们逐一拆解。
01
10家独角兽的大模型路线图
根据2026年3月至4月披露的最新融资与估值数据,“百亿”成为了第一梯队的新门槛。

注:所有信息均参考企业官方披露及行业公开数据。部分未明确披露估值但融资金额巨大的企业(如逐际动力2亿美元B轮)未列入前十,但在技术路线上同样具有代表性,后文将展开介绍。
同时在这份榜单中,我们可以清晰地看到行业共识已经从"投机器人硬件公司"转向了"投具身大脑公司"。
宇树科技在招股书中明确披露,拟募资的42亿元中超过20亿元将专项投入"智能机器人模型研发项目",占募资总额近一半。
如此高比例向模型研发倾斜,放在几年前并不多见。
这也在一定程度上说明了“硬件决定了机器人的下限,大模型决定了机器人的上限”。
总体来看,当前行业主要分为三大流派:
端到端VLA「激进派」、大小脑协同「务实派」,以及世界模型「前瞻派」。
当然,技术路线本没有谁更好之分,不同的选择背后,是企业对产品落地节奏、成本控制与长期技术壁垒的不同权衡。

▲图 | 技术路线对比(代表企业排名不分先后)©【深蓝具身智能】
下面我们依次来看各大模型的特点。
02
激进派:全面拥抱端到端VLA
智平方(AI² Robotics):全域全身VLA
VLA的作用价值不必再过多赘述,但端到端VLA意味着更高的数据需求和更难解释的决策过程,这条路并不好走。
智平方是全球最早专注VLA自研的创业公司之一,其核心基座模型GOVLA实现了一个关键突破:
常规VLA模型通常仅输出机械臂动作,而GOVLA首次提出统一输出"全身控制和移动轨迹",实现了360°全域感知和全身协同控制。
其开源版本FiS-VLA采用了"异构输入+异步频率"的双系统架构,将负责全身控制的"快系统"嵌入负责复杂推理的"慢系统",在权威评测中综合性能超越了π0达30%。

▲图 | 国产具身大模型首次获得汽车制造全场景验证:智平方机器人进驻东风柳汽工厂,GOVLA模型直接驱动全身运动,无需分模块调度。©【深蓝具身智能】编译
千寻智能(TuringQ):开源生态定义者
千寻智能的Spirit v1.5模型在2026年1月开源后,迅速登顶了全球具身智能模型评测平台RoboChallenge。
该模型采用统一的VLA建模框架,还通过自研的可穿戴式数采设备,将真实数据的采集成本降至传统方式的十分之一,试图用"低成本数据+高性能模型"的双轮驱动来建立壁垒。

▲图 | 千寻智能Spirit v1.5在全球具身智能模型评测平台RoboChallenge上综合评测斩获第一,超越了此前领跑的Pi0.5,被业界称为具身智能的"DeepSeek时刻"。©【深蓝具身智能】编译
星动纪元(RoboTera):全身控制与世界模型的融合
清华系背景的星动纪元,其端到端VLA具身大模型ERA-42据官方透露,是全球仅有4家实现全尺寸双足人形机器人全身及五指灵巧手精准控制的系统之一。
ERA-42已跨平台落地于轮式服务机器人、双足人形机器人等多种形态,并与清华、斯坦福联合研发的可控生成世界模型"Ctrl-World"协同,进一步提升了在未见场景中的泛化能力。

▲图 | 星动纪元携人形机器人家族亮相CES 2026,ERA-42端到端VLA具身大脑已实现跨平台部署,覆盖轮式服务机器人与双足人形机器人多种形态。©【深蓝具身智能】编译
03
务实派:大小脑协同与场景深度优化
这一流派认为,在当前技术条件下,完全的端到端仍存在"黑盒"和安全性问题。
因此,采用视觉语言大模型(VLM)作为"大脑"负责高级认知和决策,结合强化学习(RL)或模型预测控制(MPC)作为"小脑"负责底层运动控制,是更务实、更易落地的方案。
智元机器人(Agibot):具身基座模型与"一体三智"
智元机器人在2026年APC合作伙伴大会上提出了"一体三智"的全栈架构,将机器人的智能分为运动智能(执行)、交互智能(情绪价值)和作业智能(劳动价值)三层。
其大模型体系包括基于ViLLA架构的通用具身基座模型GO-1,以及2026年初推出的第二代一体化具身大小脑系统GenieReasoner。
2025年营收10.5亿元,2026年3月万台下线,是目前国内出货量最大的人形机器人企业之一。
值得注意的是,智元高层在APC大会上坦言目前"不缺钱,缺数据"——这句话更道出了整个行业的共同困境。

▲图 | 2026年智元合作伙伴大会(APC 2026)在上海举行,智元正式公开AIMA全栈生态技术体系,并首次发布具身智能产业XYZ曲线。会上高层坦言:当前阶段"不缺钱,缺数据"。©【深蓝具身智能】编译
逐际动力(LimX Dynamics):Agentic OS与通用基座
逐际动力在2026年初发布了面向物理世界原生的具身Agentic OS系统——LimX COSA。
其核心技术突破在于"小脑基础模型":一种能够实时生成全身运动指令的模型,突破了传统预编程动作的限制。
大脑想要什么动作,小脑就能实时执行,这种高阶认知与全身运控的深度融合,为其多形态机器人平台TRON 2提供了强大的支撑。

▲图 | 逐际动力TRON 2多形态具身机器人平台,搭载LimX COSA系统,支持轮式、双足等多种运动形态切换,小脑基础模型可实时生成全身运动指令,无需预编程动作库。©【深蓝具身智能】编译
优必选(UBTECH):工业场景的深度淬炼
作为"人形机器人第一股",优必选的具身智能大模型Thinker更侧重于工业场景的深度优化。
Thinker具备开箱可用的视觉语义理解能力,配套的Thinker-VLA负责闭环反馈的视觉语言动作控制,Thinker-WM则是面向工业具身智能的世界模型。
2025年,优必选全尺寸人形机器人Walker S系列在汽车制造、3C电子等场景实现了规模化交付,全年销量1079台,收入8.21亿元,同比增长2203%。

▲图 | 优必选第1000台工业人形机器人Walker S下线,Thinker大模型体系(含Thinker-VLA与Thinker-WM)支撑其在汽车制造、3C电子等工业场景的规模化部署。©【深蓝具身智能】编译
宇树科技(Unitree):运动控制王者向"大脑"冲锋
以四足机器人和极致硬件降本能力著称的宇树科技,正在全力补齐大模型短板。
其招股书显示,拟募资的42亿元中超过20亿元将投入"智能机器人模型研发项目",重点用于具身大模型与机器人大脑的研发。
目前,宇树已开源了UnifoLM-WMA-0(世界模型架构)和UnifoLM-VLA-0(视觉-语言-动作)两个模型,并计划在3年内打造通用人形机器人具身基础模型,实现场景、指令、动作、任务四大维度的泛化提升。

▲图 | 宇树科技开源UnifoLM-VLA-0,同期还开源了世界模型架构UnifoLM-WMA-0,标志着这家以运动控制见长的企业正式向"具身大脑"方向全力转型。©【深蓝具身智能】编译
04
前瞻派:引入世界模型与仿真数据
物理世界的数据稀缺是制约具身智能发展的最大瓶颈。前瞻派企业试图通过引入"世界模型"理解物理规律,或利用仿真环境生成海量数据,来打破这一僵局。
银河通用(Galbot):仿真数据路线的破局者
银河通用选择了一条差异化的路径:"仿真合成数据预训练+真实数据对齐"。
其核心大模型体系为银河星脑(AstraBrain),其中联合北京智源、香港大学等机构发布的GraspVLA,是全球首个预训练完全基于仿真合成大数据的端到端具身抓取基础大模型,预训练数据达到十亿帧级别。
通过在仿真环境中大规模生成训练数据,银河通用不仅大幅降低了数据采集成本,还实现了对光照、干扰物的零样本真机泛化,真实抓取成功率显著超越了OpenVLA与Octo等主流大模型。

▲图 | 银河通用发布全球首个预训练完全基于仿真合成数据的端到端具身抓取基础大模型GraspVLA,预训练数据达十亿帧,在光照变化、干扰物等场景下实现零样本真机泛化。©【深蓝具身智能】编译
星海图(Xinghai Dynamics):真实数据与快慢双系统
星海图坚持真实数据路线,其核心模型G0 Plus采用了"快-慢双系统"架构,将VLA模型与世界模型深度结合。
G0 VLA大模型于2025年8月开源后,突破了当时行业最优水平;2026年1月推出的G0 Plus进一步实现了零样本泛化,让机器人"即看即会"。
星海图认为,真实世界物理规律的精确建模是仿真难以完全复现的,通过开发者生态的快速积累,正试图在真实数据规模上实现数量级的跃升。

▲图 | 星海图G0 Plus VLA模型展示零样本泛化能力,采用"快-慢双系统"架构将VLA与世界模型深度结合,机器人可在未见过的物体和场景中直接完成抓取任务,"即看即会"。©【深蓝具身智能】编译
自变量机器人(X Square):原生多模态与家庭场景
自变量机器人的WALL-A(及后续的WALL-B)模型是基于世界统一模型架构(WUM)的具身智能基础模型,率先实现了具身多模态思维链,利用世界模型机制进行时空状态预测。
2026年初,自变量与58到家达成合作,并于4月将搭载WALL-B模型的机器人送入真实家庭,实现了全球首次机器人进入家庭并服务人类复杂家居生活的落地。
这是迄今为止最接近"家庭机器人"商业化的一次尝试,但能否规模复制,仍有待观察。

▲图 | 自变量机器人发布WALL-B,基于世界统一模型架构(WUM)实现具身多模态思维链,并首次将机器人送入真实家庭进行复杂家居服务,是迄今最接近"家庭机器人"商业化的落地尝试。©【深蓝具身智能】编译
05
重估之后,冷静入场
回看今年以来的榜单变迁,百亿俱乐部门槛的抬升,本质上也是一场“大脑”价值的重估。
但估值排名也只是暂时的资本投票,模型选择没有绝对的标准答案,也不存在唯一的最优解。
用大模型拉开产业竞争的价值上限,已然成为行业共识。
但我们同样需要冷静地看到:技术路线没有“皇冠上的明珠”。
端到端VLA的“激进派”追求极简与泛化,却面临数据饥渴与可解释性难题;
大小脑协同的“务实派”率先落地商用,但分层架构的延迟与割裂始终存在;
世界模型的“前瞻派”深耕物理仿真与智能自进化方向,距离规模部署仍有相当距离。
不同路径,对应的是不同企业对商业化节奏、资金厚度与长期壁垒的差异化权衡。
硬件决定下限,模型决定上限,而真正决定一家企业能走多远的,是上限与下限之间那个可持续迭代的产品闭环。
未来具身智能的行业格局,终将由技术落地能力而非概念叙事定义,路线之争仍会持续演进,真正能穿越周期的,永远是兼具技术深耕与商业落地实力的玩家。