作者:Marilyn Liu 出品:具身纪元
26年4月,涌现了非常多具身的基础模型。4 月以来的半个多月里,四个具身基础模型接连发布,分别是 4 月 2 日 Generalist 的 GEN-1、4 月 14 日 BeingBeyond 的 Being-H0.7,4 月 16 日 Physical Intelligence 的 π0.7、以及 4 月 17 日 NVIDIA 的 GR00T N1.7。
就如 Generalist 最新博文标题一样,超越 VLA 和世界模型,具身的基础模型,已然慢慢超越了 VLA 和世界模型的划分。
这里发出一个暴论:2026年会是具身原生模型时代的元年
先行下一个定义,何谓具身原生?就是符合具身自己的数据采集、使用以及模型训练的方式。
具身智能虽然一直在高速发展,但它屡屡无法逃脱“投机者”的诟病,因为它长时间继承了VLM/视频生成模型的先验知识,获得了第一次能力的跃迁。
随后,随着数据量的提升,我们看到了模型在scaling law的驱使下不断“接近智能”。长程、灵巧、鲁棒地demo的不断出现,也振奋着行业。
就此,具身也遇到了它下一个要应对的挑战,如何构建原生的具身模型?
且不说人接受多维模态,输出多维模态,不同模态的信息是紧密耦合在一起的,不仅在当下,还在对未来的预判和闭环反馈。比如在倾倒液体的时候,我们大概知道手腕倾斜角度会多少影响水流粗细和流水的速度,也可以在快到位的时候适时收手。这是一种对物理世界的真正理解。
这样的物理理解很难用单一的视觉、语言或者动作的模态来刻画。
在大语言模型(LLM)中,人类的“文本 Token”就是那个完美的抽象模态——它洗去了声音、口音、字体的物理噪音,纯粹地承载了逻辑与语义。但在具身智能领域,这个统一的、属于物理世界的“抽象模态(语言)”确实尚未完全收敛,整个行业正处于寻找它的“巴别塔时刻”。
具身需要自己的控制元语。
一、数据原生:可泛化的物理交互数据
具身找到了属于自己的数据收集和规模化方式
如果在一年前,我们会把具身的数据金字塔刻画为互联网数据、仿真数据与真机数据。互联网数据脏,不容易学习。仿真sim to real gap 大,而真机又无法scale。
但人类数据,如ego,UMI,如实记录人类日常的操作行为的数据,逐渐流行。具身迎来了,属于它自己的可以规模化的数据来源。
从量级上来说,具身模型的已经渐渐摆脱了昔日的数据饥渴,数据量本身不再成为瓶颈。
GEN-1的基础预训练完全不依赖机器人数据。核心数据来源是低成本UMI设备采集的人类日常活动,数据量也从Gen-0的27万走到了50 万小时。Being-H0.7同时也引入多样化30+跨本体数据”。Being-H 系列上一代 H0.5 利用约 1 万小时人类中心预训练数据,H0.7 直接扩到 20 万小时,15 倍的提升。GR00T N1.7引入了超过 2 万小时的人类操作视频(EgoScale 数据集)作为基座预训练的核心燃料。π0.7也收集了人类第一视角视频,以及互联网的图文和视频。用于训练世界模型组件和强化VLA的backbone。

大量异构数据,各有消化方式
数据源变了,随之而来的是一个更麻烦的问题。如何能够消化大量异构的数据
机器人平台的遥操作轨迹、人类第一视角视频、互联网图文、失败片段混在一起,质量参差、模态各异,怎么消化成能驱动动作的统一表征?
这里面存在隐式和显式两种方式。
Being-H0.7是隐式的代表。
Being-H0.7 在数据量推到 20 万小时后,把对齐目标从动作空间转移到了隐空间,让模型通过训练路径把人类视频里的物理规律吸收进策略,不再需要把人类视频转换成机器人动作标签。
π0.7 走了相反的路。
π0.7的核心洞察是多模态上下文调节(Diverse Context Conditioning)——通过精心设计的prompt结构,把原本会互相干扰的异质数据变成模型可以消歧的训练信号。因此,他们主张通过极其丰富的显式条件注入(Prompting)来驾驭异构信息。
以前的VLA模型,prompt就是一句话:"clean up the kitchen"。π0.7的prompt同时包含四种信息:
世界模型生成视觉子目标图像:展示的是"如果你正确执行了这个子步骤,世界应该长什么样"。语言指令:细致到subtask维度,这意味着模型不需要自己从一句模糊指令中猜测"接下来该做什么",让它在每个时刻都有一个明确的短期目标。Episode元数据:给每条数据打上质量维度:以前训练VLA,大家会仔细过滤数据——只用高质量人类演示,丢掉失败样本和低质量数据,生怕污染模型。π0.7反过来:所有数据全部纳入训练,但给每条episode打上三个元数据标签:总体速度、总体质量、是否犯错控制模态标签:关节空间还是末端执行器。

二、模型原生:超越"VLA 与世界模型"
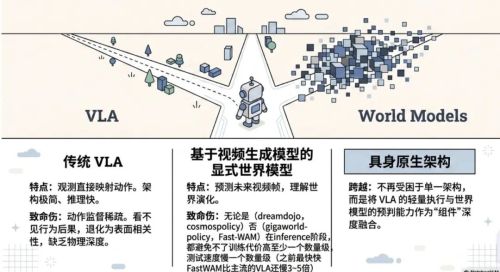
无论是VLA还是世界模型,最初的起步都是具身承接了大模型的low hanging fruit,随着VLM的成熟,具身好像具备了继承互联网泛化常识的能力,VLA随之诞生。
视频生成模型的不断发展,让世界模型的路线又成为了显学。但到VLA和世界模型,是否是真的终极架构?
传统VLA从当前观测映射到动作。架构简洁,推理高效,但问题在于,动作监督是稀疏的、有限的,模型看不到自己的行为会带来什么后果,因此容易退化成依赖表面相关性的行为模式,学不到真正物理扎实的动作表征。
另一支是 WAM(World-Action Models),试图通过预测未来的视频帧来引入对世界演化的理解。这条路理论上很完整,但工程上代价巨大。
Cosmos Policy 训练 LIBERO benchmark 需要超过3000 个 H100 GPU 小时。
更根本的问题在于,像素空间的未来预测本质上是在预测所有视觉信息,包括大量与控制无关的冗余内容,噪声在模块之间传递,误差向下游动作解码积累,在动态任务中尤其致命。
但实际上,这些foundation model,并没有在实际上把自己限制在世界模型和VLA的架构之中,反而是把VLA和世界模型当做组件,为自己的模型所用。
Being-H0.7:把世界模型压进隐空间
Being-H0.7 是一个约 30 亿(3B)参数的隐空间世界-动作模型(Latent World-Action Model)。它的架构从根本上拒绝了生成显式的未来视频或图像帧,希望在保留VLA的轻量的同时,尽可能的保留世界模型的信息。
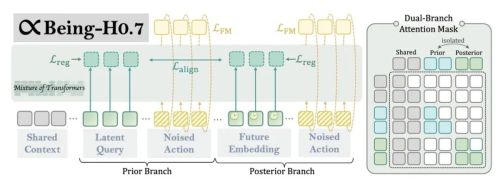
具体的实现可以分为两个核心阶段。
第一步:构建隐式推理缓冲层
首先,在多模态输入序列与最终的动作输出序列之间,模型插入了 16 个可学习的“潜在查询向量”。
这构成了它的隐式推理空间,模型在输出动作前,它让机器人在看清世界之后、真正动手之前,必须先在这个不可见的高维空间里,凝练出一种行动前夕的“物理状态”。
它在网络的逐层传播中,不断与输入的画面、语言指令以及机器人的身体状态进行交互,只把与当前任务高度相关的语义特征吸合并浓缩过来。
这一设计在“感知”与“控制”之间搭建了一座推理缓冲桥梁,使得模型彻底告别了将抽象的多模态语义生硬映射为底层密集动作的窘境。
第二步:引入双分支未来对齐机制然而,仅凭第一步还远远不够。如果只依靠动作监督信号进行学习,这些潜在查询向量极易退化成一个毫无物理深度的浅层特征聚合器,根本无法真正具备“世界模型”的预判能力。
因此,模型在训练时创新性地引入了“双分支”机制,同时运行两条路径:
一条是“先验分支”(即未来实战推理时使用的正式网络),它只能看到当前的观测画面;另一条是“后验分支”(仅在训练阶段存在的“开卷考试”),它能够额外访问未来的视频帧。通过一个被冻结的视觉提取器和重采样器,后验分支将未来的真实画面压缩成 16 个“未来特征向量”,并用它们替换掉原本潜在查询向量的位置。这两条分支共享主干网络和上下文信息,唯独在“隐式推理”位置上的特征参数截然不同。
在训练时,系统会对这两个分支在推理位置的隐藏状态施加一个对齐损失函数(Lalign),强制要求先验分支去逼近、对齐后验分支看完未来画面后形成的状态。
此举的意图极其精妙:后验分支拥有“上帝视角”,清楚未来会发生什么,因此它的隐藏状态中已经编码了对物理世界动态演变极为关键的信息。
这实际上是用海量真实的物理演变规律,一遍遍地去“冲刷”和塑造机器人的潜意识。
这样一来,先验分支在部署时,哪怕不再输入未来画面,也能在隐空间中自发形成对未来物理演变的精准预判。
π0.7:VLA 骨架上长出来的世界感知

π0.7 不要求主模型自己去顿悟物理世界。它通过架构上的解耦,将对未来的想象显式化为真实的像素图像,将对动作好坏的反思显式化为文本标签。
π0.7 的主体依旧是VLA架构,集成了前代模型和其他研究成果。4B参数视觉-语言模型(VLM)主干网络;860M参数的动作专家,保留了实时动作分块(RTC, Real-time action chunking)技术以保证动作的流畅执行。使用知识隔离(Knowledge Insulation)确保动作专家的连续流匹配梯度不干扰 VLM 稳定的语义学习。改用 MEM(Multi-scale Embodied Memory)作为视觉编码器。这是PI团队今年早些时候发表的一个专门为具身智能设计的视频历史编码方案。
以上的架构都是延续了PI之前的研究成果。
除此之外,π0.7 嵌入了一个轻量世界模型组件,为模型提供visual prompt,也是π0.7性能提升的关键。
推理时,这个组件先生成一张视觉子目标图像,展示完成当前子任务后场景应该呈现的状态,再把这张图作为条件输入给控制策略。
整个推理路径是:任务指令--->子任务分解---->生成子目标图像---->输出动作。
子目标图像基于轻量图像生成模块生成,在上下文约束下预测场景的下一个合理状态。加上第一节提到的结构化上下文输入,策略每次推理都能同时掌握任务的全局约束。
除了visual prompt之外,正如前文所说,更详细的语义标注、质量标注都为模型注入了显式的上下文提示。
和 Being-H0.7 相比,同样是给策略注入未来感知,π0.7 走的是显式路:世界模型生成的子目标图像可以被人检查,中间状态清晰;代价是推理路径更长,子目标图像有额外延迟,图像本身也可能出错。

我们可以用一个类比来理解其中的技术分化,一种好像是我们在各种潜在关联中理解并恍然大悟的瞬间,比如突然找到了平衡车上的平衡,一种则是后天刻意的学习,尽可能吸收其中的规则而获得一项技能,例如学习怎么组装家具。
这是同一个目标下的两种选择。
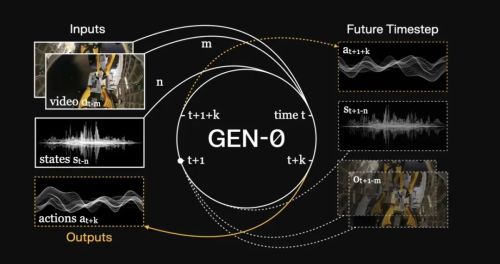
关于GEN-1的推测
根据Generalsit 的博客,GEN-1是 Generalist 对具身基础模型的一次完整重新设计,锚点不在研究范式,而在物理 AGI 这条长线目标上。Generalist 过去一年把 VLA、世界模型等方法都试过一遍,最终没有把任何一种作为 GEN-1 的标签,而是从物理 AGI 的终点出发向前倒推。就如Florence的博客所说目标比方法更有力量。
在为数不多的披露中,我们看到两个关键词,一个是谐波架构,一个是page attention(翻页机制)
在其中我们也可以看到模型会预测多种未来信息,actions,states,observations,也极有可能利用了视频生成模型或者latent world model。
三、统一模型上的物理直觉的涌现
无论是Gen-1,Being-H0.7还有π0.7,都体现在统一模型上涌现出了对真实世界物理规律理解的能力。令人欣喜。
π0.7展示了组合泛化的初步迹象。能把从不同任务里学到的技能重新组合,完成它从未专门训练过的任务,就像人类能把“拿起物体”,“放入容器”,“关上盖子”这几个动作组合成“往空气炸锅里放食材”一样。
π0.7也实现了跨本体的泛化,它虽然从未在 UR5e 双臂机器人上训练过,但在这台陌生机器人上折叠衣物时,零样本成功率和"平均有 375 小时遥操作经验的专家"第一次接触这台机器人时的成功率持平。
Being H0.7涌现出了对物理世界的理解,比如在时间高度敏感的任务中,可以快速滚动的球、用球拍击打/重定向移动物体、向移动的容器中倒水以及在传送带上进行交互。
可以将能力泛化到涉及重力、流体转移(如用移液管或漏斗倒水),可变形物体的接触(如衣物折叠)以及使用工具传递力量(如使用锤子敲击)等复杂物理任务中。这证明它的泛化是建立在物理因果关系之上的。
在真实世界的部署中,Being-H0.7 被成功部署在三种形态截然不同的机器人平台上:PND Adam-U(31个自由度的上半身人形机器人)、Unitree G1(26个自由度的双臂人形机器人)和 Franka FR3(13个自由度的单臂桌面机械臂)。
同一套模型权重和潜在的预测先验,能够在这些自由度、相机视角和运动学结构完全不同的实体之间保持一致的任务完成度
我们看到了在数据规模上升,数据原生以及模型原生驱动下,统一的具身基础模型一再被推高的上限。
四、培育具身原生的模型
回头看这几个模型,它们在技术路径上差异显著,每个团队对所谓具身的元语的定义都是不一样的。
Being-H0.7 押注隐空间世界建模;π0.7 把异构上下文统一成 prompt 接口;GEN-1 则从零构建物理交互原生的大模型系统。
但它们共同离开的那个起点是一样的,再寻找属于具身智能的真正的地基。
具身模型的训练过程,越来越像是在“培育”一种智能,而非在“拟合”一组动作标签。
GEN-1 用 50 万小时人类物理活动数据做预训练,这个流程的隐含假设是,理解物理世界的能力可以从观察人类的日常操作中生长出来。
Being-H0.7 用 20 万小时第一人称视频训练隐空间先验。它赌的是,对未来的预期可以被内化为一种隐式的身体直觉
π0.7 把失败和次优数据都纳入训练。真实世界的数据天然是嘈杂和不完美的,模型需要在这种不完美中学会判断。
所谓培育智能,本质上是培育一种对现实世界有感觉的模型。
这种感觉不来自语言描述,也不来自图文配对,而来自与物理世界的持续且带后果的交互。一个杯子的重量,一块毛巾的柔软与形变,一个硬币掉落后薄且难以捡拾的触感。这些过去被默认在"感知模块"里处理掉的细节,正在被这一代基础模型当作要学的核心内容。
物理因果随着每一次交互而时刻震荡,持续演变,在这样的因果洪流中,模型最终需要解答的,不是未来的画面长什么样,而是哪些物理变化与线索,真正约束并决定了机器躯体当下的行动。
具身智能的进化,正在跨越粗放堆砌海量数据的时代,触及物理智能的更深层本质,从对世界表象的拟合,走向对底层“控制元语”的剥离与顿悟。
这件事才刚刚开始。