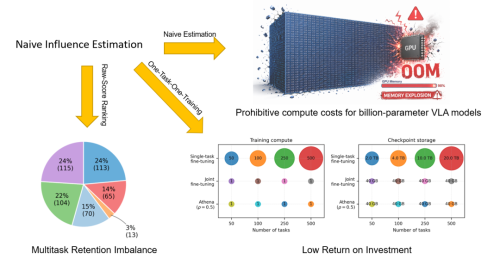
长视界机器人操作,一直是具身智能落地的硬骨头。从双手折叠柔性织物、杂乱场景取放物品,到多步骤精密装配,机器人要走完一整段长流程,最大的拦路虎不是动作控制,而是奖励信号。稀疏奖励给不出有效指引,稠密奖励要靠人工精雕细琢,零样本VLM评估不准还慢,传统方法又卡死在“任务进度必须随时间单调增长”的假设里,一旦遇到回退、纠错、重试这些真实机器人会做的动作,奖励直接乱掉。
整个领域都在死磕“怎么把绝对进度算得更准”,近日逐际动力联合北京邮电大学、浙江大学的研究团队采用了一条全新的设计思路,不算绝对进度,只比相对优势。
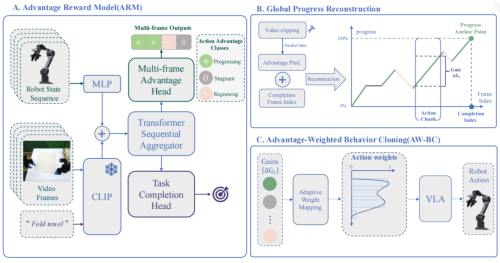
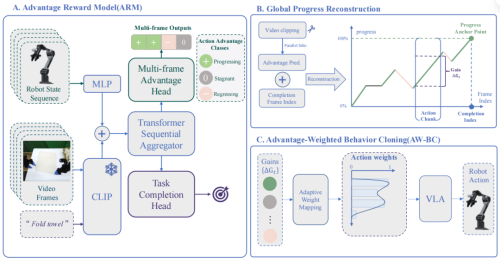
团队提出的框架概述。该系统由三个主要组件构成:(1)基于 MIMO 的时序 Transformer 的优势奖励模型(ARM),采用轻量化三态标注策略进行监督;(2)用于全局进度重建的自动化流水线;(3)优势加权行为克隆(AW-BC)算法,该算法利用从重建进度中提取的长度不变相对增益来优化策略。
团队提出了一套优势奖励建模框架ARM,把复杂的奖励设计变成简单的三态判断,配合MIMO时序Transformer和优势加权行为克隆,在双手长视界毛巾折叠任务上,直接把成功率干到99.4%,把当前主流VLA基线甩在身后。
PART 01
机器人学不会长任务,根本原因在于奖励标错了
VLA视觉-语言-动作模型这两年突飞猛进,机器人能听懂指令、看懂场景、输出动作,但一碰到长流程任务就容易崩。
问题出在学习方式上,主流方法还是靠模仿学习,要堆海量人类演示,数据贵、标注贵,而且人类操作里本来就有瑕疵、冗余、失误,直接学很难收敛到稳定策略。强化学习能自主优化,可奖励信号给不对,一切白搭。
稀疏奖励只有成功和失败,长流程里机器人试错几万次都收不到有效反馈,信用分配完全失效。
大家转而做稠密进度奖励,可麻烦立刻来了,人工标注0到1之间的连续进度数值,主观差异大,标注员耗时长,零样本VLM做进度评估,缺少空间几何对齐,奖励信号来回震荡,子任务分段方式太过粗糙,抓不住阶段内的修正、回退等关键动作,所有方法都默认进度随时间只增不减,和真实机器人行为完全不符,奖励工程,成了卡在长视界机器人操作前的无解瓶颈。
PART 02
换道:不估进度,只判“前进/后退/停滞”
ARM的核心思路,是彻底抛弃对“绝对进度”的执念,转而衡量状态之间的相对优势。
团队设计了一套极简的三态标注规则,不用标数值,不用划分子任务,标注员只需要判断三种状态的变化:+1代表前进,也就是朝着任务目标靠近了,-1代表后退,也就是偏离目标、出错、做了无用功,0代表停滞,也就是没推进任务,处于等待或空动作状态。
这种标注方式几乎没有认知负担,跨标注者一致性极高,既能用在完整演示视频,也能兼容DAgger这类碎片化纠错数据。更重要的是,相对优势不绑定时间单调性,机器人回退、调整、修正这些非单调行为,都能被精准标记,从根源上解决了传统奖励和真实动作错位的问题。
PART 03
MIMO时序Transformer:一次看懂多帧动作变化
传统奖励模型大多是MISO结构,多帧输入只输出一个进度值,时序信息被强行压缩。ARM直接改成MIMO多输入多输出时序Transformer,在因果窗口里并行处理多帧历史观测,一次前向就能输出多段时序的优势分类。
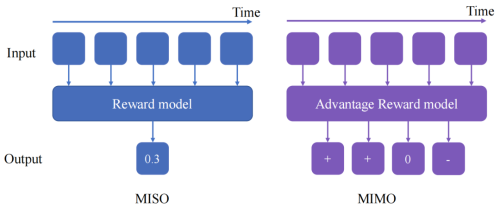
MISO与MIMO架构的对比。MISO代表多输入单输出,MIMO代表多输入多输出。
模型输入融合三类信息,CLIP提取的视觉特征、机器人本体感知状态、任务指令文本,统一投影到隐空间后,经过8层Transformer编码,得到带时序信息的特征表示。

三态标注策略应用于演示片段的示意图
训练用两个头配合,一个头做多帧优势分类,用交叉熵损失监督三态标签,把奖励估计变成分类任务,抗噪声能力大幅提升,另一个头做任务完成预测,用Focal Loss解决终态样本稀少的问题,输出当前帧是否完成任务,作为全局进度的锚点。两个目标一起训,ARM既能抓住帧间细微的状态变化,又能把零散的局部优势,锚定成全局一致的进度信号。
PART 04
全自动进度重建:不用人管,直接出稠密奖励
MIMO架构不只是准,还特别快。传统滑窗推理要反复计算重叠帧,ARM直接把长轨迹切成无重叠片段,单轮前向就能并行处理,冗余计算几乎消失。遇到长度不够窗口的末端片段,就用尾帧复制补齐,最后聚合时丢掉填充部分,保证时序准确。
以任务完成帧为1.0的锚点,顺着模型预测的相对优势往前累加,就能自动生成平滑、高保真的稠密进度曲线。全程不需要人工调参、不需要任务专属规则,原始轨迹进去,高质量奖励信号直接出来。
PART 05
AW-BC:从一堆不完美数据里,炼出最优策略
有了精准奖励,怎么让机器人学得更快更稳?
团队在RA-BC基础上,提出AW-BC优势加权行为克隆。真实演示数据长短不一,直接用会导致梯度忽大忽小,训练不稳定。AW-BC先做长度自适应增益归一化,把不同时长轨迹的进度增益拉到同一尺度,消除长度偏差。
再按批次内的增益分布做统计裁剪,后退、无效的样本权重直接压到接近0,极端高增益样本也做上限约束,避免训练震荡。最终的优化目标,就是最大化加权后的策略对数似然。
ARM在这里相当于一个学习型评论家,不用环境奖励、不用在线交互,只靠离线演示数据,就能把次优轨迹过滤掉,把高效、精准的动作提炼出来。
PART 06
实测:99.4%成功率,标注效率翻20倍
团队选择了业内公认很难的8阶段双手毛巾折叠任务作测试,从杂乱堆里精准抽一条毛巾,接着铺平,再完成两次纵向折叠、两次横向折叠,最后放进收纳盒,120秒内完全入盒才算成功。

长视界毛巾折叠任务概述。该流程包括从杂乱堆中取出一条毛巾、将其放置并铺平在桌面上、执行精确的多阶段折叠策略,以及将折叠好的毛巾运送到目标盒子中。
数据集一共972条轨迹、20小时数据,包含专家演示和纠错样本。先看奖励模型本身,进度重建MSE仅0.0014,远低于SARM的0.0059,成功、失败轨迹识别准确率全部100%,能精准捕捉机器人临时回退的进度凹陷,曲线和真值几乎重合。
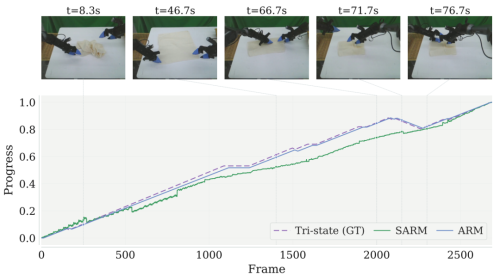
进度重建的定性对比。研究团队针对一个代表性片段,将SARM和ARM的进度曲线与真实值(GT)进行可视化对比。SARM在处理非单调行为时存在困难,而ARM即使在后退调整过程中,也能重建出一条平滑、高保真且与真实值高度贴合的曲线。
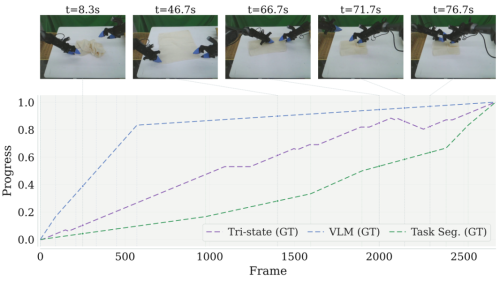
进度重建定性对比。研究团队的三态方法相比人工分段与VLM方法的阶梯式曲线,能够生成更平滑、更一致的稠密进度信号。
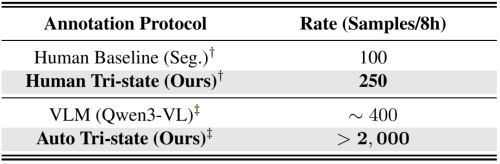
效率方面的表现更夸张,人工三态标注每8小时能标250个样本,是传统子任务分割的2.5倍,自动三态标注单张A100每8小时处理超2000样本,效率提升20倍以上,推理吞吐量14.1 it/s,是VLM的13.7倍、SARM的3.6倍。
落到机器人实际操作层面,标准BC基线成功率62.1%,RA-BC结合SARM的方案成功率78.5%,而AW-BC结合ARM的方案直接达到99.4%,同时任务吞吐量达到32集/小时,折叠精度3.6分,满分5分,全面碾压现有方案。消融实验也证明,三态标注和AW-BC缺一不可,两者配合让成功率直接提升20.9%。

PART 07
结语与未来
这篇研究成果的价值不只是搞定一个毛巾折叠任务这么简单的事情,它把困扰机器人领域多年的奖励工程,从高门槛、高成本、高重复性的手工活,变成低成本、可自动化、可规模化的轻量流程,用相对优势解除了单调假设的枷锁,让奖励信号第一次真正适配真实世界的机器人行为,MIMO架构和全自动重建,让离线奖励学习从实验室走向实用,AW-BC则让VLA模型摆脱对完美专家数据的依赖,脏数据、乱数据也能训出好策略。
当下人形机器人、双臂机器人正从实验室走向工厂、家庭,长视界、高鲁棒、低成本的学习方案,是规模化落地的核心刚需。ARM不依赖任务特定先验,折叠、整理、装配、操作等各类长流程任务都能直接迁移。当机器人不再需要人工精调奖励,就能稳定学会复杂长时序任务,具身智能的落地,才算真正跨过拐点。
该成果将在逐际动力标准化VLA工程底座FluxVLA Engine 开源。
Github地址:https://github.com/FluxVLA/FluxVLA